Context Encoding for Semantic Segmentation
论文发表于2018年的 CVPR。
原文链接:https://arxiv.org/abs/1803.08904
源码链接:https://github.com/zhanghang1989/PyTorch-Encoding
导读与概述#
在这篇文章中研究了CNN特征图的全局上下文信息对于分割的影响,文章提出一个问题,此前的工作中通过增加 CNN 网络层数和感受野或使用膨胀卷积,是否就能更好的提取全局的上下文信息?
对此文章借鉴了channel-wise attention的思路对特征图进行优化,而对于目标分割任务(或者分类任务)提出了基于attention机制的Enc模块,使用attention的方式(编码器不同)增强特征的表达(Context Encoding Module)。
此外对于传统上分割损失存在的偏心眼儿情况(对小目标不是很友好),在Enc模块基础上增加了基于GT像素类别先验监督的SE损失(与分类区域大小无关只与类别相关),进而引导更具表达能力特征的生成。
总的来说,文章的工作如下:
-
文章提出一种与类别预测相关的网络结构,使得在一定程度上降低了分割任务的难度,同时提高了小物体的分割精度。
-
文章提出上下文语义编码模块与类别预测模块,在某种程度上解决或减轻了分割问题中类间样本不均衡的问题。
Introduction#
论文的两个主要贡献:
-
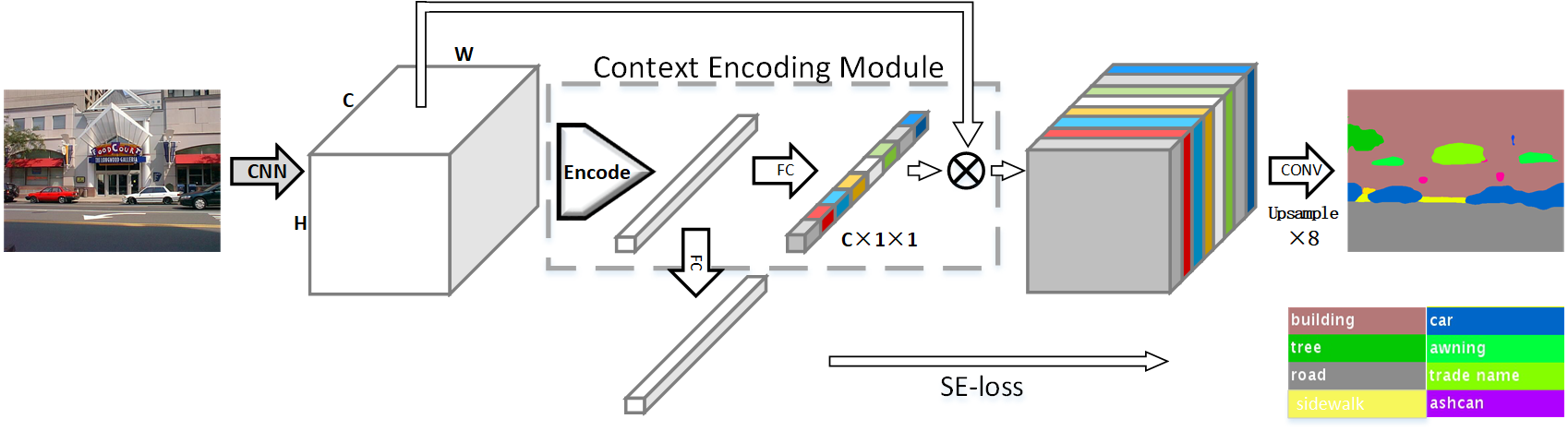
提出了Context Encoding Module。在Context Encoding Module中还包含Semantic Encoding Loss(SE-Loss),一个利用全局场景上下文信息的单元。Context Encoding Module可以捕获场景的语义上下文并选择性地强调与类别相关的特征图。常规的训练过程中只用了逐像素的分割loss,没有充分利用场景的上下文。引入Semantic Encoding Loss(SE-Loss)来正则化训练,让网络预测在某场景中某物体种类出现的概率来加强网络学习语义上下文。而且SE-Loss同等对待大物体和小物体,在实践中发现小物体的实际分割效果有提升。Context Encoding Module方法与现有的FCN方法兼容。
-
设计了一个语义分割网络Context Encoding Network (EncNet)。EncNet在预训练的ResNet中通过引入了Context Encoding Module强化网络。使用了dilation convolution。
Context Encoding Module#



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)