数据获取
数据获取
找什么数据源
- 通常会找一些已经整理好的,常用的数据集,
- 数据要求:
- 小一点的或者中等大小的、太大影响训练速度
- 比较全面的,不同不一样的数据集,多类别,为了全面查看我的超参数在不同数据集的表现
- 如果是非常大的,很深的神经网络,我们需要找非常大的数据集
- 假设我要找的是非常新的方法,我需要收集数据:用传感器之类的,尽量全面采集数据。
常见数据集介绍
- MNIST:手写数据集
- ImageNet:数百万的图片数据集,大部分来自搜索引擎,然后人工标注
- AudioSet:油管上的一些声音的切片
- Kinetics:油管上的一些人的行为的视频的切片
- KITTI:无人驾驶的数据集
- Amazon Review:亚马逊评论数据集
- SQuAD:维基百科上的问题和答案的数据集
- LibriSpeech:1000小时的有声读物
去哪里找数据集
- paperwithcode : 论文+代码实现+整理的数据集
- kaggle数据集:各种数据科学家上传的数据集,质量不一
- 谷歌数据引擎搜集:谷歌搜索引擎爬取的数据集
- 公司组织的竞赛,质量比较高,比较新
- Open Data on AWS:很多大量的原始数据,例如卫星实时采集的数据,基本上P级的大小
- 数据湖,自己公司找
数据集比较
| 分类 | 优点 | 缺点 |
|---|---|---|
| 学术数据集 | 经过大量处理,数据干净、适合ML,难度适中 | 可选择小,选择面小,不太适合做产品 |
| 竞赛数据集 | 更加接近机器学习应用 | 做过数据预处理,太过简化,特定类型 |
| 原始数据集 | 极大的灵活性 | 需要大量的处理 |
数据融合
- 将不同源的数据放到同一个数据集
- 将数据的不同信息分类储存在不同的表中,一张表不可以太复杂,利于更新维护
- 通过keys合并表,但不同表的ID可能对应不上,需要使用类似数据库的左合并,右合并,缺失行可能会丢失,也有可能两个表数值不一样,单位引起的之类的
生成数据集
- 使用GANs

生成人脸;生成居室场景;
-
数据增强:拉伸、旋转等方法扩充数据集

-
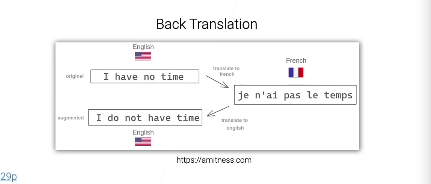
文本翻译:翻译翻译再翻译,不就有了语义差不多,但语法不一样的新文本。(论文写作小妙招?)
总结
- 找到正确的数据是很困难的
- 工业数据和学术数据
- 多源的数据融合
- 收集不到足够的数据,那就数据增强
- GANs等人工合成数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号