【高中数学/三角函数】曲线Sin(x+2y)=2x-y与直线y=x+1到底有几个公共点?
【问题】
求曲线Sin(x+2y)=2x-y与直线y=x+1到底有几个公共点?
【来源】
https://www.douyin.com/discover?modal_id=7495028299702226176
此题为2025年武汉四调第11题
视频主播称曲线和直线有三个交点,但实际是一个。
【解答】
假设曲线和直线有公共点,曲线中点需满足y=x+1
将y=x+1代入Sin(x+2y)=2x-y得Sin(2x+1)=x-1
实际图像如下:
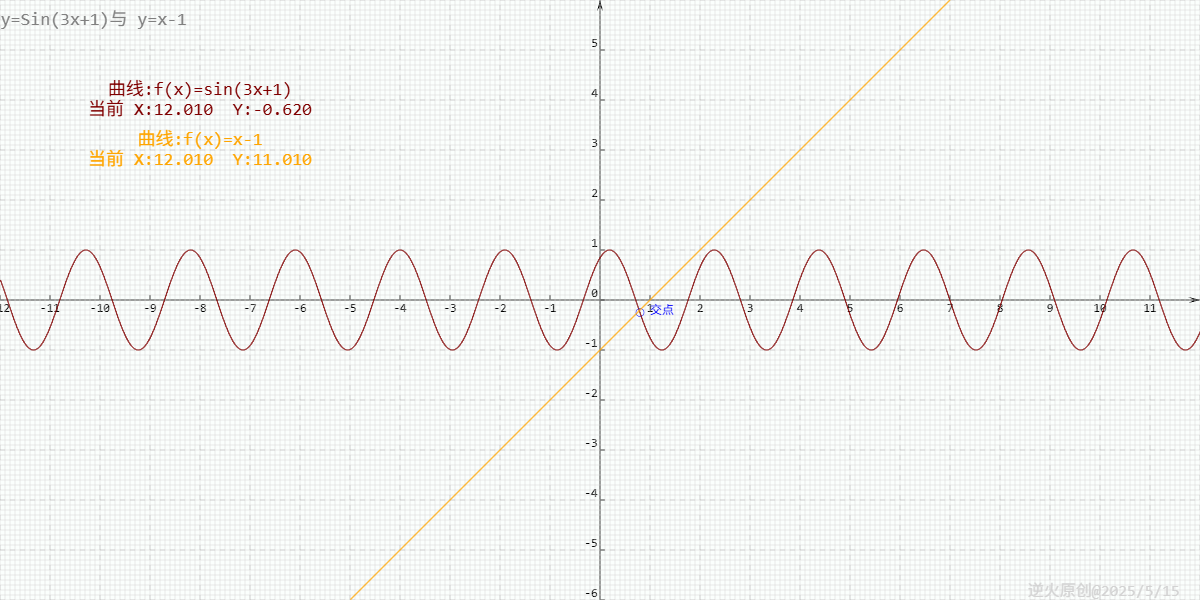
可以发现只有一个交点!
另外为了绘制正弦曲线方便,主播建议让t=3x+1,则x=(t-1)/3,得Sint=t/3-4/3
绘出得图像如下:
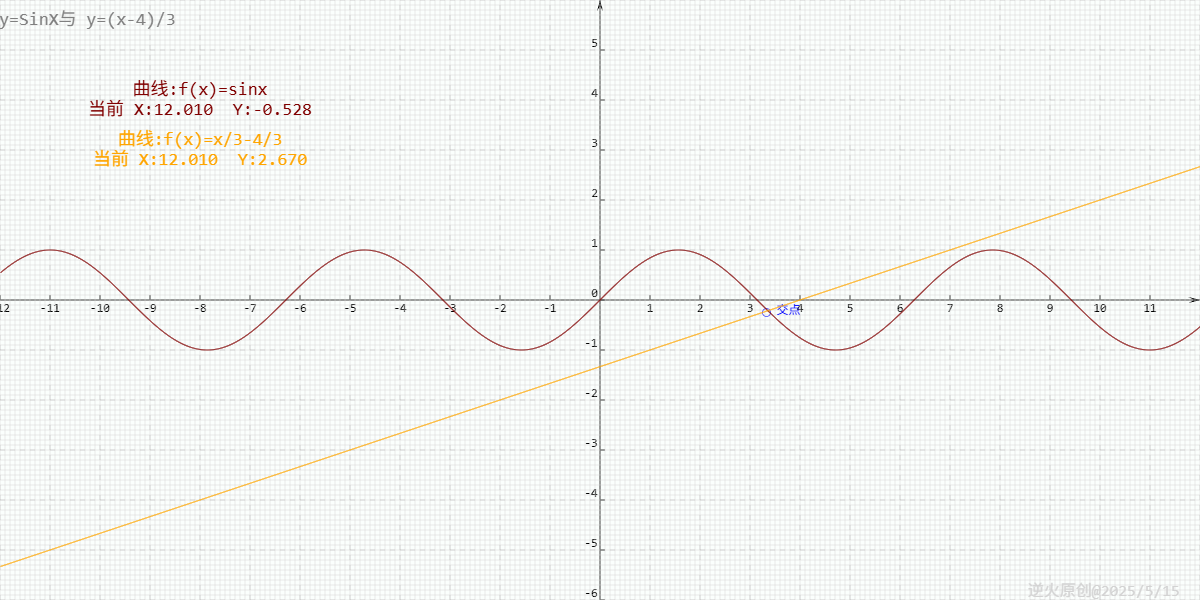
可以发现还是一个交点!
【评】
请出题老师们少放飞自我,连主播这样的专业数学老师手绘图线都绘不准的题就别拿去难为孩子们了!
【绘制第一幅图线的代码】
<!DOCTYPE html> <html lang="utf-8"> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"/> <head> <title>UNASSIGNED</title> <style type="text/css"> .centerlize{ margin:0 auto; border:0px solid red; width:1200px;height:600px; } </style> </head> <body onload="draw();"> <div class="centerlize"> <canvas id="myCanvas" width="10px" height="10px" style="border:1px dashed black;"> 如果看到这段文字说您的浏览器尚不支持HTML5 Canvas,请更换浏览器再试. </canvas> </div> </body> </html> <script type="text/javascript"> <!-- /***************************************************************** * 将全体代码拷贝下来,粘贴到文本编辑器中,另存为.html文件, * 再用chrome浏览器打开,就能看到动画效果。 ******************************************************************/ // 系统常量定义处 const TITLE="y=Sin(3x+1)与 y=x-1"; // 图像标题 const WIDTH=1200; // 画布宽度 const HEIGHT=600; // 画布高度 const SCALE_UNIT=50; // 缩放比例 25对应x∈[-24,24],100对应x∈[-6,6] // 系统变量定义处 var context=0; // 画布环境 var stage; // 舞台对象 var timeElapsed=0; // 动画运作的的时间 const TIME_END=100000; // 动画运作的期限 //------------------------------- // Canvas开始运作,由body_onload调用 //------------------------------- function draw(){ document.title=TITLE; // 画图前初始化 var canvas=document.getElementById('myCanvas'); canvas.width=WIDTH; canvas.height=HEIGHT; context=canvas.getContext('2d'); // 进行屏幕坐标系到笛卡尔坐标系的变换 // 处置完成前,原点在左上角,向右为X正向,向下为Y的正向 // 处置完毕后,原点移动到画布中央,向右为X正向,向上为Y的正向 context.translate(WIDTH/2,HEIGHT/2); context.rotate(Math.PI); context.scale(-1,1); // 初始化舞台 stage=new Stage(); // 开始动画 animate(); }; //------------------------------- // 画图 //------------------------------- function animate(){ timeElapsed+=1;// 时间每轮增加1 stage.update(timeElapsed); stage.paintBg(context); stage.paint(context); if(timeElapsed<TIME_END){ window.requestAnimationFrame(animate); } } //------------------------------- // 舞台对象定义处 //------------------------------- function Stage(){ // 内置对象(非必要勿更改) var obj=new Object; // 对象下的曲线数组(非必要勿更改) obj.curves=[]; // 塞入曲线1(按需修改设定项) obj.curves.push({ name:"曲线:f(x)=sin(3x+1)", xEnd:12, x:-12, y:0, setY:function(x){ this.y=Math.sin(3*x+1);// 解析式 let coord={"x":x,"y":this.y}; this.pts0.push(coord); }, "pts0":[], }); // 塞入曲线2(按需修改设定项) obj.curves.push({ name:"曲线:f(x)=x-1", xEnd:12, x:-12, y:0, setY:function(x){ this.y=x-1;// 解析式 let coord={"x":x,"y":this.y}; this.pts0.push(coord); }, "pts0":[], }); // 随时间更新位置(非必要勿更改) obj.update=function(t){ for(var i=0;i<this.curves.length;i++){ var curve=this.curves[i]; if(curve.x<curve.xEnd){ curve.x+=0.01; curve.setY(curve.x); } } }; // 画前景 obj.paint=function(ctx){ // 手动标记点或线 /*paintPoint(ctx,-1.85,-0.84,"1","blue"); paintPoint(ctx,-0.27,0.84,"2","blue"); paintPoint(ctx,+1.32,-0.84,"3","blue"); paintPoint(ctx,0,Math.sin(Math.PI*5/3),"4","black"); paintLine(ctx,-1.85,-0.84,-0.27,0.84,"green"); paintLine(ctx,-0.27,0.84,+1.32,-0.84,"green"); paintLine(ctx,+1.32,-0.84,-1.85,-0.84,"green");*/ paintPoint(ctx,0.8,-0.25,"交点","blue"); //paintPoint(ctx,+Math.PI/6,0,"PI/6","blue"); ///paintPoint(ctx,+Math.PI*7/12,0,"PI*7/12","blue"); //paintLine(ctx,Math.PI*7/12,2.5,Math.PI*7/12,-2.5,"green"); // 文字左上角位置(可手动修改设定值) const X_START=-400; // 文字横起点 const Y_START=200; // 文字纵起点 const OFFSET=50; // 文字间隔 // 遍历曲线数组(非必要勿更改) for(var i=0;i<this.curves.length;i++){ var curve=this.curves[i];// 曲线对象 var color;// 曲线及文字说明颜色 if(curve.color){ color=curve.color; }else{ color=getColor(i); } // 曲线名称 drawText(ctx,curve.name,X_START,Y_START-i*OFFSET,color,18); // 曲线当前点坐标 drawText(ctx,"当前 X:"+curve.x.toFixed(3)+" Y:"+curve.y.toFixed(3),X_START,Y_START-20-(i)*OFFSET,color,18); // 绘制曲线 if(curve.pts0){ paintCurve(ctx,color,curve.pts0); // 绘制曲线分段1的高低点(可选) var mm=findMaxMin(curve.pts0); //markMaxMin(ctx,mm,color); } if(curve.pts1){ paintCurve(ctx,color,curve.pts1); // 绘制曲线分段2的高低点(可选) //var mm=findMaxMin(curve.pts1); //markMaxMin(ctx,mm,color); } if(curve.pts2){ paintCurve(ctx,color,curve.pts2); // 绘制曲线分段3的高低点(可选) //var mm=findMaxMin(curve.pts2); //markMaxMin(ctx,mm,color); } if(curve.pts3){ paintCurve(ctx,color,curve.pts3); // 绘制曲线分段4的高低点(可选) //var mm=findMaxMin(curve.pts3); //markMaxMin(ctx,mm,color); } if(curve.pts4){ paintCurve(ctx,color,curve.pts4); // 绘制曲线分段4的高低点(可选) //var mm=findMaxMin(curve.pts3); //markMaxMin(ctx,mm,color); } } }; // 画背景(非必要不更改) obj.paintBg=function(ctx){ // 清屏 ctx.clearRect(-600,-300,1200,600); ctx.fillStyle="rgb(251,255,253)"; ctx.fillRect(-600,-300,1200,600); // 画X轴 drawAxisX(ctx,-600,600,50); // 画Y轴 drawAxisY(ctx,-300,300,50); // 画网格线 drawGrid(ctx,-600,-300,50,1200,600,50); // 左上角标题 var metrics = ctx.measureText(TITLE); var textWidth = metrics.width; drawText(ctx,TITLE,-WIDTH/2+textWidth+3,HEIGHT/2-30,"grey",18); // 右下角作者,日期 const waterMarkTxt="逆火原创@"+(new Date()).toLocaleDateString(); metrics = ctx.measureText(waterMarkTxt); textWidth = metrics.width; drawText(ctx,waterMarkTxt,WIDTH/2-textWidth,-HEIGHT/2,"lightGrey",16); }; return obj; } // 描绘并标识一个点(对外函数) function paintLine(ctx,x1,y1,x2,y2,color){ var startx=x1*SCALE_UNIT; var starty=y1*SCALE_UNIT; var endx=x2*SCALE_UNIT; var endy=y2*SCALE_UNIT; ctx.strokeStyle=color; ctx.lineWidth=0.5; // 画线 ctx.beginPath(); ctx.moveTo(startx,starty); ctx.lineTo(endx,endy); ctx.closePath(); ctx.stroke(); } // 描绘并标识一个点(对外函数) function paintPoint(ctx,x,y,text,color){ var xReal=x*SCALE_UNIT; var yReal=y*SCALE_UNIT; ctx.strokeStyle=color; ctx.lineWidth=0.5; // 纵横位置点划线,可人为选择 /*ctx.save(); ctx.setLineDash([5,5]); ctx.beginPath(); ctx.moveTo(xReal,0); ctx.lineTo(xReal,yReal); ctx.lineTo(0,yReal); ctx.stroke(); ctx.restore();*/ // 画圈 ctx.beginPath(); ctx.arc(xReal,yReal,4,0,Math.PI*2,false); ctx.closePath(); ctx.stroke(); // 写文字 var metrics = ctx.measureText(text); var textWidth = metrics.width; drawText(ctx,text,xReal+textWidth+2,yReal-5,color,12); } // 连点成线画曲线 function paintCurve(ctx,color,cds){ ctx.save(); ctx.strokeStyle = color; ctx.lineWidth=1; ctx.beginPath(); for(var i=0; i<cds.length; i++){ let y=cds[i].y; if(Math.abs(cds[i].y*SCALE_UNIT)<300){ ctx.lineTo(cds[i].x*SCALE_UNIT,cds[i].y*SCALE_UNIT); } } ctx.stroke(); ctx.restore(); } // 找到坐标数组的最大最小值 function findMaxMin(cds){ if(cds.length<1){ return null; } var retval={max:-10000,max_x:0,min:10000,min_x:0}; for(var i=0;i<cds.length;i++){ var y=cds[i].y; if(y>retval.max){ retval.max=y; retval.max_x=cds[i].x; } if(y<retval.min){ retval.min=y; retval.min_x=cds[i].x; } } return retval; } // 绘出最大最小值 function markMaxMin(ctx,mm,color){ if(mm==null){ return; } // 最大值 var x=mm.max_x; var y=mm.max; ctx.strokeStyle=color; ctx.beginPath(); ctx.arc(x*SCALE_UNIT,y*SCALE_UNIT,5,0,Math.PI*2,false); ctx.closePath(); ctx.stroke(); var text="max@x="+x.toFixed(3)+" y="+y.toFixed(3); drawText(ctx,text,x*SCALE_UNIT,y*SCALE_UNIT,color,12); // 最小值 var x=mm.min_x; var y=mm.min; ctx.strokeStyle=color; ctx.beginPath(); ctx.arc(x*SCALE_UNIT,y*SCALE_UNIT,5,0,Math.PI*2,false); ctx.closePath(); ctx.stroke(); var text="min@x="+x.toFixed(3)+" y="+y.toFixed(3); drawText(ctx,text,x*SCALE_UNIT,y*SCALE_UNIT,color,12); } // 定点画实心圆 function drawSolidCircle(ctx,x,y,r,color){ ctx.save(); ctx.beginPath(); ctx.arc(x,y,r,0,2*Math.PI); ctx.fillStyle=color; ctx.fill(); ctx.restore(); } // 两点之间画线段 function drawLine(ctx,x1,y1,x2,y2,color){ ctx.save(); ctx.lineWidth=0.25; ctx.strokeStyle=color; ctx.beginPath(); ctx.moveTo(x1,y1); ctx.lineTo(x2,y2); ctx.closePath(); ctx.stroke(); ctx.restore(); } // 画横轴 function drawAxisX(ctx,start,end,step){ ctx.save(); const AXISY_COLOR="black"; ctx.lineWidth=0.5; ctx.strokeStyle=AXISY_COLOR; // 画轴 ctx.beginPath(); ctx.moveTo(start, 0); ctx.lineTo(end, 0); ctx.closePath(); ctx.stroke(); // 画箭头 ctx.fillStyle=AXISY_COLOR; ctx.beginPath(); ctx.moveTo(end-Math.cos(getRad(15))*12, Math.sin(getRad(15))*12); ctx.lineTo(end, 0); ctx.lineTo(end-Math.cos(getRad(15))*12, -Math.sin(getRad(15))*12); ctx.lineTo(end-6, 0); ctx.closePath(); ctx.fill(); // 画刻度 var x,y; y=5; for(x=start;x<end;x+=step){ if(x==0){ continue; } ctx.beginPath(); ctx.moveTo(x, 0); ctx.lineTo(x, y); ctx.closePath(); ctx.stroke(); var text=formatScale(x/SCALE_UNIT); drawText(ctx,text,x,y-20,AXISY_COLOR,12); } ctx.restore(); } // 画纵轴 function drawAxisY(ctx,start,end,step){ ctx.save(); const AXISY_COLOR="black"; ctx.lineWidth=0.5; ctx.strokeStyle=AXISY_COLOR; // 画轴 ctx.beginPath(); ctx.moveTo(0, start); ctx.lineTo(0, end); ctx.closePath(); ctx.stroke(); // 画箭头 ctx.fillStyle=AXISY_COLOR; ctx.beginPath(); ctx.moveTo(Math.sin(getRad(15))*12, end-Math.cos(getRad(15))*12); ctx.lineTo(0, end); ctx.lineTo(-Math.sin(getRad(15))*12, end-Math.cos(getRad(15))*12); ctx.lineTo(0, end-6); ctx.closePath(); ctx.fill(); // 画刻度 var x,y; x=5; for(y=start;y<end;y+=step){ ctx.beginPath(); ctx.moveTo(x, y); ctx.lineTo(0, y); ctx.closePath(); ctx.stroke(); var text=formatScale(y/SCALE_UNIT); var metrics = ctx.measureText(text); var textWidth = metrics.width; drawText(ctx,text,x-textWidth-5,y,AXISY_COLOR,12); } ctx.restore(); } //------------------------------- // 得到整型后的刻度 //------------------------------- function formatScale(scale){ var s=scale*10; if(s % 5==0){ return scale+""; }else{ return scale.toFixed(2); } } // 画网格线 function drawGrid(ctx,x1,y1,step1,x2,y2,step2){ ctx.save(); ctx.lineWidth=0.25; ctx.strokeStyle="lightgrey"; // 分十格 var x,y; for(x=x1;x<x2;x+=step1/10){ ctx.beginPath(); ctx.moveTo(x, y1); ctx.lineTo(x, y2); ctx.closePath(); ctx.stroke(); } for(y=y1;y<y2;y+=step2/10){ ctx.beginPath(); ctx.moveTo(x1, y); ctx.lineTo(x2, y); ctx.closePath(); ctx.stroke(); } // 十小格间的分割线 ctx.lineWidth=0.25; ctx.strokeStyle="grey"; ctx.setLineDash([5,5]);// 设置虚线,起止点间包含五空格五划线共十段 for(x=x1;x<x2;x+=step1){ ctx.beginPath(); ctx.moveTo(x, y1); ctx.lineTo(x, y2); ctx.stroke(); } for(y=y1;y<y2;y+=step2){ ctx.beginPath(); ctx.moveTo(x1, y); ctx.lineTo(x2, y); ctx.stroke(); } ctx.restore(); } //------------------------------- // 角度得到弧度 //------------------------------- function getRad(degree){ return degree/180*Math.PI; } //------------------------------- // 得到颜色 //------------------------------- function getColor(index){ var arr=[ "maroon" /* 栗色 */, "orange" /* 橙色 */, "blue" /* 蓝色 */, "green" /* 绿色 */, "fuchsia"/* 紫红 */, "grey" /* 灰色 */, "lime" /* 酸橙 */, "navy" /* 海蓝 */, "purple" /* 紫色 */, "skyblue"/* 天蓝 */, "teal" /* 蓝绿 */, "yellow" /* 亮黄 */, "aqua" /* 湖绿 */, "red" /* 红色 */, "black" /* 黑色 */, ]; return arr[index % arr.length]; } //------------------------------------- // 绘制文字,指定颜色 // ctx:绘图环境 // text:文字 // x,y:坐标 // color:颜色 // size:字体大小 //------------------------------------- function drawText(ctx,text,x,y,color,size){ ctx.save(); ctx.translate(x,y) ctx.rotate(getRad(180)) ctx.scale(-1,1) ctx.textBaseline="bottom"; ctx.textAlign="center"; ctx.fillStyle=color; ctx.font = size+"px consolas"; ctx.fillText(text,0,0); ctx.restore(); } // JS开立方 function kaiLiFang(x){ if(x>0){ return Math.pow(x,1/3); }else{ return -Math.pow(-x,1/3); } } //--> /********************************************** 苦心人天不负百二秦关终属楚 有志者事竟成三千越甲可吞吴 **********************************************/ </script>
【绘制第二幅图线的代码】
<!DOCTYPE html> <html lang="utf-8"> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"/> <head> <title>UNASSIGNED</title> <style type="text/css"> .centerlize{ margin:0 auto; border:0px solid red; width:1200px;height:600px; } </style> </head> <body onload="draw();"> <div class="centerlize"> <canvas id="myCanvas" width="10px" height="10px" style="border:1px dashed black;"> 如果看到这段文字说您的浏览器尚不支持HTML5 Canvas,请更换浏览器再试. </canvas> </div> </body> </html> <script type="text/javascript"> <!-- /***************************************************************** * 将全体代码拷贝下来,粘贴到文本编辑器中,另存为.html文件, * 再用chrome浏览器打开,就能看到动画效果。 ******************************************************************/ // 系统常量定义处 const TITLE="y=SinX与 y=(x-4)/3"; // 图像标题 const WIDTH=1200; // 画布宽度 const HEIGHT=600; // 画布高度 const SCALE_UNIT=50; // 缩放比例 25对应x∈[-24,24],100对应x∈[-6,6] // 系统变量定义处 var context=0; // 画布环境 var stage; // 舞台对象 var timeElapsed=0; // 动画运作的的时间 const TIME_END=100000; // 动画运作的期限 //------------------------------- // Canvas开始运作,由body_onload调用 //------------------------------- function draw(){ document.title=TITLE; // 画图前初始化 var canvas=document.getElementById('myCanvas'); canvas.width=WIDTH; canvas.height=HEIGHT; context=canvas.getContext('2d'); // 进行屏幕坐标系到笛卡尔坐标系的变换 // 处置完成前,原点在左上角,向右为X正向,向下为Y的正向 // 处置完毕后,原点移动到画布中央,向右为X正向,向上为Y的正向 context.translate(WIDTH/2,HEIGHT/2); context.rotate(Math.PI); context.scale(-1,1); // 初始化舞台 stage=new Stage(); // 开始动画 animate(); }; //------------------------------- // 画图 //------------------------------- function animate(){ timeElapsed+=1;// 时间每轮增加1 stage.update(timeElapsed); stage.paintBg(context); stage.paint(context); if(timeElapsed<TIME_END){ window.requestAnimationFrame(animate); } } //------------------------------- // 舞台对象定义处 //------------------------------- function Stage(){ // 内置对象(非必要勿更改) var obj=new Object; // 对象下的曲线数组(非必要勿更改) obj.curves=[]; // 塞入曲线1(按需修改设定项) obj.curves.push({ name:"曲线:f(x)=sinx", xEnd:12, x:-12, y:0, setY:function(x){ this.y=Math.sin(x);// 解析式 let coord={"x":x,"y":this.y}; this.pts0.push(coord); }, "pts0":[], }); // 塞入曲线2(按需修改设定项) obj.curves.push({ name:"曲线:f(x)=x/3-4/3", xEnd:12, x:-12, y:0, setY:function(x){ this.y=x/3-4/3;// 解析式 let coord={"x":x,"y":this.y}; this.pts0.push(coord); }, "pts0":[], }); // 随时间更新位置(非必要勿更改) obj.update=function(t){ for(var i=0;i<this.curves.length;i++){ var curve=this.curves[i]; if(curve.x<curve.xEnd){ curve.x+=0.01; curve.setY(curve.x); } } }; // 画前景 obj.paint=function(ctx){ // 手动标记点或线 /*paintPoint(ctx,-1.85,-0.84,"1","blue"); paintPoint(ctx,-0.27,0.84,"2","blue"); paintPoint(ctx,+1.32,-0.84,"3","blue"); paintPoint(ctx,0,Math.sin(Math.PI*5/3),"4","black"); paintLine(ctx,-1.85,-0.84,-0.27,0.84,"green"); paintLine(ctx,-0.27,0.84,+1.32,-0.84,"green"); paintLine(ctx,+1.32,-0.84,-1.85,-0.84,"green");*/ paintPoint(ctx,3.33,-0.25,"交点","blue"); //paintPoint(ctx,+Math.PI/6,0,"PI/6","blue"); ///paintPoint(ctx,+Math.PI*7/12,0,"PI*7/12","blue"); //paintLine(ctx,Math.PI*7/12,2.5,Math.PI*7/12,-2.5,"green"); // 文字左上角位置(可手动修改设定值) const X_START=-400; // 文字横起点 const Y_START=200; // 文字纵起点 const OFFSET=50; // 文字间隔 // 遍历曲线数组(非必要勿更改) for(var i=0;i<this.curves.length;i++){ var curve=this.curves[i];// 曲线对象 var color;// 曲线及文字说明颜色 if(curve.color){ color=curve.color; }else{ color=getColor(i); } // 曲线名称 drawText(ctx,curve.name,X_START,Y_START-i*OFFSET,color,18); // 曲线当前点坐标 drawText(ctx,"当前 X:"+curve.x.toFixed(3)+" Y:"+curve.y.toFixed(3),X_START,Y_START-20-(i)*OFFSET,color,18); // 绘制曲线 if(curve.pts0){ paintCurve(ctx,color,curve.pts0); // 绘制曲线分段1的高低点(可选) var mm=findMaxMin(curve.pts0); //markMaxMin(ctx,mm,color); } if(curve.pts1){ paintCurve(ctx,color,curve.pts1); // 绘制曲线分段2的高低点(可选) //var mm=findMaxMin(curve.pts1); //markMaxMin(ctx,mm,color); } if(curve.pts2){ paintCurve(ctx,color,curve.pts2); // 绘制曲线分段3的高低点(可选) //var mm=findMaxMin(curve.pts2); //markMaxMin(ctx,mm,color); } if(curve.pts3){ paintCurve(ctx,color,curve.pts3); // 绘制曲线分段4的高低点(可选) //var mm=findMaxMin(curve.pts3); //markMaxMin(ctx,mm,color); } if(curve.pts4){ paintCurve(ctx,color,curve.pts4); // 绘制曲线分段4的高低点(可选) //var mm=findMaxMin(curve.pts3); //markMaxMin(ctx,mm,color); } } }; // 画背景(非必要不更改) obj.paintBg=function(ctx){ // 清屏 ctx.clearRect(-600,-300,1200,600); ctx.fillStyle="rgb(251,255,253)"; ctx.fillRect(-600,-300,1200,600); // 画X轴 drawAxisX(ctx,-600,600,50); // 画Y轴 drawAxisY(ctx,-300,300,50); // 画网格线 drawGrid(ctx,-600,-300,50,1200,600,50); // 左上角标题 var metrics = ctx.measureText(TITLE); var textWidth = metrics.width; drawText(ctx,TITLE,-WIDTH/2+textWidth+3,HEIGHT/2-30,"grey",18); // 右下角作者,日期 const waterMarkTxt="逆火原创@"+(new Date()).toLocaleDateString(); metrics = ctx.measureText(waterMarkTxt); textWidth = metrics.width; drawText(ctx,waterMarkTxt,WIDTH/2-textWidth,-HEIGHT/2,"lightGrey",16); }; return obj; } // 描绘并标识一个点(对外函数) function paintLine(ctx,x1,y1,x2,y2,color){ var startx=x1*SCALE_UNIT; var starty=y1*SCALE_UNIT; var endx=x2*SCALE_UNIT; var endy=y2*SCALE_UNIT; ctx.strokeStyle=color; ctx.lineWidth=0.5; // 画线 ctx.beginPath(); ctx.moveTo(startx,starty); ctx.lineTo(endx,endy); ctx.closePath(); ctx.stroke(); } // 描绘并标识一个点(对外函数) function paintPoint(ctx,x,y,text,color){ var xReal=x*SCALE_UNIT; var yReal=y*SCALE_UNIT; ctx.strokeStyle=color; ctx.lineWidth=0.5; // 纵横位置点划线,可人为选择 /*ctx.save(); ctx.setLineDash([5,5]); ctx.beginPath(); ctx.moveTo(xReal,0); ctx.lineTo(xReal,yReal); ctx.lineTo(0,yReal); ctx.stroke(); ctx.restore();*/ // 画圈 ctx.beginPath(); ctx.arc(xReal,yReal,4,0,Math.PI*2,false); ctx.closePath(); ctx.stroke(); // 写文字 var metrics = ctx.measureText(text); var textWidth = metrics.width; drawText(ctx,text,xReal+textWidth+2,yReal-5,color,12); } // 连点成线画曲线 function paintCurve(ctx,color,cds){ ctx.save(); ctx.strokeStyle = color; ctx.lineWidth=1; ctx.beginPath(); for(var i=0; i<cds.length; i++){ let y=cds[i].y; if(Math.abs(cds[i].y*SCALE_UNIT)<300){ ctx.lineTo(cds[i].x*SCALE_UNIT,cds[i].y*SCALE_UNIT); } } ctx.stroke(); ctx.restore(); } // 找到坐标数组的最大最小值 function findMaxMin(cds){ if(cds.length<1){ return null; } var retval={max:-10000,max_x:0,min:10000,min_x:0}; for(var i=0;i<cds.length;i++){ var y=cds[i].y; if(y>retval.max){ retval.max=y; retval.max_x=cds[i].x; } if(y<retval.min){ retval.min=y; retval.min_x=cds[i].x; } } return retval; } // 绘出最大最小值 function markMaxMin(ctx,mm,color){ if(mm==null){ return; } // 最大值 var x=mm.max_x; var y=mm.max; ctx.strokeStyle=color; ctx.beginPath(); ctx.arc(x*SCALE_UNIT,y*SCALE_UNIT,5,0,Math.PI*2,false); ctx.closePath(); ctx.stroke(); var text="max@x="+x.toFixed(3)+" y="+y.toFixed(3); drawText(ctx,text,x*SCALE_UNIT,y*SCALE_UNIT,color,12); // 最小值 var x=mm.min_x; var y=mm.min; ctx.strokeStyle=color; ctx.beginPath(); ctx.arc(x*SCALE_UNIT,y*SCALE_UNIT,5,0,Math.PI*2,false); ctx.closePath(); ctx.stroke(); var text="min@x="+x.toFixed(3)+" y="+y.toFixed(3); drawText(ctx,text,x*SCALE_UNIT,y*SCALE_UNIT,color,12); } // 定点画实心圆 function drawSolidCircle(ctx,x,y,r,color){ ctx.save(); ctx.beginPath(); ctx.arc(x,y,r,0,2*Math.PI); ctx.fillStyle=color; ctx.fill(); ctx.restore(); } // 两点之间画线段 function drawLine(ctx,x1,y1,x2,y2,color){ ctx.save(); ctx.lineWidth=0.25; ctx.strokeStyle=color; ctx.beginPath(); ctx.moveTo(x1,y1); ctx.lineTo(x2,y2); ctx.closePath(); ctx.stroke(); ctx.restore(); } // 画横轴 function drawAxisX(ctx,start,end,step){ ctx.save(); const AXISY_COLOR="black"; ctx.lineWidth=0.5; ctx.strokeStyle=AXISY_COLOR; // 画轴 ctx.beginPath(); ctx.moveTo(start, 0); ctx.lineTo(end, 0); ctx.closePath(); ctx.stroke(); // 画箭头 ctx.fillStyle=AXISY_COLOR; ctx.beginPath(); ctx.moveTo(end-Math.cos(getRad(15))*12, Math.sin(getRad(15))*12); ctx.lineTo(end, 0); ctx.lineTo(end-Math.cos(getRad(15))*12, -Math.sin(getRad(15))*12); ctx.lineTo(end-6, 0); ctx.closePath(); ctx.fill(); // 画刻度 var x,y; y=5; for(x=start;x<end;x+=step){ if(x==0){ continue; } ctx.beginPath(); ctx.moveTo(x, 0); ctx.lineTo(x, y); ctx.closePath(); ctx.stroke(); var text=formatScale(x/SCALE_UNIT); drawText(ctx,text,x,y-20,AXISY_COLOR,12); } ctx.restore(); } // 画纵轴 function drawAxisY(ctx,start,end,step){ ctx.save(); const AXISY_COLOR="black"; ctx.lineWidth=0.5; ctx.strokeStyle=AXISY_COLOR; // 画轴 ctx.beginPath(); ctx.moveTo(0, start); ctx.lineTo(0, end); ctx.closePath(); ctx.stroke(); // 画箭头 ctx.fillStyle=AXISY_COLOR; ctx.beginPath(); ctx.moveTo(Math.sin(getRad(15))*12, end-Math.cos(getRad(15))*12); ctx.lineTo(0, end); ctx.lineTo(-Math.sin(getRad(15))*12, end-Math.cos(getRad(15))*12); ctx.lineTo(0, end-6); ctx.closePath(); ctx.fill(); // 画刻度 var x,y; x=5; for(y=start;y<end;y+=step){ ctx.beginPath(); ctx.moveTo(x, y); ctx.lineTo(0, y); ctx.closePath(); ctx.stroke(); var text=formatScale(y/SCALE_UNIT); var metrics = ctx.measureText(text); var textWidth = metrics.width; drawText(ctx,text,x-textWidth-5,y,AXISY_COLOR,12); } ctx.restore(); } //------------------------------- // 得到整型后的刻度 //------------------------------- function formatScale(scale){ var s=scale*10; if(s % 5==0){ return scale+""; }else{ return scale.toFixed(2); } } // 画网格线 function drawGrid(ctx,x1,y1,step1,x2,y2,step2){ ctx.save(); ctx.lineWidth=0.25; ctx.strokeStyle="lightgrey"; // 分十格 var x,y; for(x=x1;x<x2;x+=step1/10){ ctx.beginPath(); ctx.moveTo(x, y1); ctx.lineTo(x, y2); ctx.closePath(); ctx.stroke(); } for(y=y1;y<y2;y+=step2/10){ ctx.beginPath(); ctx.moveTo(x1, y); ctx.lineTo(x2, y); ctx.closePath(); ctx.stroke(); } // 十小格间的分割线 ctx.lineWidth=0.25; ctx.strokeStyle="grey"; ctx.setLineDash([5,5]);// 设置虚线,起止点间包含五空格五划线共十段 for(x=x1;x<x2;x+=step1){ ctx.beginPath(); ctx.moveTo(x, y1); ctx.lineTo(x, y2); ctx.stroke(); } for(y=y1;y<y2;y+=step2){ ctx.beginPath(); ctx.moveTo(x1, y); ctx.lineTo(x2, y); ctx.stroke(); } ctx.restore(); } //------------------------------- // 角度得到弧度 //------------------------------- function getRad(degree){ return degree/180*Math.PI; } //------------------------------- // 得到颜色 //------------------------------- function getColor(index){ var arr=[ "maroon" /* 栗色 */, "orange" /* 橙色 */, "blue" /* 蓝色 */, "green" /* 绿色 */, "fuchsia"/* 紫红 */, "grey" /* 灰色 */, "lime" /* 酸橙 */, "navy" /* 海蓝 */, "purple" /* 紫色 */, "skyblue"/* 天蓝 */, "teal" /* 蓝绿 */, "yellow" /* 亮黄 */, "aqua" /* 湖绿 */, "red" /* 红色 */, "black" /* 黑色 */, ]; return arr[index % arr.length]; } //------------------------------------- // 绘制文字,指定颜色 // ctx:绘图环境 // text:文字 // x,y:坐标 // color:颜色 // size:字体大小 //------------------------------------- function drawText(ctx,text,x,y,color,size){ ctx.save(); ctx.translate(x,y) ctx.rotate(getRad(180)) ctx.scale(-1,1) ctx.textBaseline="bottom"; ctx.textAlign="center"; ctx.fillStyle=color; ctx.font = size+"px consolas"; ctx.fillText(text,0,0); ctx.restore(); } // JS开立方 function kaiLiFang(x){ if(x>0){ return Math.pow(x,1/3); }else{ return -Math.pow(-x,1/3); } } //--> /********************************************** 苦心人天不负百二秦关终属楚 有志者事竟成三千越甲可吞吴 **********************************************/ </script>
END

 浙公网安备 33010602011771号
浙公网安备 33010602011771号