【脱敏迁移】对脱敏迁移程序的优化手段总结
【迁移和脱敏的概念】
下文所说的迁移,是指将A库a表的数据有选择性的移动到B库b表,AB库多数不在一台机器上;而脱敏,是将源表某些字段的数据用一定的方法覆盖掉,再送到目的表的处理。
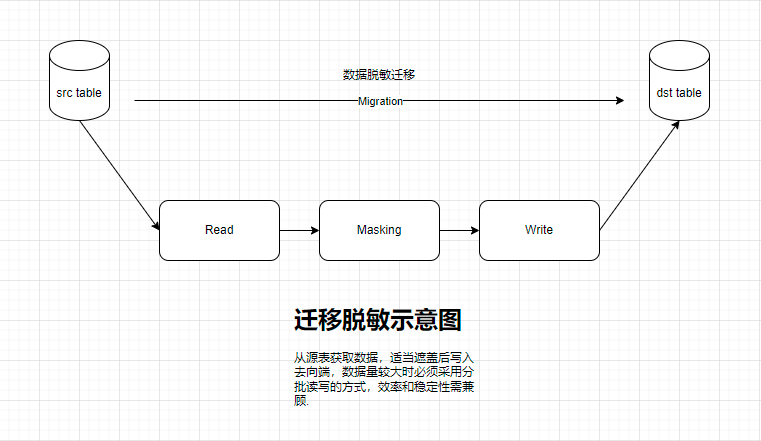
【优化的必要性】
脱敏迁移时,由于表的数据量大小不一,大表传输时的效率会成为左右用户感觉的决定性因素,因此为提高效率而优化,其必要性不言而喻。
【优化前的效率】
优化前,一张含id(number(12)),name(nvarchar2),title(nvarchar2)三个字段50万记录(使用dbms_random生成)的emp表,需要对name字段进行MD5摘要处理,对title字段进行前五位后六位的遮盖,当emp表记录数为50万时,大约30秒左右能脱敏并传输完毕,效率大约是1.6万行每秒。
【立竿见影的优化手段】
笔者采取了不同的措施进行优化,其中感觉比较见效的是:
1.采用单线程读,多线程写的方式:原有方式是单线程读,读到一万条后写入目标端,这种方式的优势在于便于掌控,劣势在于写的时候读线程是等待状态的,虽然写很快,但这份等待的时间是完全可以节省出来的。于是我先采用了读一万条后直接分配线程去写,读线程继续读取的方式,实践中发现收尾的主线程可能先于最后一个分线程完成任务(因为收尾共奏需要处理的数量小于分线程的数据量),后来换用了先精确计算需要的线程个数,赋予一个CountDownLatch的实例,每个线程赋予实例的引用,写完后减一,这样就能让主线程等最后一个线程完成后再进行收尾工作,这就不会产生紊乱。这一步能节省1-3秒的时间。多线程读之所以没采用因为感觉没法下手,因为表形式各异,有无主键,是单主键还是联合主键都是未知数,如果复制一个表拿行号当主键,对大表来说复制就很耗时间,用户机器的剩余空间也未必能撑得住,未知情况多而复杂,因此目前还是采取单线程读的方式。
2.对十种脱敏方法进行LRU缓存处理,以上述emp表为例子,如果对name字段进行MD5摘要,对title字段进行部分遮盖,如果给每种脱敏方法加上LRU缓存,那么可以减少1-3秒的时间,极限情况是50万行记录的name和title字段的内容都一致,那么摘要和遮盖两个方法都只走一次就行了,其它都走缓存,这种情况下耗时仅比完全不脱敏多一点点。总之表中数据相似度越高,LRU的作用就越明显;
3.观察程序需要多次运行的部分,特别观察哪些比较、包含、分支的代码,如果能在对象处理前将需要比对的部分状态化,就增加这个属性,使得循环中尽量减少分支判别的代码。这部分工作比较琐碎,但回报是能感觉出来的。处理后节约时间大约1-2秒。
4.将需要频繁读取写入的数据结构固定大小。原程序中,源表的一行数据是用List存储的,结果集也是用List存储的,向目标端提交时形成的是一个双重动态链表;改进版中,一行数据采取固定大小的String数组,数组长度来自预处理中的Metadata,结果集固定为提交批量大小,向目标端提交后重新new一个出来而不是用List的clear方法。这步举措能将ArrayList扩容的背后环节省却,整体节约时间在1秒之内,提升也是能感觉出来的。
【徒劳无功的优化手段】
感觉不怎么见效的是:
1.成员变量本地化。据说这是优化的有效手段之一,但尝试下发现效率没怎么变化。可能是JVM内部已经做了这样的处理,因此再手工做一边就不见效了,也可能是提升的效率有限,感觉不太出来。个人感觉这么做的好处在于代码简洁些,利索些。
2.循环内定义的变量移出。这个作用也感觉不出来。
3.反射调用脱敏方法改为静态调用,这样做对效率没有提升,反而程序处理变得臃肿了,于是后来又改回了反射方式。
【优化结果】
优化后,原来30秒的任务,可以减到21秒左右,有时能达到20秒,一秒近处理两万五千行数据,比原来提高56%。
时间有限,优化无限,如果您有什么建议,不妨留言告知。
END

 浙公网安备 33010602011771号
浙公网安备 33010602011771号