rank,dense_rank和row_number函数区别
我对技术一般抱有够用就好的态度,一般在网上或者书上找了贴合的解决方案,放到实际中发现好用就行了,不再深究,等出了问题再说。
因此,我对Oracle中中形成有效序列的方法集中在rownum,row_number和rank三种方式,其中rank以简短写法(相对于row_number)和不会加深层次(相对于rownum)成为我的首选。
但是,在一次SQL求中位数方案https://www.cnblogs.com/xiandedanteng/p/12677688.html比较中,我发现有一种方案出不来结果,在排查中发现rank形成的序列恰巧在中值附近形成了空隙,导致查询不出结果,于是当时换用了row_number函数使得结果正常,一查书《精通Oracle SQL》才发现我应该使用形成连续序列的row_number或是dense_rank函数。
三种函数区别如下:
| 名称 | 存在并列时是否会跳过 | 是否确定性函数 | 相同值的处理 |
| rank | 会,因此会在排名里留下空隙 | 是,相同值排名在重复查询中也能保持一致 | 同值同编号,编号可能不连续 |
| dense_rank | 不会,在需要连续排名时该使用它 | 是,重复执行查询也会返回一致的数据 | 同值同编号,编号连续 |
| row_number | 不会,会为结果集中每一行分配唯一编号 | 否,相同值的序列在重复查询中可能会不一致。 | 同值编号顺延,编号连续 |
光是看书很容易略过,上手实操出现疑问再找书解决问题才印象深刻,这就是理论和实践的相互促进。
--2020年4月12日--
光用语言描述不大直观,直接查询结果会更明了。
建表:
create table hy_emp( id number(4,0) primary key, name nvarchar2(20) not null, salary integer not null)
充值:
insert into hy_emp(id,name,salary) values('1','N1','1'); insert into hy_emp(id,name,salary) values('2','N2','2'); insert into hy_emp(id,name,salary) values('3','N3','2'); insert into hy_emp(id,name,salary) values('4','N4','3'); insert into hy_emp(id,name,salary) values('5','N5','3'); insert into hy_emp(id,name,salary) values('6','N6','3'); insert into hy_emp(id,name,salary) values('7','N7','4'); insert into hy_emp(id,name,salary) values('8','N8','5'); insert into hy_emp(id,name,salary) values('9','N9','6'); insert into hy_emp(id,name,salary) values('10','N10','7'); insert into hy_emp(id,name,salary) values('11','N11','8'); insert into hy_emp(id,name,salary) values('12','N12','9');
三种函数效果如下:
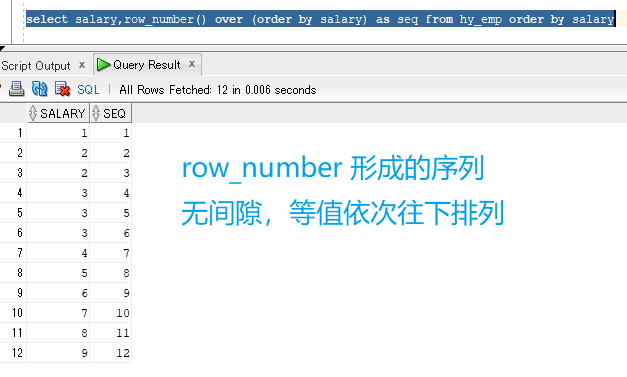
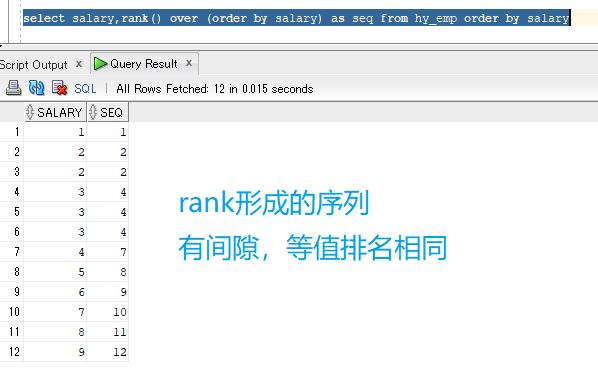

--2020-04-13--

 浙公网安备 33010602011771号
浙公网安备 33010602011771号