[SQL]用于提取组内最新数据,左连接,内连接,not exist三种方案中,到底谁最快?
注意:以下是实例代码,实际代码选择的字段不止order_no和shipper_code两个。
本作代码下载:https://files.cnblogs.com/files/xiandedanteng/LeftInnerNotExist20191222.rar
人们总是喜欢给出或是得到一个简单明了甚至有些粗暴的结论,但现实之复杂往往不是几句简单的话语所能概括的。:)
下结论前,先让我们看一个对比实验。
有一张表delivery_history,表结构如下:
CREATE TABLE delivery_history ( id NUMBER(8,0) not null primary key, name NVARCHAR2(60) not null, order_no NUMBER(10,0) DEFAULT 0 not null , shipper_code NUMBER(10,0) DEFAULT 0 not null , createtime TIMESTAMP (6) not null )
在这张表里,前面两个字段可以忽略,重要的是order_no,shipper_code,createtime三个字段,order_no代表订单号,shipper_code代表运输者代号,createtime是这条记录创建的时间戳,而我们的主要任务是快速找出order_no和shipper_code相同时,createtime最近的那条记录。delivery_history表中目前有五十万条数据,往后可能更多,因此多要对SQL的执行效率多加考虑。(往下的实验中,考虑到在一张表上反复试验太耗时,也不利于数据的存留,表名会加上数字编号后缀,大家知道它们都是delivery_history表的替身就好。)
为此任务,我书写了下面三种SQL:
| 方案一:左连接方案 |
SELECT DH1.ORDER_NO, DH1.SHIPPER_CODE from delivery_history DH1 left JOIN delivery_history DH2 on DH1.SHIPPER_CODE = DH2.SHIPPER_CODE and DH1.ORDER_NO = DH2.ORDER_NO and DH2.createtime > DH1.createtime where DH2.createtime IS NULL
|
| 方案二:groupby内连接方案 |
select DH1.ORDER_NO, DH1.SHIPPER_CODE from delivery_history dh1 , (select SHIPPER_CODE,ORDER_NO,max(createtime) as utime from delivery_history group by SHIPPER_CODE,ORDER_NO) dh2 where dh1.SHIPPER_CODE=dh2.SHIPPER_CODE and dh1.ORDER_NO=dh2.ORDER_NO and dh1.createtime=dh2.createtime
|
| 方案三:not exist方案 |
select a.ORDER_NO, a.SHIPPER_CODE from delivery_history a where not exists( select 1 from delivery_history b where b.SHIPPER_CODE=a.SHIPPER_CODE and b.ORDER_NO=a.ORDER_NO and b.createtime>a.createtime)
|
经过仔细比对,这三种方案均能完成任务,那么哪种速度最快呢?
在给出最终结论之前,让我们来看看数据的情况:
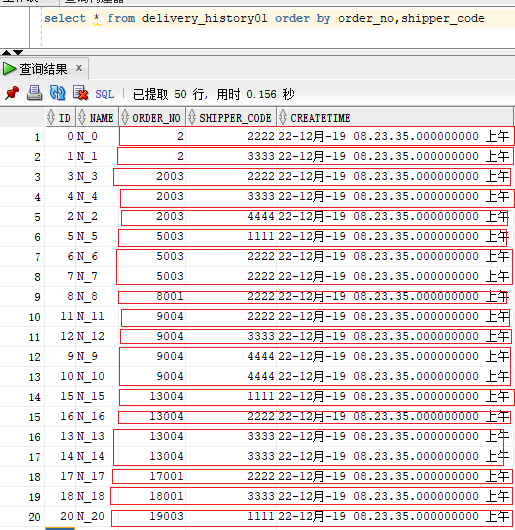
上图中,我已经用红框将数据分组了,可以观察得知,基本上是一条记录对应order_no和shipper_code都相同的一组,跨多条记录的组仅有三组。
对这样的数据,三种方案谁更强呢?
性能测试结果如下:
2019-12-22 08:59:32,334 INFO[main]-Compare query in table'delivery_history01'. 2019-12-22 08:59:37,766 INFO[main]-It takes 5s431ms to run LeftjoinSql and fetch 389755 records. 2019-12-22 08:59:44,414 INFO[main]-It takes 6s648ms to run innerJoinSql and fetch 389755 records. 2019-12-22 08:59:50,625 INFO[main]-It takes 6s211ms to run notExistSql and fetch 389755 records. 2019-12-22 08:59:50,695 INFO[main]-There are same elements in leftMap and innerMap. 2019-12-22 08:59:50,768 INFO[main]-There are same elements in leftMap and notExistMap.
说明一下,deliery_history表中有五十万条数据,分成了389755组,leftMap,innerMap,notExistMap存的都是组内时间最靠近现在的记录。
对比表格如下:
| 左连接 | groupby内连接 | not exist方式 |
| 5s431ms | 6s648ms | 6s211ms |
可以看出,在基本是一条记录对应一组的情况下,左连接胜出。
从这里我们可以得出结论,如果数据分组很小,导致主从表记录数差别不大时,左连接是最快的。
再造一次数据,这回力图减少一条记录对一组的情况:
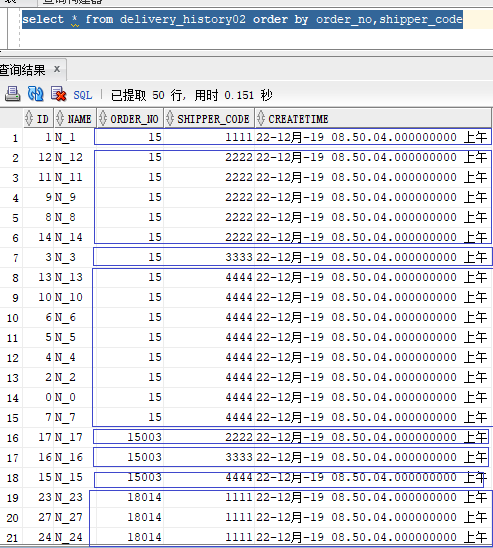
可以看出,包含多条数据的组越来越多了。
再测试一下:
2019-12-22 09:12:58,016 INFO[main]-Compare query in table'delivery_history02'. 2019-12-22 09:13:02,151 INFO[main]-It takes 4s134ms to run LeftjoinSql and fetch 192062 records. 2019-12-22 09:13:05,796 INFO[main]-It takes 3s644ms to run innerJoinSql and fetch 192062 records. 2019-12-22 09:13:09,981 INFO[main]-It takes 4s184ms to run notExistSql and fetch 192062 records. 2019-12-22 09:13:10,028 INFO[main]-There are same elements in leftMap and innerMap. 2019-12-22 09:13:10,072 INFO[main]-There are same elements in leftMap and notExistMap.
这回,五十万条记录分了19万2062组,组内扩大了,分组减少了。
对比表格如下:
| 左连接 | groupby内连接 | not exist |
| 4s134ms | 3s644ms | 4s184ms |
这回的胜出者是内连接方案,它相对另外两种有数百毫秒的优势。
下面我让组内部扩大些,同时分组数就更少了。
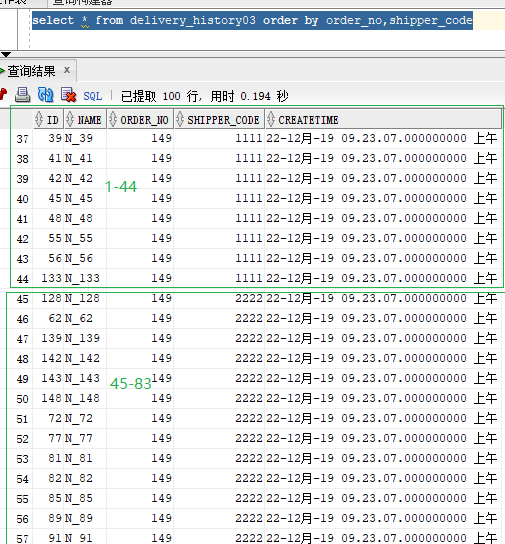
这把1-44条记录为第一组,45-83位第二组,组内扩大很多。
测试结果:
2019-12-22 09:39:46,388 INFO[main]-Compare query in table'delivery_history03'. 2019-12-22 09:39:51,823 INFO[main]-It takes 5s434ms to run LeftjoinSql and fetch 15462 records. 2019-12-22 09:39:54,802 INFO[main]-It takes 2s979ms to run innerJoinSql and fetch 15462 records. 2019-12-22 09:39:59,281 INFO[main]-It takes 4s479ms to run notExistSql and fetch 15462 records. 2019-12-22 09:39:59,288 INFO[main]-There are same elements in leftMap and innerMap. 2019-12-22 09:39:59,294 INFO[main]-There are same elements in leftMap and notExistMap.
这次五十万记录缩成了一万五千四百多组,而内联方案再次胜出,领先优势接近一倍,not exist方案也开始超越左连接。
| 左连接 | groupby内连接 | not exist |
| 5s434ms | 2s979ms | 4s479ms |
此时我们可以推断出,随着组的扩大,内联方案中经过group by后的从表的规模急剧缩小,再与主表连接后结果集就比其它方案数据少,因此而胜出了。
让我们再次扩大组以验证这个理论。

这一把近一百条都归到一组内,结果还会是内联方案胜出吗?
2019-12-22 10:01:47,134 INFO[main]-Compare query in table'delivery_history'. 2019-12-22 10:01:57,325 INFO[main]-It takes 10s190ms to run LeftjoinSql and fetch 4053 records. 2019-12-22 10:01:59,406 INFO[main]-It takes 2s80ms to run innerJoinSql and fetch 4053 records. 2019-12-22 10:02:07,115 INFO[main]-It takes 7s709ms to run notExistSql and fetch 4053 records. 2019-12-22 10:02:07,117 INFO[main]-There are same elements in leftMap and innerMap. 2019-12-22 10:02:07,119 INFO[main]-There are same elements in leftMap and notExistMap.
上面的理论是对的,组越大,group by后的从表就越小,因而形成的结果集就小,内联的领跑优势越来越明显,而not exist方式也与第三名拉开了差距。
| 左连接 | groupby内连接 | not exist |
| 10s190ms | 2s80ms | 7s709ms |
是不是内联就稳了呢?不着急下结论,让我们增加shipper看看。

这种情况下,order_no相同,但shipper不同的情况增加了,组被进一步细化。
测试结果:
2019-12-22 10:04:32,721 INFO[main]-Compare query in table'delivery_history04'. 2019-12-22 10:04:37,466 INFO[main]-It takes 4s744ms to run LeftjoinSql and fetch 34566 records. 2019-12-22 10:04:40,652 INFO[main]-It takes 3s186ms to run innerJoinSql and fetch 34566 records. 2019-12-22 10:04:44,289 INFO[main]-It takes 3s637ms to run notExistSql and fetch 34566 records. 2019-12-22 10:04:44,302 INFO[main]-There are same elements in leftMap and innerMap. 2019-12-22 10:04:44,315 INFO[main]-There are same elements in leftMap and notExistMap.
你可以发现,左连接方案依然落后,但前两名差距不大了。
| 左连接 | groupby内连接 | not exist |
| 4s744ms | 3s186ms | 3s637ms |
我们发现在增加shipper情况下,not exist方案开始跟上了!
我再次增加shipper,终于让notExist方案成为第一名:
2019-12-22 12:24:16,261 INFO[main]-Compare query in table'delivery_history06'. 2019-12-22 12:24:20,432 INFO[main]-It takes 4s169ms to run LeftjoinSql and fetch 90642 records. 2019-12-22 12:24:23,858 INFO[main]-It takes 3s425ms to run innerJoinSql and fetch 90642 records. 2019-12-22 12:24:27,064 INFO[main]-It takes 3s206ms to run notExistSql and fetch 90642 records. 2019-12-22 12:24:27,087 INFO[main]-There are same elements in leftMap and innerMap. 2019-12-22 12:24:27,114 INFO[main]-There are same elements in leftMap and notExistMap.
| 左连接 | groupby内连接 | not exist |
| 4s169ms | 3s425ms | 3s206ms |
再次增加十个shipper,notExist方案优势就出来了:
2019-12-22 12:45:24,403 INFO[main]-Compare query in table'delivery_history07'. 2019-12-22 12:45:28,548 INFO[main]-It takes 4s144ms to run LeftjoinSql and fetch 230475 records. 2019-12-22 12:45:33,163 INFO[main]-It takes 4s615ms to run innerJoinSql and fetch 230475 records. 2019-12-22 12:45:37,157 INFO[main]-It takes 3s994ms to run notExistSql and fetch 230475 records. 2019-12-22 12:45:37,209 INFO[main]-There are same elements in leftMap and innerMap. 2019-12-22 12:45:37,262 INFO[main]-There are same elements in leftMap and notExistMap.
| 左连接 | groupby内连接 | not exist |
| 4s144ms | 4s615ms | 3s994ms |
依照上面的实验,我们可以得出以下结论:
数据零散不成组时,左连接最快;
数据按order_no分组越大,shipper数量不多时,groupby内连接方案最快;
shipper数量越多,not exist方案优势越大。
从这些实验可以看出来,不同的数据,会导致不同的方案胜出;或者说,没有最快的sql方案,只有最适配数据的方案。
没想到吧,SQL优化工作最后成了数据分析工作。
从这个实例可以看出,SQL调优的手段不只是给常查常排序列增加索引或是分表分库,按照数据分布不同而调整到最优实现的查询语句也是手段之一。
以下是用到的代码:
关于建表的代码:
package com.hy; import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.SQLException; import java.sql.Statement; import org.apache.log4j.Logger; // Used to create a table in oracle public class TableCreater { private static Logger log = Logger.getLogger(TableCreater.class); private final String table="delivery_history07"; public boolean createTable() { Connection conn = null; Statement stmt = null; try{ Class.forName(DBParam.Driver).newInstance(); conn = DriverManager.getConnection(DBParam.DbUrl, DBParam.User, DBParam.Pswd); stmt = conn.createStatement(); String createTableSql=getCreateTbSql(table); stmt.execute(createTableSql); if(isTableExist(table,stmt)==true) { log.info("Table:'"+table+"' created."); return true; } } catch (Exception e) { System.out.print(e.getMessage()); } finally { try { stmt.close(); conn.close(); } catch (SQLException e) { System.out.print("Can't close stmt/conn because of " + e.getMessage()); } } return false; } /** * Get a table's ddl * @param table * @return */ private String getCreateTbSql(String table) { StringBuilder sb=new StringBuilder(); sb.append("CREATE TABLE "+table); sb.append("("); sb.append("id NUMBER(8,0) not null primary key,"); sb.append("name NVARCHAR2(60) not null,"); sb.append("order_no NUMBER(10,0) DEFAULT 0 not null ,"); sb.append("shipper_code NUMBER(10,0) DEFAULT 0 not null ,"); sb.append("createtime TIMESTAMP (6) not null"); sb.append(")"); return sb.toString(); } // Execute a sql //private int executeSql(String sql,Statement stmt) throws SQLException { // return stmt.executeUpdate(sql); //} // If a table exists private boolean isTableExist(String table,Statement stmt) throws SQLException { String sql="SELECT COUNT (*) as cnt FROM ALL_TABLES WHERE table_name = UPPER('"+table+"')"; ResultSet rs = stmt.executeQuery(sql); while (rs.next()) { int count = rs.getInt("cnt"); return count==1; } return false; } // Entry point public static void main(String[] args) { TableCreater tc=new TableCreater(); tc.createTable(); } }
用于创建数据的代码:
package com.hy; import java.sql.Connection; import java.sql.DriverManager; import java.sql.SQLException; import java.sql.Statement; import java.text.MessageFormat; import java.util.ArrayList; import java.util.List; import java.util.Random; import org.apache.log4j.Logger; // Used to insert ten thousands of records to table 'delivery_hisotry' public class TableRecordInserter { private static Logger log = Logger.getLogger(TableCreater.class); private final String Table="delivery_history07"; private final int Total=500000; public boolean fillTable() { Connection conn = null; Statement stmt = null; try{ Class.forName(DBParam.Driver).newInstance(); conn = DriverManager.getConnection(DBParam.DbUrl, DBParam.User, DBParam.Pswd); conn.setAutoCommit(false); stmt = conn.createStatement(); long startMs = System.currentTimeMillis(); clearTable(stmt,conn); List<String> insertSqls=generateInsertSqlList(); betachInsert(insertSqls,stmt,conn); long endMs = System.currentTimeMillis(); log.info("It takes "+ms2DHMS(startMs,endMs)+" to fill "+Total+" records."); } catch (Exception e) { e.printStackTrace(); } finally { try { stmt.close(); conn.close(); } catch (SQLException e) { System.out.print("Can't close stmt/conn because of " + e.getMessage()); } } return false; } private void clearTable(Statement stmt,Connection conn) throws SQLException { stmt.executeUpdate("truncate table "+Table); conn.commit(); log.info("Cleared table:'"+Table+"'."); } private int betachInsert(List<String> insertSqls,Statement stmt,Connection conn) throws SQLException { int inserted=0; final int BatchSize=250; int count=insertSqls.size(); int index=0; int times=count/BatchSize; for(int i=0;i<times;i++) { StringBuilder sb=new StringBuilder(); sb.append("INSERT ALL "); for(int j=0;j<BatchSize;j++) { index=i*BatchSize+j; sb.append(insertSqls.get(index)); } sb.append(" select * from dual"); String sql = sb.toString(); int n=stmt.executeUpdate(sql); inserted+=n; conn.commit(); log.info("#"+i+" inserted " +n+" records."); } return inserted; } private List<String> generateInsertSqlList() { List<String> sqlList=new ArrayList<String>(); int index=0; do { int orderNoRange=getRandom(1,100);// 调整order_no,L89 int orderNo=index*1000+orderNoRange; for(int i=0;i<orderNoRange;i++) { int shipper_code=getShipperCode(); String insertSql=getInsertSql(index,orderNo,shipper_code); sqlList.add(insertSql); index++; } }while(index<Total); log.info("generated "+sqlList.size()+" insert sqls."); return sqlList; } // get partial insert sql private String getInsertSql(int id,int orderNo,int shipperCode) { String raw=" INTO {0}(id,name, order_no,shipper_code,createtime) values(''{1}'',''{2}'',''{3}'',''{4}'',sysdate) "; String ids=String.valueOf(id); String name="N_"+ids; Object[] arr={Table,ids,name,String.valueOf(orderNo),String.valueOf(shipperCode)}; return MessageFormat.format(raw, arr); } // get a random shipper-code private int getShipperCode() { int[] arr= {1111,2222,3333,4444,5555,6666,7777,8888,9999,1010,2020,3030,4040,5050,6060,7070,8080,9090,1011,2022,3033,4044,5055,6066,7077,8088,9099,1811,2822,3833,4844,5855,6866,7877,8888,9899};// 调整shipper_code,L120 int seed=getRandom(0,arr.length-1); return arr[seed]; } // get a random integer between min and max public static int getRandom(int min, int max){ Random random = new Random(); int rnd = random.nextInt(max) % (max - min + 1) + min; return rnd; } // change seconds to DayHourMinuteSecond format private static String ms2DHMS(long startMs, long endMs) { String retval = null; long secondCount = (endMs - startMs) / 1000; String ms = (endMs - startMs) % 1000 + "ms"; long days = secondCount / (60 * 60 * 24); long hours = (secondCount % (60 * 60 * 24)) / (60 * 60); long minutes = (secondCount % (60 * 60)) / 60; long seconds = secondCount % 60; if (days > 0) { retval = days + "d" + hours + "h" + minutes + "m" + seconds + "s"; } else if (hours > 0) { retval = hours + "h" + minutes + "m" + seconds + "s"; } else if (minutes > 0) { retval = minutes + "m" + seconds + "s"; } else { retval = seconds + "s"; } return retval + ms; } // Entry point public static void main(String[] args) { TableRecordInserter tri=new TableRecordInserter(); tri.fillTable(); } }
用于比较的代码:
package com.hy; import java.security.MessageDigest; import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.SQLException; import java.sql.Statement; import java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map; import org.apache.log4j.Logger; //Used for hold columns class DhItem { String order_no; String shipper_code; public String toString() { List<String> ls = new ArrayList<String>(); ls.add(order_no); ls.add(shipper_code); return String.join(",", ls); } } public class Comparer { private static Logger log = Logger.getLogger(Comparer.class); private final String Table="delivery_history07"; // print three plan comparison public void printComparison() { Connection conn = null; Statement stmt = null; try { Class.forName(DBParam.Driver).newInstance(); conn = DriverManager.getConnection(DBParam.DbUrl, DBParam.User, DBParam.Pswd); stmt = conn.createStatement(); log.info("Compare query in table'"+Table+"'."); long startMs = System.currentTimeMillis(); Map<String,DhItem> leftMap=fetchMap(getLeftjoinSql(),stmt); long endMs = System.currentTimeMillis(); log.info("It takes "+ms2DHMS(startMs,endMs)+" to run LeftjoinSql and fetch "+leftMap.size()+" records."); startMs = System.currentTimeMillis(); Map<String,DhItem> innerMap=fetchMap(getInnerSql(),stmt); endMs = System.currentTimeMillis(); log.info("It takes "+ms2DHMS(startMs,endMs)+" to run innerJoinSql and fetch "+innerMap.size()+" records."); startMs = System.currentTimeMillis(); Map<String,DhItem> notExistMap=fetchMap(getNotExistSql(),stmt); endMs = System.currentTimeMillis(); log.info("It takes "+ms2DHMS(startMs,endMs)+" to run notExistSql and fetch "+notExistMap.size()+" records."); if(compare(leftMap,innerMap)==true) { log.info("There are same elements in leftMap and innerMap."); } if(compare(leftMap,notExistMap)==true) { log.info("There are same elements in leftMap and notExistMap."); } } catch (Exception e) { e.printStackTrace(); } finally { try { stmt.close(); conn.close(); } catch (SQLException e) { System.out.print("Can't close stmt/conn because of " + e.getMessage()); } } } // Compare the elements in two map private boolean compare(Map<String,DhItem> scrMap,Map<String,DhItem> destMap) { int count=0; for(String key:scrMap.keySet()) { if(destMap.containsKey(key)) { count++; } } return count==scrMap.size() && count==destMap.size(); } private Map<String,DhItem> fetchMap(String sql,Statement stmt) throws SQLException { Map<String,DhItem> map=new HashMap<String,DhItem>(); ResultSet rs = stmt.executeQuery(sql); while (rs.next()) { DhItem dhItem=new DhItem(); dhItem.order_no=rs.getString("order_no"); dhItem.shipper_code=rs.getString("shipper_code"); map.put(toMD5(dhItem.toString()), dhItem); } return map; } // DH表自己和自己进行左连接方案(三种方案都是为了获得ORDER_NO,SHIPPER_CODE相同时创建时间最新的记录) private String getLeftjoinSql() { StringBuilder sb = new StringBuilder(); sb.append(" SELECT "); sb.append(" DH1.ORDER_NO, "); sb.append(" DH1.SHIPPER_CODE "); sb.append(" from "); sb.append(" "+Table+" DH1 "); sb.append(" left JOIN "+Table+" DH2 on "); sb.append(" DH1.SHIPPER_CODE = DH2.SHIPPER_CODE "); sb.append(" and DH1.ORDER_NO = DH2.ORDER_NO "); sb.append(" and DH2.createtime > DH1.createtime "); sb.append(" where DH2.createtime IS NULL "); String sql = sb.toString(); return sql; } // DH表先自己分组方案(三种方案都是为了获得ORDER_NO,SHIPPER_CODE相同时创建时间最新的记录) private String getInnerSql() { StringBuilder sb = new StringBuilder(); sb.append(" select "); sb.append(" DH1.ORDER_NO, "); sb.append(" DH1.SHIPPER_CODE "); sb.append(" from "); sb.append(" "+Table+" dh1 , "); sb.append(" (select SHIPPER_CODE,ORDER_NO,max(createtime) as utime from "+Table+" "); sb.append(" group by SHIPPER_CODE,ORDER_NO) dh2 "); sb.append(" where "); sb.append(" dh1.SHIPPER_CODE=dh2.SHIPPER_CODE and "); sb.append(" dh1.ORDER_NO=dh2.ORDER_NO and "); sb.append(" dh1.createtime=dh2.utime "); String sql = sb.toString(); return sql; } // ‘不存在’最新方案(三种方案都是为了获得ORDER_NO,SHIPPER_CODE相同时创建时间最新的记录) private String getNotExistSql() { StringBuilder sb = new StringBuilder(); sb.append(" select "); sb.append(" a.ORDER_NO, "); sb.append(" a.SHIPPER_CODE "); sb.append(" from "+Table+" a "); sb.append(" where not exists( select 1 "); sb.append(" from "+Table+" b "); sb.append(" where b.SHIPPER_CODE=a.SHIPPER_CODE and "); sb.append(" b.ORDER_NO=a.ORDER_NO and "); sb.append(" b.createtime>a.createtime) "); String sql = sb.toString(); return sql; } /** * change seconds to DayHourMinuteSecond format * * @param startMs * @param endMs * @return */ private static String ms2DHMS(long startMs, long endMs) { String retval = null; long secondCount = (endMs - startMs) / 1000; String ms = (endMs - startMs) % 1000 + "ms"; long days = secondCount / (60 * 60 * 24); long hours = (secondCount % (60 * 60 * 24)) / (60 * 60); long minutes = (secondCount % (60 * 60)) / 60; long seconds = secondCount % 60; if (days > 0) { retval = days + "d" + hours + "h" + minutes + "m" + seconds + "s"; } else if (hours > 0) { retval = hours + "h" + minutes + "m" + seconds + "s"; } else if (minutes > 0) { retval = minutes + "m" + seconds + "s"; } else { retval = seconds + "s"; } return retval + ms; } public static String toMD5(String key) { char hexDigits[] = { '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'A', 'B', 'C', 'D', 'E', 'F' }; try { byte[] btInput = key.getBytes(); // 获得MD5摘要算法的 MessageDigest 对象 MessageDigest mdInst = MessageDigest.getInstance("MD5"); // 使用指定的字节更新摘要 mdInst.update(btInput); // 获得密文 byte[] md = mdInst.digest(); // 把密文转换成十六进制的字符串形式 int j = md.length; char str[] = new char[j * 2]; int k = 0; for (int i = 0; i < j; i++) { byte byte0 = md[i]; str[k++] = hexDigits[byte0 >>> 4 & 0xf]; str[k++] = hexDigits[byte0 & 0xf]; } return new String(str); } catch (Exception e) { return null; } } public static void main(String[] args) { Comparer c = new Comparer(); c.printComparison(); } }
后继文章:https://www.cnblogs.com/heyang78/p/15206050.html
--END--2019年12月22日13:05:12

 浙公网安备 33010602011771号
浙公网安备 33010602011771号