数据库(存储引擎、字段类型、约束条件)
一、存储引擎
现实生活中我们用来存储数据的文件有不同的类型,每种文件类型对应各自不同的处理机制:比如处理文本用txt类型,处理表格用excel,处理图片用png等
数据库中的表也应该有不同的类型,表的类型不同,会对应mysql不同的存取机制,表类型又称为存储引擎。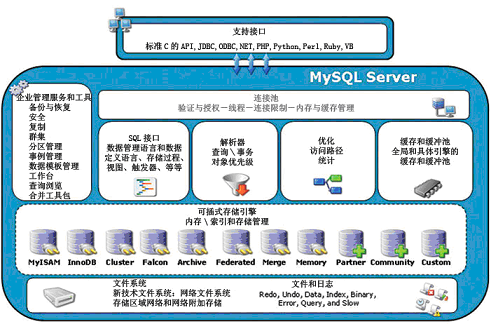
mysql存储引擎类型
show engines; # 查看所有支持的存储引擎
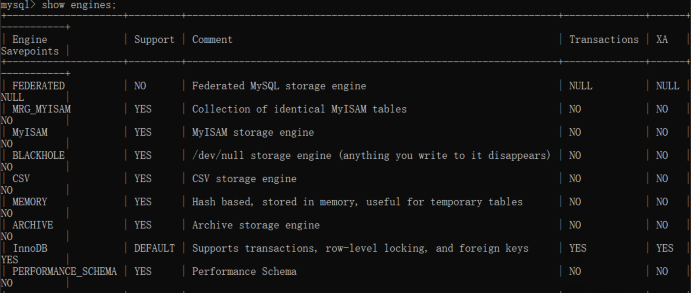
InnoDB 存储引擎
支持事务,其设计目标主要面向联机事务处理(OLTP)的应用。其特点是行锁设计、支持外键,并支持类似 Oracle 的非锁定读,即默认读取操作不会产生锁
MyISAM 存储引擎
不支持事务、表锁设计、支持全文索引,主要面向一些 OLAP 数 据库应用,在 MySQL 5.5.8 版本之前是默认的存储引擎
Memory 存储引擎
Memory 存储引擎中的数据都存放在内存中,数据库重 启或发生崩溃,表中的数据都将消失
BLACKHOLE
黑洞存储引擎,可以应用于主备复制中的分发主库。
创建四个表,分别使用innodb,myisam,memory,blackhole存储引擎
1 create table t1(id int)engine=innodb; 2 create table t2(id int)engine=myisam; 3 create table t3(id int)engine=memory; 4 create table t4(id int)engine=blackhole;
发现后两种存储引擎只有表结构,无数据,
memory,在重启mysql或者重启机器后,表内数据清空
blackhole,往表内插入任何数据,都相当于丢入黑洞,表内永远不存记录
二、字段类型
1.数值类型
整数类型:
tinyint(n):小整数,数据类型用于保存一些范围的整数数值范围
有符号:-128 ~ 127
无符号:0 ~ 255
int(n):整数
有符号: -2147483648 ~ 2147483647
无符号:0 ~ 4294967295
bigint(n):大整数
为该类型指定宽度时,仅仅只是指定查询结果的显示宽度,与存储范围无关,其实我们完全没必要为整数类型指定显示宽度,使用默认的就可以了
浮点类型:
float(m,d):单精度浮点数(非准确小数值),m是数字总个数,d是小数点后个数
m最大值为255,d最大值为30
随着小数的增多,精度变得不准确
double(m,d):双精度浮点数(非准确小数值),m是数字总个数,d是小数点后个数
m最大值为255,d最大值为30
随着小数的增多,精度比float要高,但也会变得不准确
decimal(m,d):准确的小数值,m是数字总个数,d是小数点后个数
m最大值为65,d最大值为30
随着小数的增多,精度始终准确
2.字符串类型
char类型:
定长,简单粗暴,浪费空间,存取速度快
存储:存储char类型的值时,会往右填充空格来满足长度
指定长度为10,存>10个字符则报错,存<10个字符则用空格填充直到凑够10个字符存储
varchar类型:
变长,精准,节省空间,存取速度慢
存储:varchar类型存储数据的真实内容,不会用空格填充
varchar类型会在真实数据前加1-2Bytes的前缀,该前缀用来表示真实数据的bytes字节数
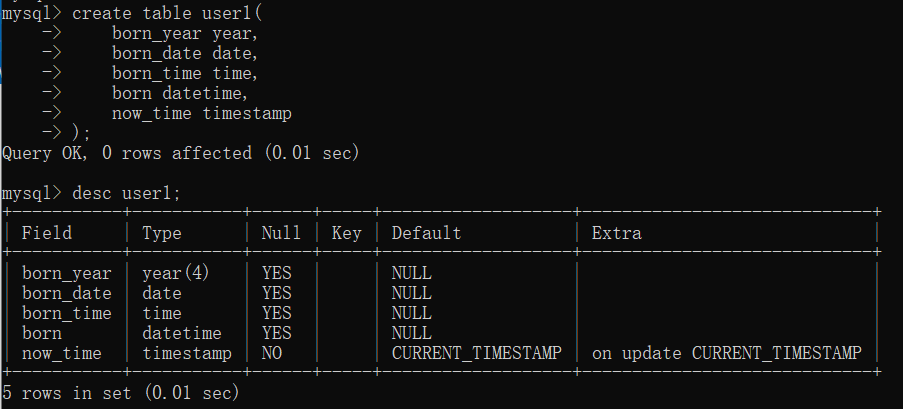
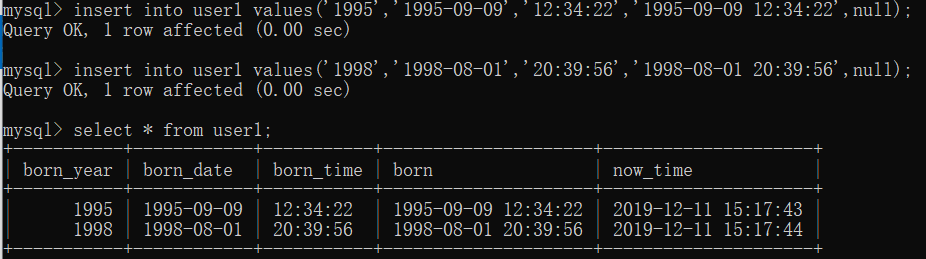
3.日期类型
year:YYYY(2019)
data:YYYY-MM-DD(2019-12-11)
time:HH:MM:SS(15:06:32)
datetime:YYYY-MM-DD HH:MM:SS(2019-12-11 15:06:32)
timestamp:时间戳
注意:单独插入时间时,需要以字符串的形式,按照对应的格式插入
4.枚举与集合
字段的值只能在给定范围中选择,如单选框,多选框
枚举enum:
单选 只能在给定的范围内选一个值,如性别 sex 男male/女female
集合set:
多选 在给定的范围内可以选择一个或一个以上的值(爱好1,爱好2,爱好3...)
三、约束条件
约束条件与数据类型的宽度一样,都是可选参数
作用:用于保证数据的完整性和一致性
1.not null与default
not null表示非空,default后面加默认值
1 create table tb1( 2 nid int not null defalut 2, 3 num int not null 4 ); 5 # nid非空,如果为空,添加默认值2
2.unique:唯一约束条件
============设置唯一约束 UNIQUE=============== 方法一: create table department1( id int, name varchar(20) unique, comment varchar(100) ); 方法二: create table department2( id int, name varchar(20), comment varchar(100), constraint uk_name unique(name) );
联合唯一:两个字段合起来唯一,单独一个可以重复
1 create table service( 2 id int primary key auto_increment, 3 name varchar(20), 4 host varchar(15) not null, 5 port int not null, 6 unique(host,port) #联合唯一 7 );
3.主键primary key
从约束角度看primary key字段的值不为空且唯一
主键primary key是innodb存储引擎组织数据的依据,innodb称之为索引组织表,一张表中必须有且只有一个主键。
单列做主键
1 ============单列做主键=============== 2 #方法一:not null+unique 3 create table department1( 4 id int not null unique, #主键 5 name varchar(20) not null unique, 6 comment varchar(100) 7 ); 8 9 #方法二:在某一个字段后用primary key 10 create table department2( 11 id int primary key, #主键 12 name varchar(20), 13 comment varchar(100) 14 ); 15 16 #方法三:在所有字段后单独定义primary key 17 create table department3( 18 id int, 19 name varchar(20), 20 comment varchar(100), 21 constraint pk_name primary key(id); #创建主键并为其命名pk_name
多列做主键(复合主键)
1 ==================多列做主键================ 2 create table service( 3 ip varchar(15), 4 port char(5), 5 service_name varchar(10) not null, 6 primary key(ip,port) 7 );
4.自动增长auto_increment
约束字段为自动增长,被约束的字段必须同时被key约束
#不指定id,则自动增长 create table student( id int primary key auto_increment, name varchar(20), sex enum('male','female') default 'male' );
不指定id,则自动增长
自增默认从0开始,若想自增从指定值开始,可插入第一条数据时先指定id的值
对于自增的字段,在用delete删除后,再插入值,该字段仍按照删除前的位置继续增长

 浙公网安备 33010602011771号
浙公网安备 33010602011771号