
关键词匹配优化(第2篇)—— 用C#实现demo
上一篇文章用python实现了计算文本相似度计算的过程,这次用C#做个demo。
不得不说用python是真的方便,不懂计算过程也能实现结果。C#也有类似NumPy的库:NumSharp。经过测试还是有区别的,有些功能没有(也可能是因为我没看文档)。最后还是自己研究计算过程去写。
用C#写Excel公式有两种开发方式:VSTO和ExcelDNA。看了一下VSTO的部署感觉比较麻烦,所以这里用ExcelDNA的方式。
求两个词向量的余弦相似度的C#代码如下
/// <summary>
/// 求余弦相似度,输入两个只有1行且列数相同的二维数组
/// </summary>
/// <param name="Vector_a">向量a</param>
/// <param name="Vector_b">向量b</param>
/// <returns>返回两个向量的余弦相似度</returns>
public static double cos_sim(int[,] Vector_a, int[,] Vector_b)
{
double num = 0;
//计算向量a和 向量b转置 的乘积
//python中的:float(vector_a * vector_b.T)
for(int i = 0; i < Vector_a.GetLength(1); i++)
{
num += Vector_a[0, i] * Vector_b[0, i];
}
double denom = norm(Vector_a) * norm(Vector_b);
double sim = num / denom;
return sim;
}
/// <summary>
/// 求向量范数,输入一个只有1行的二维数组
/// </summary>
/// <param name="Vector">输入的向量</param>
/// <returns>返回向量的范数</returns>
//类似NumPy中的np.linalg.norm
public static double norm(int[,] Vector)
{
double SumI = 0;
foreach(int i in Vector)
{
SumI += i * i;
}
return Math.Sqrt(SumI);
}
这个只是初步实现了余弦相似度计算,还有优化的空间。比如这里输入的向量是一行的二维数组,改成用一维数组或者list都可以,类型也可以不用int改成double。
输入的部分先用Excel选区输入,后面会改到数据库中,实现效果如下:
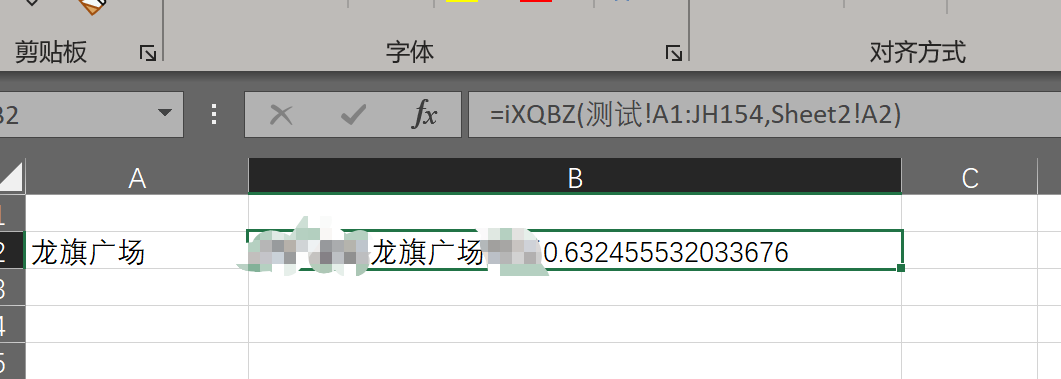
返回的字符串后面跟的数字是两个词的相似度,后续删掉即可。
前面的单元格区域“测试!A1:JH154”是目标关键词和向量,之后会把这部分去掉,整理一下存储到数据库中。按照目前的one-hot编码,后续增加关键词时直接给每个关键词后加一个值是0的维度即可,如果改成tf-idf编码,就需要在增加关键词后重新计算向量了。不过怎么说也比维护100多个elseif要方便,后续优化还可以把拆分字换成分词,减少计算量,提高准确度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号