Mybatis(二)Mapper接口设计和Configuration初始化
Configuration初始化
SqlSessionFactory构建
在 Mybatis 中,每一个应用都是基于 SqlSessionFactory 为核心。SqlSessionFactory 的实例可以通过 SqlSessionFactoryBuilder 获得
而 SqlSessionFactoryBuilder 则可以从 XML 配置文件 或一个 预先配置的 Configuration 实例 来构建出 SqlSessionFactory 实例
XML构建
首先需要配置 xml 配置文件,包含了对 MyBatis 系统的核心设置,包括获取数据库连接实例的数据源(DataSource)以及决定事务作用域和控制方式的事务管理器(TransactionManager)
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="org/mybatis/example/XXXMapper.xml"/>
</mappers>
</configuration>
再使用输入流来读取 配置文件,使用 SqlSessionFactoryBuilder() 根据读取出来的 inputStream 来创建 SqlSessionFactory
String resource = "org/mybatis/example/mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
configuration 构建
在这种情况下,Mybatis 也提供了配置类来直接配置
DataSource dataSource = BlogDataSourceFactory.getBlogDataSource();
TransactionFactory transactionFactory = new JdbcTransactionFactory();
Environment environment = new Environment("development", transactionFactory, dataSource);
Configuration configuration = new Configuration(environment);
configuration.addMapper(BlogMapper.class);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(configuration);
从最后一句开始看,就是调用 SqlSessionFactoryBuilder().build() 来创建一个新的 SqlSessionFactory
/**
* 创建会话工厂后,通过 build 方法去读取配置信息
* @param reader 读取配置文件
* @param environment 环境
* @param properties 属性
* @return 返回配置信息
*/
public SqlSessionFactory build(Reader reader, String environment, Properties properties) {
try {
XMLConfigBuilder parser = new XMLConfigBuilder(reader, environment, properties);
return build(parser.parse());
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error building SqlSession.", e);
} finally {
ErrorContext.instance().reset();
try {
reader.close();
} catch (IOException e) {
// Intentionally ignore. Prefer previous error.
}
}
}
在创建的过程中,调用了 parser.parse(),最后回到 build(parser.parse()),返回一个默认的 SqlSessionFactory
public SqlSessionFactory build(Configuration config) {
return new DefaultSqlSessionFactory(config);
}
在 DefaultSqlSessionFactory 中,就会调用 configuration 配置类,在配置类中就有一个方法 addMapper() ,在这里调用 mapperRegistry.addMapper() 来把 Mapper 加到 mapperRegistry 仓库中注册
public DefaultSqlSessionFactory(Configuration configuration) {
this.configuration = configuration;
}
public <T> void addMapper(Class<T> type) {
mapperRegistry.addMapper(type);
}
在方法中,如果进来的是一个接口(注:这里只能接受传进来的是一个接口,传进来类或者其他直接被忽略,也不报错),再判断是否有这个 Mapper,如果没有,就会 put 进去
public <T> void addMapper(Class<T> type) {
if (type.isInterface()) {
if (hasMapper(type)) {
throw new BindingException("Type " + type + " is already known to the MapperRegistry.");
}
boolean loadCompleted = false;
try {
knownMappers.put(type, new MapperProxyFactory<>(type));
// It's important that the type is added before the parser is run
// otherwise the binding may automatically be attempted by the
// mapper parser. If the type is already known, it won't try.
MapperAnnotationBuilder parser = new MapperAnnotationBuilder(config, type);
parser.parse();
loadCompleted = true;
} finally {
if (!loadCompleted) {
knownMappers.remove(type);
}
}
}
}
XML解析过程
在 build() 方法中,有 XMLConfigBuilder() 这样一个类
public XMLConfigBuilder(InputStream inputStream, String environment, Properties props) {
this(new XPathParser(inputStream, true, props, new XMLMapperEntityResolver()), environment, props);
}
在类里面会调用一个 XPathParser() 的解析类,有着 commonConstructor 这样一个公用的方法,在这个方法里面,进行属性的赋值,其中包括 XPathFactory 中新建一个 factory.newXPath() ,然后生成一个 xpath
private void commonConstructor(boolean validation, Properties variables, EntityResolver entityResolver) {
this.validation = validation;
this.entityResolver = entityResolver;
this.variables = variables;
XPathFactory factory = XPathFactory.newInstance();
this.xpath = factory.newXPath();
}
然后到创建一个 Document,createDocument() 就会调用输入流 InputSource 来读取配置文件,而 InputSource 是 XML 实体的单体输入源,然后包装放进 Document 中

在 Document 中,factory 设置参数来生成 DocumentBuilder ,在 createDocument() 这个方法中,都是 jdk 自身方法调用,没有涉及到 Mybatis 的源码
private Document createDocument(InputSource inputSource) {
// important: this must only be called AFTER common constructor
try {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
factory.setFeature(XMLConstants.FEATURE_SECURE_PROCESSING, true);
factory.setValidating(validation);
factory.setNamespaceAware(false);
factory.setIgnoringComments(true);
factory.setIgnoringElementContentWhitespace(false);
factory.setCoalescing(false);
factory.setExpandEntityReferences(true);
DocumentBuilder builder = factory.newDocumentBuilder();
builder.setEntityResolver(entityResolver);
builder.setErrorHandler(new ErrorHandler() {
@Override
public void error(SAXParseException exception) throws SAXException {
throw exception;
}
@Override
public void fatalError(SAXParseException exception) throws SAXException {
throw exception;
}
@Override
public void warning(SAXParseException exception) throws SAXException {
// NOP
}
});
return builder.parse(inputSource);
} catch (Exception e) {
throw new BuilderException("Error creating document instance. Cause: " + e, e);
}
}
创建生成的 Document,其实就是配置树,在这个 document 中,需要将配置信息提取出来
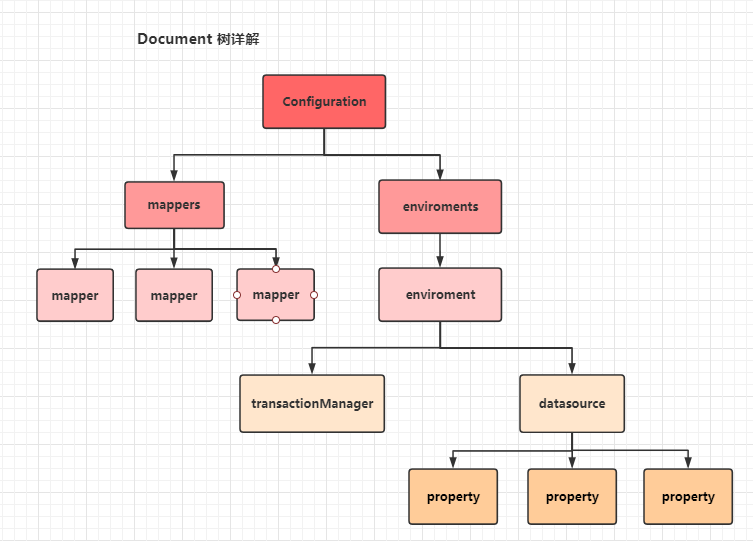
回到 SqlSessionFactory 的 build 方法中,分析 parser.parse() 的解析过程
public SqlSessionFactory build(InputStream inputStream, String environment, Properties properties) {
try {
XMLConfigBuilder parser = new XMLConfigBuilder(inputStream, environment, properties);
return build(parser.parse());
.....
}
}
继续调用 parse() 方法中,调用了 parseConfiguration(),在这个方法中,就会重头开始配对参数开始解析,例如在列出的 xml 配置中,是由 environments 开始的,此时这个节点就变成主节点,被 XNode 的 evalNode() 存起来
public Configuration parse() {
if (parsed) {
throw new BuilderException("Each XMLConfigBuilder can only be used once.");
}
parsed = true;
// 读到结束标签返回
parseConfiguration(parser.evalNode("/configuration"));
return configuration;
}
private void parseConfiguration(XNode root) {
try {
// issue #117 read properties first
propertiesElement(root.evalNode("properties"));
Properties settings = settingsAsProperties(root.evalNode("settings"));
loadCustomVfs(settings);
loadCustomLogImpl(settings);
typeAliasesElement(root.evalNode("typeAliases"));
pluginElement(root.evalNode("plugins"));
objectFactoryElement(root.evalNode("objectFactory"));
objectWrapperFactoryElement(root.evalNode("objectWrapperFactory"));
reflectorFactoryElement(root.evalNode("reflectorFactory"));
settingsElement(settings);
// read it after objectFactory and objectWrapperFactory issue #631
environmentsElement(root.evalNode("environments"));
databaseIdProviderElement(root.evalNode("databaseIdProvider"));
typeHandlerElement(root.evalNode("typeHandlers"));
mapperElement(root.evalNode("mappers"));
} catch (Exception e) {
throw new BuilderException("Error parsing SQL Mapper Configuration. Cause: " + e, e);
}
}
继续被下级方法调用,Configuration 的下级就是mappers和enviroments ,在这里继续被 environmentsElement()调用到下一个节点
在方法中进行获取子节点如果 environment 为空,就会在 context 中取出一个默认值,如果 **environment 不为空,进行继续调用,就会调用事务 transactionManagerElement(),数据源 dataSourceElement() **等,在此就对应了上面的 Document 树的解析图
private void environmentsElement(XNode context) throws Exception {
if (context != null) {
if (environment == null) {
environment = context.getStringAttribute("default");
}
for (XNode child : context.getChildren()) {
String id = child.getStringAttribute("id");
if (isSpecifiedEnvironment(id)) {
TransactionFactory txFactory = transactionManagerElement(child.evalNode("transactionManager"));
DataSourceFactory dsFactory = dataSourceElement(child.evalNode("dataSource"));
DataSource dataSource = dsFactory.getDataSource();
Environment.Builder environmentBuilder = new Environment.Builder(id)
.transactionFactory(txFactory)
.dataSource(dataSource);
configuration.setEnvironment(environmentBuilder.build());
}
}
}
}
Mapper 接口设计
在 Mapper 和 Spring 整合中,会看到配置文件都是要写明 mapper 配置文件路径,内部原理实现来进行解析
简单实现 Spring 和 Mapper 接口之间如何进行对接
public class MapperInterfaceEnhance {
@Data
static class MapperScanner {
private String mapperLocation;
/**
* TODO Mapper 扫描过程
* @return 返回包扫描
*/
public List<Class<?>> scanMapper(){
return Lists.newArrayList();
}
}
public static void main(String[] args) {
String mapperLocation = "classpath:mapper/*.xml";
MapperScanner mapperScanner = new MapperScanner();
mapperScanner.setMapperLocation(mapperLocation);
List<Class<?>> classes = mapperScanner.scanMapper();
Configuration configuration = new Configuration();
/*
* 多线程遍历输入
*/
classes
.parallelStream()
.forEach(configuration::addMapper);
}
}
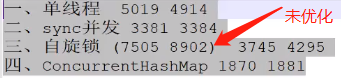
在单线程往里面添加的时候,需要的是 HashMap(),而在多线程添加时,这时需要的是** ConcurrentHashMap()**
在高并发和多线程的情况下,HashMap 是线程不安全的,在并发环境下可能会形成环状链表(在扩容时造成),导致get操作时,cpu空转,所以,在并发环境中使用HashMap是非常危险的,而 ConcurrentHashMap所采用的"分段锁"思想,容器中有多把锁,每一把锁锁一段数据,这样在多线程访问时不同段的数据时,就不会存在锁竞争了,这样便可以有效地提高并发效率
public class MapperInterfaceEnhance {
private static Map<Class<?>, Object> objectMap = Maps.newHashMap();
@Data
static class MapperScanner {
private String mapperLocation;
List<Class<?>> scanMapper() {
List<Class<?>> objects = Lists.newArrayList();
for (int i = 0; i < 1000000; i++) {
objects.add(MapperInterfaceEnhance.class);
}
return objects;
}
}
public static void main(String[] args) {
String mapperLocation = "classpath:mapper/*.xml";
MapperScanner mapperScanner = new MapperScanner();
mapperScanner.setMapperLocation(mapperLocation);
List<Class<?>> classes = mapperScanner.scanMapper();
long start = System.currentTimeMillis();
classes
.forEach(clazz -> objectMap.put(clazz,new Object()));
long end = System.currentTimeMillis();
System.out.println(end - start);
}
}
在多线程去竞争锁的时候开销在 上下文切换,并且需要扩容,消耗的资源和时间就会变多,所以在这里要把容量设定好
如果把锁升级为自旋锁,消耗的时间会不会更少
由于当前的 Class 类是固定,这里就造成在同一个槽中,编译的速度不会造成很大影响,进行改进将其换成 Object 来打散,再进行测试
public class MapperInterfaceEnhance {
private static int size = 1000000;
private static Map<Object, Object> objectMap = new HashMap<>(size);
@Data
static class MapperScanner {
private String mapperLocation;
List<Object> scanMapper() {
List<Object> objects = Lists.newArrayList();
for (int i = 0; i < size; i++) {
objects.add(new Object());
}
return objects;
}
}
public static void put(Object obj) {
objectMap.put(obj, obj);
}
public static void main(String[] args) {
String mapperLocation = "classpath:mapper/*.xml";
MapperScanner mapperScanner = new MapperScanner();
mapperScanner.setMapperLocation(mapperLocation);
List<Object> objects = mapperScanner.scanMapper();
long start = System.currentTimeMillis();
objects
.parallelStream()
.forEach(MapperInterfaceEnhance::put);
long end = System.currentTimeMillis();
System.out.println(end - start);
}
}
自定义自旋锁
自旋锁的定义
是指当一个线程在获取锁的时候,如果锁已经被其它线程获取,那么该线程将循环等待,然后不断的判断锁是否能够被成功获取,直到获取到锁才会退出循环
自旋锁不会使线程状态发生切换,一直处于用户态,即线程一直都是active的;不会使线程进入阻塞状态,减少了不必要的上下文切换,执行速度快
自旋锁存在的问题
如果某个线程持有锁的时间过长,就会导致其它等待获取锁的线程进入循环等待,消耗CPU。使用不当会造成CPU使用率极高。
上面Java实现的自旋锁不是公平的,即无法满足等待时间最长的线程优先获取锁。不公平的锁就会存在“线程饥饿”问题。
public class NickLock {
private static final Unsafe unsafe;
private static final long valueOffset;
static {
try {
Class<Unsafe> unsafeClass = Unsafe.class;
Field theUnsafe = unsafeClass.getDeclaredField("theUnsafe");
theUnsafe.setAccessible(true);
unsafe = (Unsafe) theUnsafe.get(null);
valueOffset = unsafe.objectFieldOffset
(AtomicInteger.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
private volatile int value;
public static void main(String[] args) {
System.out.println(unsafe);
}
}
自旋锁线程优化
在上面的自旋锁中,通过 unsafe 已经拿到了 value值,而且有了偏移值 valueOffset,就要将 value 值通过CAS算法实现原子性自增,比较当前对象和偏移值之间的差别,如果合适就把value返回
void lock() {
for (; ; ) {
if (unsafe.compareAndSwapInt(this, valueOffset, 0, 1)) {
return;
}
// 线程让步
Thread.yield();
}
}
通过测试可以看出来,ConcurrentHashMap 并不是自旋锁,底层而是由分段锁来实现,所以相对于其他来说,执行速度会快很多
