

kubeadm构建k8s之Prometheus-operated监控(0.18.1)
介绍:
大家好,k8s的搭建有许多方式,也有许多快速部署的,为了简化部署的复杂度,官方也提供了开源的kubeadm快速部署,最新1.10.x版本已经可以实现部署集群,
如果你对k8s的原理已经非常了解,不妨可以试试,今天将为大家说说如何去快速搭建一个监控系统到展示页面,报警规则会在下一章讲解,那么Prometheus-operated是什么,用过的朋友应该知道
Prometheus是用来收集数据的,同时本身也提供强大的查询能力,结合Grafana,就可以监控到你想要的数据。
获取数据的原理大家可以去百度一下,具体就是你的采集工具可以任意用编程语言来写,最后只要提供一个http或者https的访问地址,比如我想监控nginx,地址是192.168.1.1 端口8080,
那么我要采集nginx的数据就是 http://192.168.1.1/metrics,前提是metrics模块已经加载,nginx已内置了这个模块,具体请百度,如果没有怎么办,自己写或者去官方找模板。
那么在k8s上,prometheus该如何去监控我们的数据呢,用过k8s的人应该知道service,没错,k8s会读取service的后端地址,拿到容器的IP地址然后去主动请求采集数据,而k8s自身的数据呢,同样的道理,k8s已经集成了metrics功能,所以,我们只需要请求组件所对应的IP:PORT/metrics 就能拿到数据,这样k8s集群包括自身的监控数据全都拿到了,怎么方便的操作如果只单靠Prometheus是不可能完成的,这时候Prometheus-operated就面世了,其主要就是提供自动发现功能,如果你使用过K8S日志采集ELK(阿里云的日志采集开源项目),其原理是一样的,动态获取k8s的信息,出现了新增或者减少的服务,他会讲相关的配置写入Prometheus当中,然后动态加载,否则你就要一个一个的去配置。
项目地址:https://github.com/coreos/prometheus-operator
官网地址: https://prometheus.io
话不多说,30秒让你的监控跑起来。
kubeadm部署
这里我节约时间,就不一一介绍了,因为config.yml需要指定参数,这里我会在部署prometheus-operator说明
prometheus-operator部署
首先就是kubeadm的配置文件 ,如果你是直接从kubeadm开始弄,可以提前写进去,这样一会你就不需要在修改了
和你自己的比较一下缺少了哪些添加上去即可,如果已经安装了也没关系,我们手动去改,后面也讲
#所有master机器
apiVersion: kubeadm.k8s.io/v1alpha1 kind: MasterConfiguration api: advertiseAddress: 192.168.1.173 bindPort: 6443 authorizationModes: - Node - RBAC certificatesDir: /etc/kubernetes/pki cloudProvider: etcd: dataDir: /var/lib/etcd endpoints: null imageRepository: gcr.io/google_containers kubernetesVersion: v1.8.3 networking: dnsDomain: cluster.local serviceSubnet: 10.96.0.0/12 nodeName: your-dev tokenTTL: 24h0m0s controllerManagerExtraArgs: address: 0.0.0.0 schedulerExtraArgs: address: 0.0.0.0
手动修改所有master机器都要执行,node节点只需要修改和kubelet相关的,
如果你kubeadm还没有开始部署下面的操作只需要执行kubelet的操作
sed -e "s/- --address=127.0.0.1/- --address=0.0.0.0/" -i /etc/kubernetes/manifests/kube-controller-manager.yaml
sed -e "s/- --address=127.0.0.1/- --address=0.0.0.0/" -i /etc/kubernetes/manifests/kube-scheduler.yaml
KUBEADM_SYSTEMD_CONF=/etc/systemd/system/kubelet.service.d/10-kubeadm.conf
sed -e "/cadvisor-port=0/d" -i "$KUBEADM_SYSTEMD_CONF"
if ! grep -q "authentication-token-webhook=true" "$KUBEADM_SYSTEMD_CONF"; then
sed -e "s/--authorization-mode=Webhook/--authentication-token-webhook=true --authorization-mode=Webhook/" -i "$KUBEADM_SYSTEMD_CONF"
fi
systemctl daemon-reload
systemctl restart kubelet
下载官方提供的源码,版本(我的是0.18.1)
git clone -b v0.18.1 https://github.com/coreos/prometheus-operator

cd prometheus-operator/contrib/kube-prometheus
./hack/cluster-monitoring/deploy
好了,已经部署成功了,看看服务(首次启动会下载需要镜像,过程看个人网络,国内是可以访问的因为部署谷歌的镜像地址)
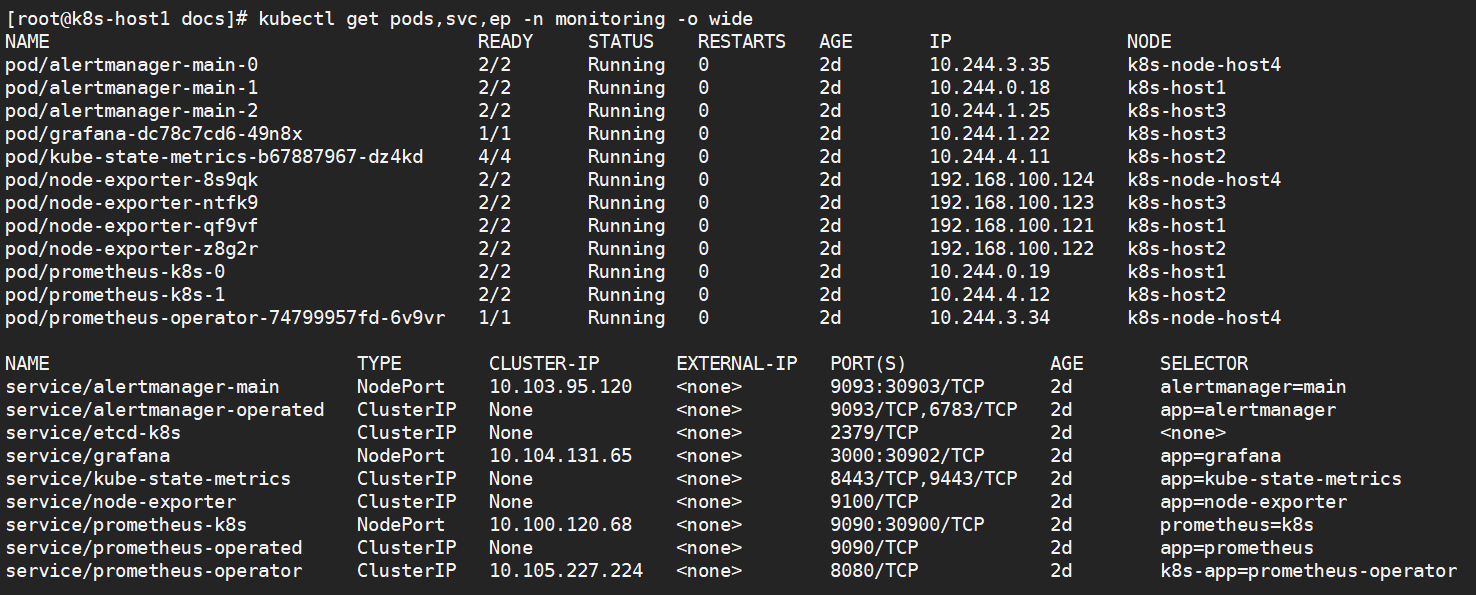
服务器全部起来了
脚本开放3个NodePort端口
分别是
30903:报警服务
30902:grafana服务
30900:promethues服务
让我们去看看是否都能监控,访问ip(master地址):30900
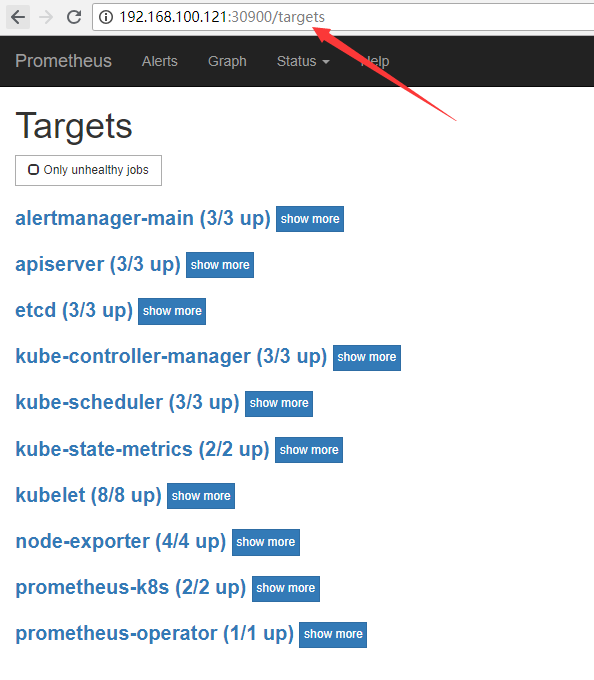
全部都为up,说明都起来了,刚安装好的是没有etcd的,需要自己创建yaml文件,具体可以参考下面的文档
http://www.mamicode.com/info-detail-2251383.html 非常详细
最后让我们看看数据是否都收集到了grafana
访问grafana地址
http://192.168.100.124:30902 默认账号admin/admin 如果是生产建议修改密码
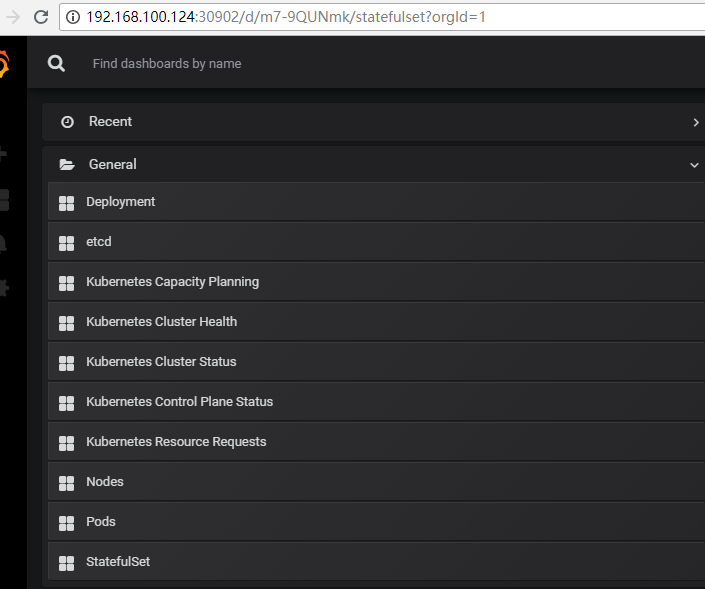
可以看到Prometheus-operated的作者们已经提供了一套基础的数据模板给我们了,当然也可以根据实际情况来作出修改
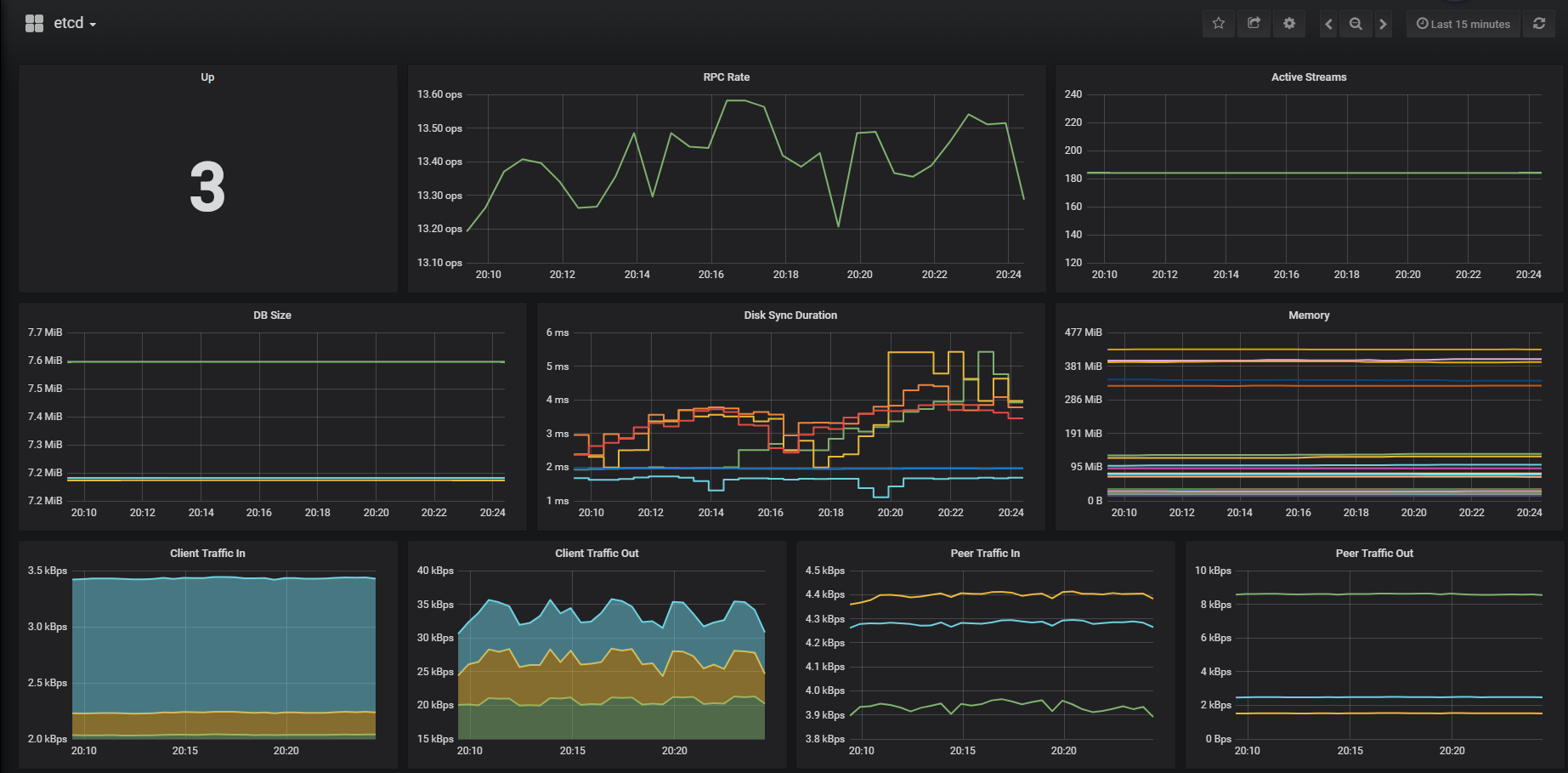
etcd的数据全部已获取到
我们知道k8s有3种部署方式,也能监控到
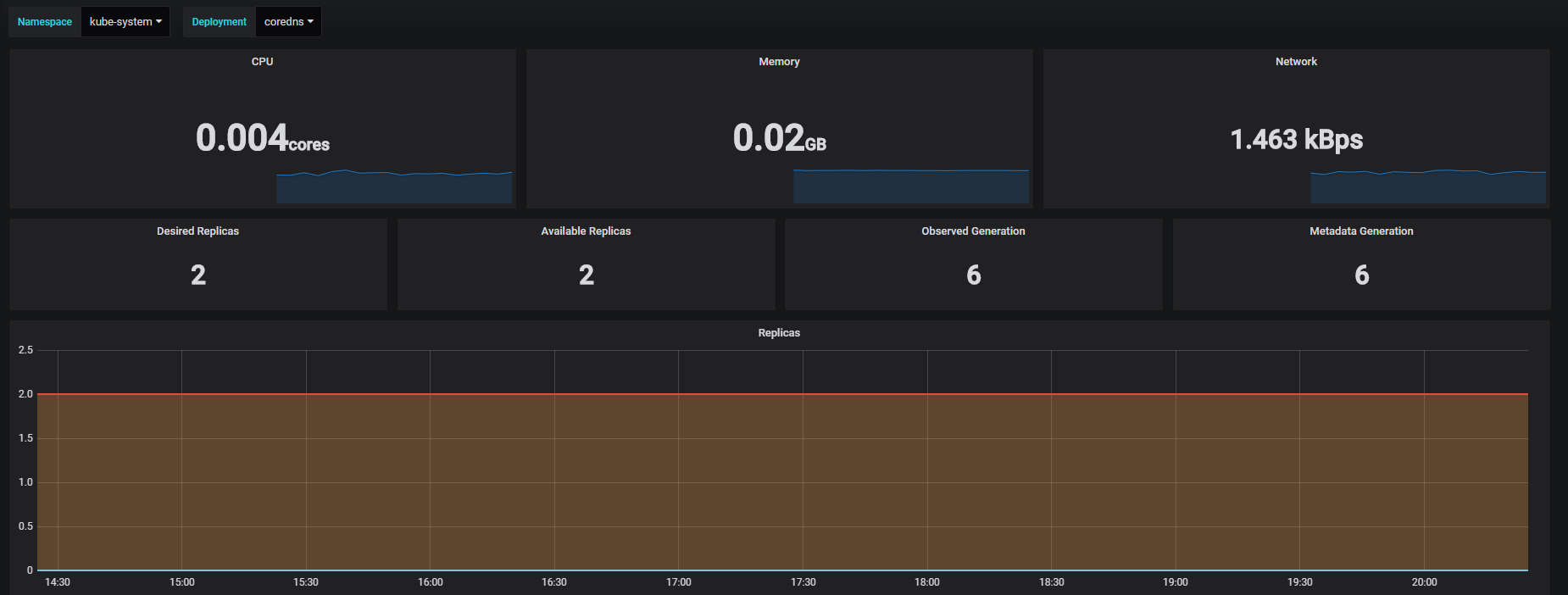
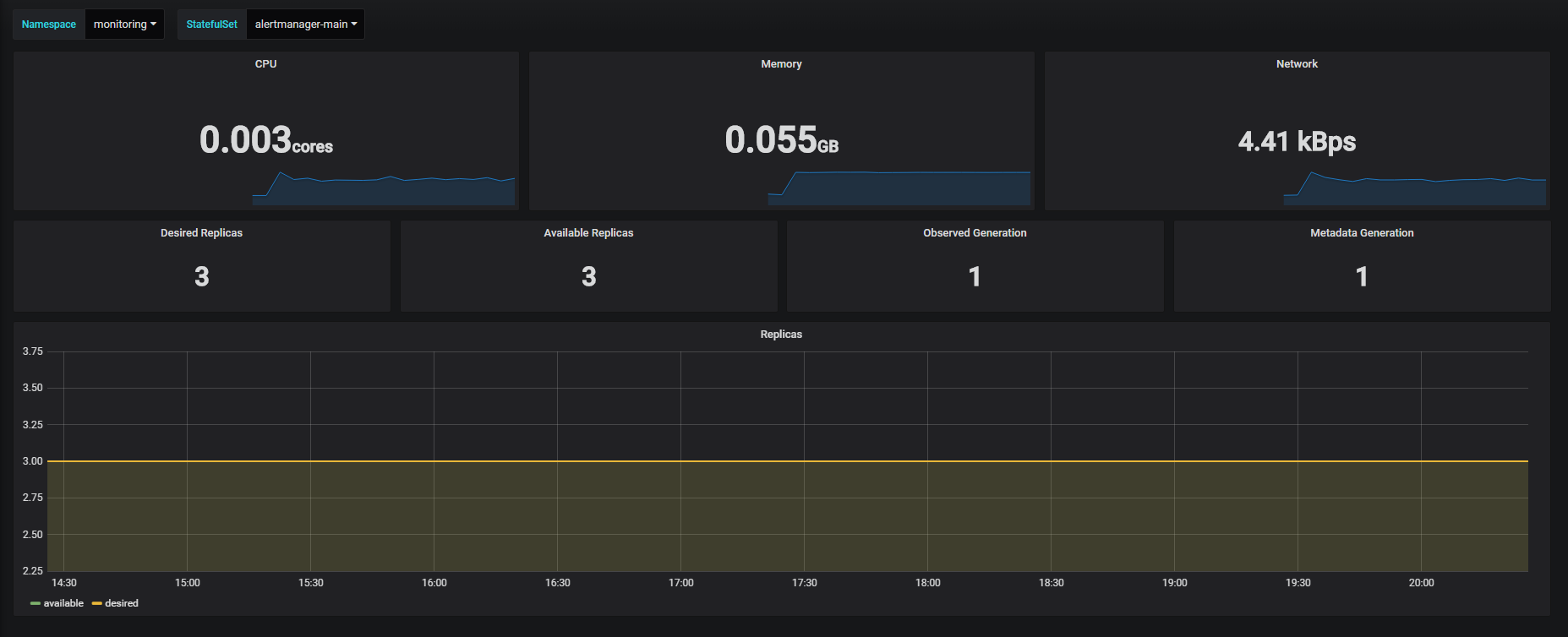
官方默认给的内存和资源都比较小,如果你需要上生产建议按你资源实际情况修改一下,部署完成之后通过编辑修改,否则会出现你的某些服务经常异常重启,大多都由资源到达了临界点导致的。
参考文件:
https://zhangguanzhang.github.io/2018/10/12/prometheus-operator/#%E9%83%A8%E7%BD%B2%E5%AE%98%E6%96%B9%E7%9A%84prometheus-operator
https://github.com/coreos/prometheus-operator/tree/master/Documentation
https://github.com/coreos/prometheus-operator/tree/master/contrib/kube-prometheus/docs

 浙公网安备 33010602011771号
浙公网安备 33010602011771号