Mysqlday02(导入外部sql文件,order by,group by,having,多表联查,查元数据,数值类型,日期类型,字符数据类型)
一、导入外部sql文件
如果想要导入多条数据可以使用一下方法
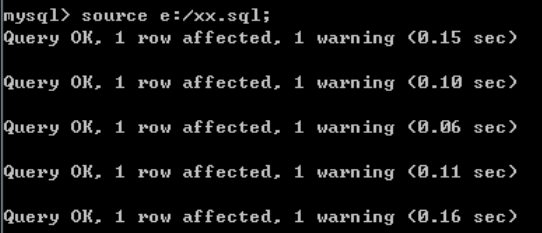
1、创建一个.sql的文件,在内部编写sql语句,注意每一句sql语句之后都要添加分号;
2、mysql中使用指令 source 路径/xxx.sql 就可以引入
二、order by、limit
排序和限制
基本语法:
SELECT * FROM tablename [WHERE CONDITION] [ORDER BY field1 [DESC|ASC] , field2 [DESC|ASC] , ... fieldn [DESC|ASC]];
select * from 表名 (可以有where条件)order by 字段名称(表示根据谁排序) desc|asc
DESC:降序排列
ASC:升序排列,默认方式

- 对于排序后的记录,如果希望只显示一部分,而不是全部,则可以使用LIMIT关键字来实现:
- SELECT ... ... [LIMIT offset_start,row_count];
- select * from 表名limit 值1,值2;
- 值1:显示数据的起始位置 值2 显示多少条数据
-
- offset_start:表示记录的起始偏移量
- row_count:表示显示的行数
- 注意:
- LIMIT经常和order by一起配合使用来进行记录的分页显示;
LIMIT属于在MySQL扩展SQL92后的语法,在其他数据库上不能使用。

三、聚合
- 基本语法:
- SELECT [field1,field2,...,fieldn] fun_name from tablename
[WHERE where_contition]
[GROUP BY field1,field2,...,fieldn [WITH ROLLUP]]
[HAVING where_contition]
- fun_name:表示要做的聚合操作,也就是聚合函数,常用的有sum(求和)、count(*)(记录数)、avg(平均值)、max(最大值)、min(最小值)
- GROUP BY:关键字表示要进行分类聚合的字段,比如要按照部门分类统计员工数据,部门就应该写在GROUP BY后面
- WITH ROLLUP:是可选参数,表明是否对分类聚合后的结果进行再汇总
- HAVING:关键字表示对分类后的结果再进行条件的过滤
- 注意:
- HAVING和WHERE的区别在于,HAVING是对聚合后的结果进行条件的过滤,而WHERE是在聚合前就对记录进行过滤。如果逻辑允许,我们尽可能用WHERE先过滤记录,因为这样的结果集减小,聚合的效率将大大提高,最后再根据逻辑看是否用HAVING进行再过滤。
-
根据部门进行分组 查看部门人数:
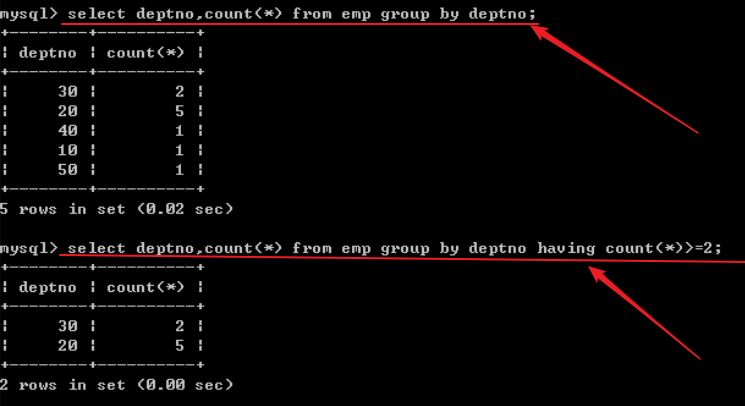
根据部门进行分组,每个部门的最高工资和最低工资是什么 平均工资是多少

每个字段可以起别名
select 字段名 as 自定义名称 ,字段名2 as 自定义名称2 ..... from表名
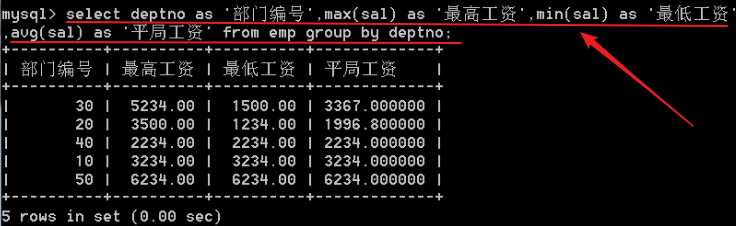
可以省略掉as

四、查询元数据
元数据指的是数据的数据,比如表名、列名、列类型、索引名等表的各种属性名称。
%:0~n个字符
_:1个字符

- 在日常工作中,可能经常会遇到类似下面的应用场景:
- 删除数据库test1下所有前缀为tmp的表;
- 将数据库test1下所有存储引擎为myisam的表改为innodb;
对于这类需求,在MySQL5.0之前只能通过show table、show create table或者show table status等命令来得到指定数据库下的表名和存储引擎,但通过这些命令显示的内容有限且不适合进行字符串的批量编辑。如果表很多,则操作起来非常低效。
MySQL5.0之后提供了一个新的数据库information_schema,用来记录MySQL中的元数据信息。
元数据指的是数据的数据,比如表名、列名、列类型、索引名等表的各种属性名称。
可以简单地通过两个命令得到需要的SQL语句:
select concat('drop table test1.',table_name,';') from tables where table_schema='test1' and table_name like 'tmp%';
select concat('alter table test1.',table_name,' engine=innodb;') from tables where table_schema='test1' and engine='MyISAM';
- 比较常用的视图:
- SCHEMATA:该表提供了当前MySQL实例中所有数据库的信息,show databases的结果取之此表。
- TABLES:该表提供了关于数据库中的表的信息(包括视图),详细表述了某个表属于哪个schema、表类型、表引擎、创建时间等信息。show tables from schemaname的结果取之此表。
- COLUMNS:该表提供了表中的列信息,详细表述了某张表的所有列以及每个列的信息,show columns from schemaname.tablename的结果取之此表。
- STATISTICS:该表提供了关于表索引的信息。show index from schemaname.tablename的结果取之此表。

五、数值类型
MySQL提供了多种数据类型,主要包括:
数值型
字符串类型
日期和时间类型
标准SQL中的数值类型:
严格数值类型:INTEGER,SMALLINT,DECIMAL,和NUMERRIC
近似数值类型:FLOAT,REAL,DOUBLE和PRECISIO
扩展后增加的类型:
TINYINT,MEDIUMINT,BIGINT,BIT
注意:INT 是INTEGER 的同名词,DEC 和 DECIMAL 一样。

六、日期类型

- 如果要用来表示年月日,通常用DATE来表示;
- 如果要用来表示年月日时分秒,通常用DATETIME或者TIMESTAMP表示;
- 如果只用来表示时分秒,通常用TIME来表示;
- 如果只是表示年份, 可以用YEAR来表示,它比DATE占用更少的空间。YEAR有2位或4位格式的年。默认是4位格式中,允许的值是1901~2155和0000。在2位格式中,允许的值是70~69,表示从1970~2069年。MySQL以YYYY格式显示YEAR值(从5.5.27开始,2位格式的year已经不被支持)。
注意:每种日期时间类型都有一个有效值范围,如果超出这个范围,在默认的SQLMode下,系统会进行错误提示,
并将以零值来进行存储。
七、字符数据类型

- CHAR和VARCHAR类型:
- 两者的主要区别在于存储方式不同:
- CHAR列的长度固定为创建表时声明的长度,而VARCHAR列中的值为可变长字符串;
- 在检查的时候,CHAR列删除尾部的空格,而VARCHAR则保留这些空格
- 两者的主要区别在于存储方式不同:
- BINARY和VARBINARY类型:
- BINARYT和VARBINARY类似于CHAR和VARCHAR,不同的是它们包含二进制字符串而不包含非二进制字符串。
- ENUM类型:
- ENUM中文名称叫枚举类型,它的值范围需要在创建表时通过枚举方式显示指定,对1~255个成同的枚举需要1个字节存储,对于255~65535个成员,需要2个字节来存储。最多允许65535个成员。
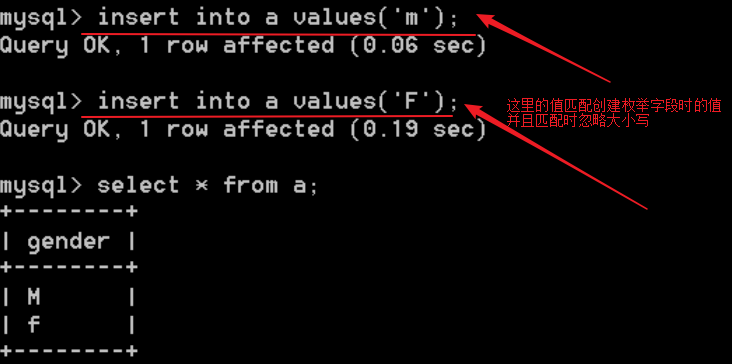
- 注意:
- 忽略大小写
- 插入不在ENUM范围内的值时,插入的是第一个值(高版本会检测)
- 只允许从值集合中选取单个值,不能一次取多个值


- SET类型:
- SET和ENUM类型非常类似,也是一个字符串对象,里面可以包含0~64个成员。根据成员的不同,存储上也有所不同。
- 1~8成员的集合,占1个字节
- 9~16成员的集合,占2个字节
- 17~24成员的集合,占3个字节
- 25~32成员的集合,占4个字节
- 33~64成员的集合,占8个字节
- SET和ENUM类型非常类似,也是一个字符串对象,里面可以包含0~64个成员。根据成员的不同,存储上也有所不同。

- 注意:
- SET和ENUM除了存储以外,最主要的区别在于SET类型一次可以行取多个成员,而ENUM则只能选一个。
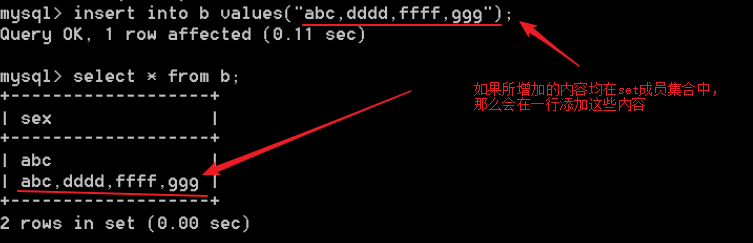

SET中重复值只取一次,超出范围的内值不允许插入操作

超出set范围内的值不可以添加


 浙公网安备 33010602011771号
浙公网安备 33010602011771号