Javaday22(字节流补充,字符流,序列化)
一、RandomAccessFile字节流
- 之前通过流访问文件都是循序访问的,在某些时候我们需要对文件进行随机访问,就需要借助与RandomAccessFile工具
- RandomAccessFile类可以在文件中任何位置查找或写入数据
- RandomAccessFile同时实现了DataInput和DataOutput接口
- 磁盘文件都是可以随机访问的, 但是从网络而来的数据流却不是
- 通过构造器打开一个随机访问文件工具对象,通过参数可以确定只用于读取数据或同时用于读写:
RandomAccessFile in= new RandomAccessFile("data.bin", "r");
RandomAccessFile inOut = new RandomAccessFile("data.bin", "rw");
- seek 方法:
- 随机访问文件有一个表示下一个将被读入或写出的字节所处的位置的文件指针, seek方法可以将这个文件指针设置到文件中任意字节的位置
- 是从文件最初的位置开始计算下标,就算已经存在读取过的内容,依旧是从文件头部开始计算
- 使用RandomAccessFile工具要点:
- 假设想读入第三条数据:
long n = 3;
in.seek((n-1) * RECORD_SIZE);
- 如果希望修改数据,切记将文件指针重置到希望写入文件的开始处:
in.seek((n-1) * RECORD_SIZE);
e.writeData(out);
- length()方法:
- 确定文件大小,使用 length 方法;
- 整数和浮点值在二进制格式中都有固定的尺寸, 但处理字符串就存在麻烦,之前提到过如果使用writeUTF()实际是对Unicode编码做了简单的处理,每个字符长度并不相同,因此在示例代码中我们提供了两个自定义方法来读写具有固定尺寸的字符串:
- writeFixedString 方法:
- 写出从字符串开头开始的指定数量的字符编码
- readFixedString 方法:
- 从输入流中读入字符,直至读入参数个字符编码, 或者直至到具有0值的字符值,然后跳过输入字段中剩余的0值;为了提高效率,使用 StringBuilder 类来读入字符串
1 package com.chinasofti.randomaccessfile; 2 3 import java.io.File; 4 import java.io.FileNotFoundException; 5 import java.io.IOException; 6 import java.io.RandomAccessFile; 7 8 public class RandomAccessFileTest { 9 public static void main(String[] args) { 10 try { 11 File file = new File("a.txt"); 12 file.createNewFile(); 13 // 创建随机访问文件的输入流 14 RandomAccessFile in = new RandomAccessFile("a.txt","r"); 15 // 创建随机访问文件的输出流 16 RandomAccessFile out = new RandomAccessFile("a.txt","rw"); 17 18 // out.seek(10); 19 out.writeInt(11); 20 out.writeBoolean(true); 21 out.writeDouble(13.11); 22 out.writeUTF("嘻嘻哈哈和"); 23 24 System.out.println(in.readInt()); // 11 25 // 跳过4个字节 然后读取 26 in.seek(4); 27 System.out.println(in.readBoolean()); // true 28 System.out.println(in.readDouble()); // 13.11 29 // 跳过13个字节 然后读取 是从文件刚开始读取的位置开始 跳过13个字节 30 in.seek(13); 31 System.out.println(in.readUTF()); // 嘻嘻哈哈和 32 } catch (FileNotFoundException e) { 33 e.printStackTrace(); 34 } catch (IOException e) { 35 e.printStackTrace(); 36 } 37 } 38 }
- 之前曾经提到过,在Java中最适于用作内存数据缓存的类型是byte[],原因在于Java中所有能够表达的数据类型占用空间都是byte数据占用空间的整数倍
- 在之前的输入输出流示例中,我们都将程序的数据源或数据持久化目标谁定为了磁盘文件,而在很多时候我们的程序运算中间结果只需要将数据缓存在内存中以便于后续进行传输或最终的持久化
- ByteArrayOutputStream/ByteArrayInputStream这一对输入输出工具为我们提供了在内存中利用byte[]进行缓冲流操作的工具
- ByteArrayOutputStream提供工具将内存中以串行序列存在的流式数据以一个字节为单位进行切分,形成一个byte[]数组
- 而ByteArrayInputStream则正好相反,提供工具将内存中的byte[]数组中的数据进行串行序列化拼接,形成一个可供操作的流式数据
- 从功能上看,ByteArrayOutpuStream可以将任意数据组合转换为byte[],而ByteArrayInputStream可以将这个数组还原,从而以流的形式读取任意数据组合
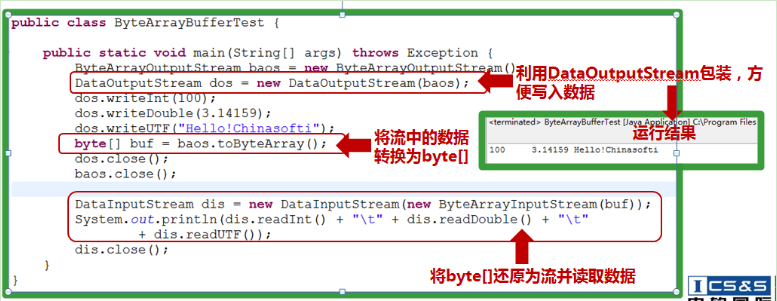
1 package com.chinasofti.bytearrayinputstream; 2 3 import java.io.*; 4 import java.util.Date; 5 6 public class ByteArrayInputStreamTest { 7 public static void main(String[] args) { 8 // 创建一个字节输出流 只是向输出流中添加数据 与文件无关 如果要进行文件读取需要使用FileOutputStream或者FileInputStream 9 ByteArrayOutputStream baos = new ByteArrayOutputStream(); 10 DataOutputStream dos = new DataOutputStream(baos); 11 12 try { 13 dos.writeInt(123); 14 dos.writeBoolean(false); 15 dos.writeDouble(321); 16 dos.writeUTF("hehe"); 17 } catch (IOException e) { 18 e.printStackTrace(); 19 } 20 21 byte[] bytes = baos.toByteArray(); // 将字节数组输出流转换成字节数组 22 23 // 创建字节数组输入流 参数为字节数组 将字节数组转换成输入流 24 ByteArrayInputStream bais = new ByteArrayInputStream(bytes); 25 DataInputStream dis = new DataInputStream(bais); // 将输入流使用DataInputStream装饰 26 27 try { 28 System.out.println(dis.readInt()); 29 System.out.println(dis.readBoolean()); 30 System.out.println(dis.readDouble()); 31 System.out.println(dis.readUTF()); 32 } catch (IOException e) { 33 e.printStackTrace(); 34 } 35 } 36 }
二、Writer
FileInputStram类和FileOutputStream类虽然可以高效率地读/写文件,但对于Unicode编码的文件,我们需要自行将读取到的字节数据根据编码规则还原为字符串,因此使用它们有可能出现乱码
考虑到Java是跨平台的语言,要经常操作Unicode编码的文件,使用基于字符为读、写基本单元的字符流操作文件是有必要的,以字符为单位进行数据输出的工具继承自Writer

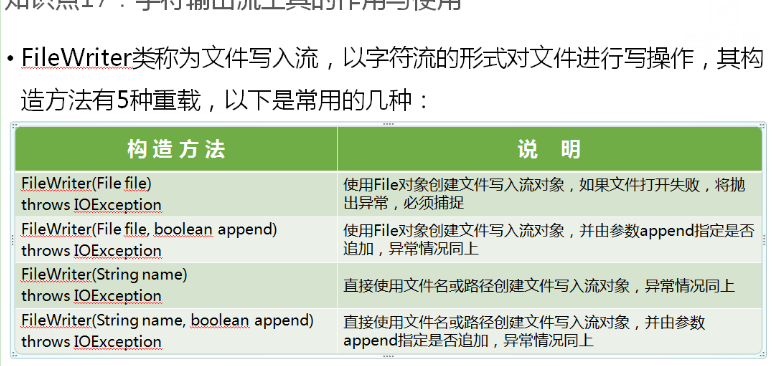
1 package com.chinasofti.filewriter; 2 3 import java.io.FileReader; 4 import java.io.FileWriter; 5 import java.io.IOException; 6 import java.util.Scanner; 7 8 public class FileWriterTest { 9 public static void main(String[] args) { 10 // 声明一个文件字符输出流 11 FileWriter fileWriter = null; 12 FileReader fileReader = null; 13 try { 14 fileWriter = new FileWriter("a.txt",true); 15 fileReader = new FileReader("a.txt"); 16 17 18 19 Scanner s = new Scanner(System.in); 20 while (true){ 21 System.out.println("输入字符:"); 22 fileWriter.write(s.next()); 23 fileWriter.flush(); 24 25 break; 26 } 27 28 // 创建一个字符数组 29 char[] arr = new char[500]; 30 fileReader.read(arr); 31 System.out.println(new String(arr)); 32 33 } catch (IOException e) { 34 e.printStackTrace(); 35 }finally { 36 try { 37 if(fileReader!=null) {fileWriter.close();} 38 } catch (IOException e) { 39 e.printStackTrace(); 40 } 41 } 42 } 43 }
三、Reader
- 以字符为单位进行数据读取的工具继承自Reader,Reader会将读取到的数据按照标准的规则转换为Java字符串对象

四、Buffer缓冲区输入输出流
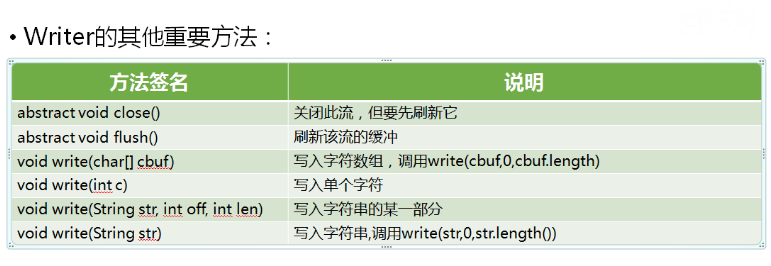
FileWriter将逐个向文件写入字符,效率比较低下,因此一般将该类对象包装到缓冲流中进行操作
还可以使用PrintWriter对流进行包装,提供更方便的字符输出格式控制
PrintWriter
1 package com.chinasofti.printwriter; 2 3 import java.io.FileWriter; 4 import java.io.IOException; 5 import java.io.PrintWriter; 6 7 public class PrintWriterTest { 8 public static void main(String[] args) { 9 // 声明一个字符格式输出流 10 PrintWriter pw = null; 11 try { 12 pw = new PrintWriter(new FileWriter("a.txt",true)); 13 // 向缓冲区中写入字符串 14 pw.println("12356"); 15 // 向缓冲区中写入字符串 16 pw.println("嘻嘻哈哈和"); 17 // 刷新缓冲区 数据从缓冲区中输出 18 // pw.flush(); 19 } catch (IOException e) { 20 e.printStackTrace(); 21 }finally { 22 if (pw!=null) {pw.close();} 23 } 24 } 25 }
BufferedWriter
1 package com.chinasofti.bufferedwriter; 2 3 import java.io.BufferedWriter; 4 import java.io.File; 5 import java.io.FileWriter; 6 import java.io.IOException; 7 8 public class writerTest { 9 public static void main(String[] args) { 10 // 声明一个字符缓冲输出流 11 BufferedWriter bw = null; 12 try { 13 bw = new BufferedWriter(new FileWriter("a.txt",true)); 14 // 创建一个新行 15 bw.newLine(); 16 // 输出字符串 17 bw.write("12356"); 18 bw.newLine(); 19 // 输出字符串 20 bw.write("嘻嘻哈哈和"); 21 bw.newLine(); 22 // 刷新缓冲区 数据从缓冲区中清楚 23 bw.flush(); 24 } catch (IOException e) { 25 e.printStackTrace(); 26 }finally { 27 try { 28 if (bw!=null) {bw.close();} 29 } catch (IOException e) { 30 e.printStackTrace(); 31 } 32 } 33 } 34 }
BufferedReader
1 package com.chinasofti.bufferedwriter; 2 3 import java.io.BufferedReader; 4 import java.io.FileNotFoundException; 5 import java.io.FileReader; 6 import java.io.IOException; 7 8 public class readerTest { 9 public static void main(String[] args) { 10 // 声明一个字符缓冲输入流 11 BufferedReader bufferedReader = null; 12 13 try { 14 // 给定一个输入流为参数 15 bufferedReader = new BufferedReader(new FileReader("a.txt")); 16 17 String msg = null; 18 // 逐行读取文件中的信息 19 while ((msg=bufferedReader.readLine())!=null){ 20 System.out.println(msg); 21 } 22 } catch (FileNotFoundException e) { 23 e.printStackTrace(); 24 } catch (IOException e) { 25 e.printStackTrace(); 26 }finally { 27 try { 28 if(bufferedReader!=null) bufferedReader.close(); 29 } catch (IOException e) { 30 e.printStackTrace(); 31 } 32 } 33 34 } 35 }
- 和PushbackInputStream类似,Java也提供了PushbackReader,提供了在读取流的同时将字符推回流的能力,使用方法和PushbackInputStream类似
- 在某些时候虽然我们操作的是字符串,但是不得不面对数据来源是InputStream(字节输入流)的情况,在这种情况下,Java提供了将InputStream和Reader之间进行转换的工具,事实上,字节输出流和字符输出流之间也存在这种工具,称为:字节流与字符流的适配器:
- InputStreamReader:
- 字节流通向字符流的桥梁,它使用指定的 charset 读取字节并将其解码为字符。它使用的字符集可以由名称指定或显式给定,或者可以接受平台默认的字符集
- 每次调用 InputStreamReader 中的一个 read() 方法都会导致从底层输入流读取一个或多个字节。要启用从字节到字符的有效转换,可以提前从底层流读取更多的字节,使其超过满足当前读取操作所需的字节
- OutputStreamWriter:
- 字符流通向字节流的桥梁,使用指定的 charset 将要写入流中的字符编码成字节。它使用的字符集可以由名称指定或显式给定,否则将接受平台默认的字符集
- 每次调用 write() 方法都会导致在给定字符(或字符集)上调用编码转换器。在写入底层输出流之前,得到的这些字节将在缓冲区中累积。可以指定此缓冲区的大小,不过,默认的缓冲区对多数用途来说已足够大。注意,传递给 write() 方法的字符没有缓冲
1 package com.chinasofti.inputstreamwriter; 2 3 import java.io.*; 4 5 public class Test { 6 public static void main(String[] args) { 7 try { 8 write("adasdasda"); 9 read(); 10 } catch (FileNotFoundException e) { 11 e.printStackTrace(); 12 } catch (IOException e) { 13 e.printStackTrace(); 14 } 15 } 16 17 // ✍ 字节输出流转字符输出流 18 public static void write(String msg) throws FileNotFoundException { 19 // 创建一个文件对象 20 File file = new File("a.txt"); 21 // 创建一个文件输出流 22 FileOutputStream fos = new FileOutputStream(file); 23 // 将字节输出流转换成字符输出流 24 OutputStreamWriter osw = new OutputStreamWriter(fos); 25 // 将输出字符流使用PrintWriter装饰 26 PrintWriter pw = new PrintWriter(osw); 27 28 pw.write(msg); 29 pw.flush(); 30 pw.close(); 31 } 32 33 // ✍ 字节输入流转字符输入流 34 public static void read() throws IOException { 35 // 创建一个文件对象 36 File file = new File("a.txt"); 37 // 创建一个文件输入字节流 38 FileInputStream fis = new FileInputStream(file); 39 // 将文件输入字节流转换成字符流 40 InputStreamReader isr = new InputStreamReader(fis); 41 // 将字符流使用BufferedReader装饰 一次读取一行 42 BufferedReader br = new BufferedReader(isr); 43 String msg = null; 44 while ((msg=br.readLine())!=null){ 45 System.out.println(msg); 46 } 47 48 br.close(); 49 } 50 }
- Java还提供了另一个包装工具来方便的进行流中数据的读取:Scanner
- Scanner类位于java.util包中,不在java.io包中,不属于IO流
- Scanner是一个工具类,主要目标是简化文本的扫描,最常使用此类获取控制台输入,Scanner获取控制台输入的步骤:
- 使用控制台输入创建Scanner对象
Scanner scanner=new Scanner(System.in);
- 调用Scanner中的nextXXX方法,获得需要的数据类型
- 例如:next、 nextLine、nextInt、nextByte等
- java中有几种类型的流?jdk为每种类型的流提供了一些抽象类以供继承,请说出它们分别是什么?
- Java中的输入输出流分为字符流和字节流。字节流继承inputStream和OutputStream,字符流继承自Reader和Writer。在java.io包中还有许多其他的流,主要是为了提高性能和使用方便
- Java为字节流和字符流提供了转换适配器:InputStreamReader,OutputStreamWriter
五、序列化
- Java平台允许我们在内存中创建可复用的Java对象,但一般情况下,只有当JVM处于运行时,这些对象才可能存在,即,这些对象的生命周期不会比JVM的生命周期更长。但在现实应用中,就可能要求在JVM停止运行之后能够保存(持久化)指定的对象,并在将来重新读取被保存的对象。Java对象序列化就能够帮助我们实现该功能
- 使用Java对象序列化,在保存对象时,会把其状态保存为一组字节,在未来,再将这些字节组装成对象。必须注意地是,对象序列化保存的是对象的"状态",即它的成员变量。由此可知,对象序列化不会关注类中的静态变量
- 除了在持久化对象时会用到对象序列化之外,当使用RPC(包括Java标准RMI远程方法调用),或在网络中传递对象时,都会用到对象序列化。Java序列化API为处理对象序列化提供了一个标准机制
- 在Java中,只要一个类实现了java.io.Serializable接口,那么它就可以被序列化
- java.io.Serializable是一个标识接口,即意味着它仅仅是为了说明类的可序列化属性,接口没有包含任何需要子类实现的抽象方法
- 将对象的状态信息保存到流中的操作,称为序列化,可以使用Java提供的工具ObjectOutputStream. writeObject(Serializable obj)来完成
- 从流中读取对心状态信息的操作称为反序列化,可以使用Java提供的工具ObjectInputStream.readObject()来完成

- 上例是一个简单的序列化程序,它先将一个Person对象保存到缓存中,然后再从该缓存中读出被存储的Person对象,并打印该对象
- 从上例的运行结果可以看出的要点:对象序列化过程不仅仅保存单个对象,还能追踪对象内所包含的所有引用,并保存那些对象(这些对象也需实现了Serializable接口)
- 对于Serializable反序列化后的对象,不需要调用构造方法重新构造,对象完全以它存储的二进制位作为基础来构造,而不调用构造方法
- 序列前的对象与序列化后的对象是深复制,反序列化还原后的对象地址与原来的的地址不同,但是内容是一样的,而且对象中包含的引用也相同。换句话说,通过序列化操作,我们可以实现对任何可Serializable对象的”深度复制“,这意味着复制的是整个对象网,而不仅仅是基本对象及其引用。对于同一流的对象,他们的地址是相同,说明他们是同一个对象,但是与其他流的对象地址却不相同。也就说,只要将对象序列化到单一流中,就可以恢复出与我们写出时一样的对象网,而且只要在同一流中,对象都是同一个
- 上面提到,如果仅仅只是让某个类实现Serializable接口,而没有其它任何处理的话,则就是使用默认序列化机制。
- 使用默认机制,在序列化对象时,不仅会序列化当前对象本身,还会对该对象引用的其它对象也进行序列化,同样地,这些其它对象引用的另外对象也将被序列化,以此类推。所以,如果一个对象包含的成员变量是容器类对象,而这些容器所含有的元素也是容器类对象,那么这个序列化的过程就会较复杂,开销也较大
- 在现实应用中,有些时候不能使用默认序列化机制。比如,希望在序列化过程中忽略掉敏感数据,或者简化序列化过程
当某个字段被声明为transient后,默认序列化机制就会忽略该字段
- 注意:刚辞说的是添加方法而不是“覆盖”或者“实现”,因为这两个方法不是基类Object也不是接口Serializable中的方法)
- 一旦对象被序列化或者反序列还原,就会自动地分别调用者两个方法。也就是说,只要我们提供了这两个方法,就会使用它们而不是默认的序列化机制
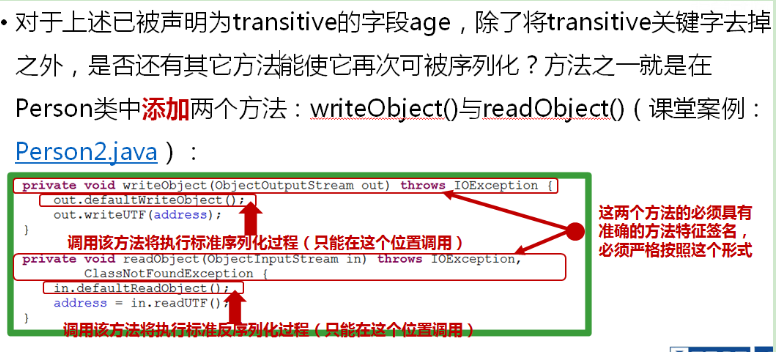
- 这个两个方法必须在类内部自己实现。大家应该注意到这两个方法其实是private类型。也就是说这两个方法仅能被这个类的其他成员调用,但其实我们没有在这个类的其他的方法中调用这两个方法。那么到底是谁调用这两个方法呢?是ObjectOutputStream和ObjectInputStream对象的writeObject和readObject()方法分别调用者两个方法(通过过反射机制来访问类的私有方法),在调用ObjectOutputStream.writeObject()时,会检查所传递的Serializable对象,利用反射来搜索是否有writeObject()方法。如果有,就会跳过正常的序列化过程,转而调用这个它的writeObject()方法,readObject方法处理方式也一样
- writeObject()内部可以通过ObjectOutputStream.defaultWriteObject()来执行默认的writeObject()(非transient字段由这个方法保存),同样的,在类readObject内部,可以通过ObjectInputStream.defalutReadObject()来执行默认的readObject()方法
Student类
1 package com.chinasofti.serailizabletest; 2 3 import java.io.Serializable; 4 5 public class Student implements Serializable { 6 private String name; 7 private int id; 8 private double score; 9 10 @Override 11 public String toString() { 12 return "Student{" + 13 "name='" + name + '\'' + 14 ", id=" + id + 15 ", score=" + score + 16 '}'; 17 } 18 19 public String getName() { 20 return name; 21 } 22 23 public void setName(String name) { 24 this.name = name; 25 } 26 27 public int getId() { 28 return id; 29 } 30 31 public void setId(int id) { 32 this.id = id; 33 } 34 35 public double getScore() { 36 return score; 37 } 38 39 public void setScore(double score) { 40 this.score = score; 41 } 42 43 public Student(String name, int id, double score) { 44 this.name = name; 45 this.id = id; 46 this.score = score; 47 } 48 }
序列化测试类
1 package com.chinasofti.serailizabletest; 2 3 import java.io.*; 4 5 public class Test { 6 public static void main(String[] args) throws IOException, ClassNotFoundException { 7 Student s1 = new Student("藏撒谎", 1001, 98); 8 9 // 序列化 10 // 创建对象输出流 参数为输出流 11 ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("Student.bin")); 12 // 将对象写入输出流 13 oos.writeObject(s1); 14 oos.writeObject(s1); 15 oos.flush(); 16 oos.close(); 17 18 // 创建对象输入流 参数为输入流 19 ObjectInputStream ois = new ObjectInputStream(new FileInputStream("Student.bin")); 20 // 从对象输入流中读取对象 21 System.out.println(ois.readObject()); 22 System.out.println(ois.readObject()); 23 oos.close(); 24 } 25 }
执行结果:
Student{name='藏撒谎', id=1001, score=98.0}
Student{name='藏撒谎', id=1001, score=98.0}
Process finished with exit code 0
