leetcode (堆->中级) 264,313,347,373,378,767,1642,973,1673,743,787
264 原本想的是从1开始遍历,计算每个数是否是丑数,然后用个set存下当前数是否是丑数,后面的数在除以2/3/5如果结果在set里可以找到的话就可以直接取这个结果数作为当前数的计算结果,避免重复运算。结果超时了。。。
然后看了下大佬的思路才知道是用三指针来解,核心思想就是每个丑数都肯定是2,3,5相乘得来的,那就自己计算丑数,关键在于如何知道乘的顺序例如 2*2 2*3 2*5 3*3 3*5 4*2 4*3 4*5 这样乘下来的话顺序就乱了,所以需要三个指针来保存 *2 *3 *5 每次的最小值
具体代码如下

public static int nthUglyNumber1(int n) { if (n ==1)return 1; int[] arr = new int[n]; arr[0] = 1; int k1 = 0,k2 = 0,k3 = 0; int co = 1; while (co < n){ int tl1 = arr[k1]*2,tl2 = arr[k2]*3,tl3=arr[k3]*5; int score = Math.min(tl1,Math.min(tl2,tl3)); if (score == tl1){ k1++; } if (score == tl2){ k2++; } if (score == tl3){ k3++; } arr[co++] = score; } return arr[n-1]; }
313 和上题基本一个逻辑
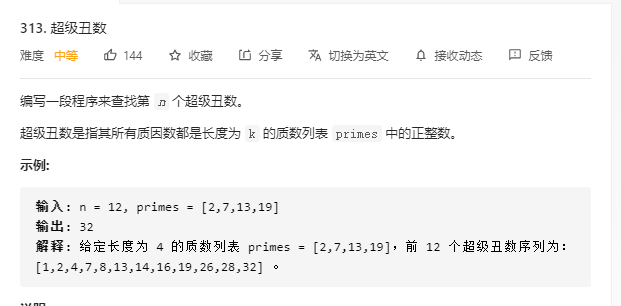
public static int nthSuperUglyNumber(int n, int[] primes) { int[] factor = new int[primes.length]; Arrays.fill(factor,0); int[] result = new int[n]; result[0] = 1; for (int i = 1; i < n; i++) { int min = Integer.MAX_VALUE; for (int j = 0; j < factor.length; j++) { min = Math.min(primes[j]*result[factor[j]],min); } for (int j = 0; j < factor.length; j++) { if (min == primes[j]*result[factor[j]]){ factor[j] = factor[j]+1; } } result[i] = min; } return result[n-1]; }
347 看着题应该是用hash表算出每个数字出现的次数,在用堆计算出前K大值
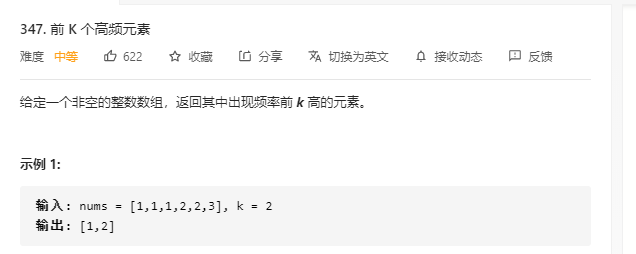
public static int[] topKFrequent(int[] nums, int k) { Map<Integer,Integer> map = new HashMap<>(); for (int i = 0; i < nums.length; i++) { map.put(nums[i],map.getOrDefault(nums[i],0)+1); } PriorityQueue<Integer> priorityQueue = new PriorityQueue<>((k1,k2)->{ return map.get(k1)-map.get(k2); }); Set<Integer> keys = map.keySet(); int tp = 0; for (Integer key : keys) { if (tp < k){ priorityQueue.offer(key); }else { if (map.get(key) > map.get(priorityQueue.peek()) ){ priorityQueue.poll(); priorityQueue.offer(key); } } tp++; } int size = priorityQueue.size(); int[] result = new int[size]; for (int i = 0; i <size; i++) { result[i] = priorityQueue.poll(); } return result; }
373 依旧是用堆,但是有个注意点是遍历的时候如果当前遍历点大于了堆顶 那么余下的肯定也是大于堆顶的,所以遍历到正确值后 后面基本都不需要遍历了
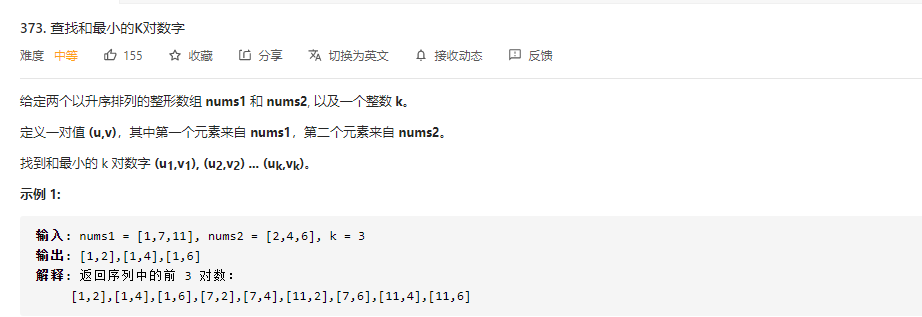
public static List<List<Integer>> kSmallestPairs(int[] nums1, int[] nums2, int k) { PriorityQueue<List<Integer>> pq = new PriorityQueue<>((k1,k2)->{ return k2.get(0)+k2.get(1) - k1.get(0)-k1.get(1); }); A: for (int i = 0; i < nums1.length; i++) { for (int j = 0; j < nums2.length; j++) { if (pq.size() < k){ List<Integer> tp = Arrays.asList(nums1[i],nums2[j]); pq.add(tp); }else { Integer top = pq.peek().stream().reduce((k1, k2) -> k1 + k2).get(); if (nums1[i]+nums2[j] <top){ pq.poll(); pq.add(Arrays.asList(nums1[i],nums2[j])); }else { continue A; } } } } List<List<Integer>> result = new LinkedList<>(); while (!pq.isEmpty()){ ((LinkedList<List<Integer>>) result).addFirst(pq.poll()); } return result; }
378 暴力解法倒是很方便。
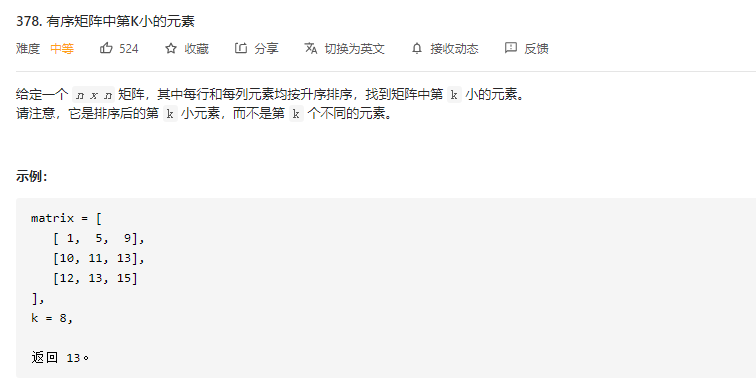
public static int kthSmallest(int[][] matrix, int k) { PriorityQueue<Integer> pq = new PriorityQueue<>((k1,k2)->k2-k1); int rMax = matrix[0].length,onMax = matrix.length; for (int i = 0; i < rMax ; i++) { for (int j = 0; j < onMax; j++) { if (pq.size() < k){ pq.offer(matrix[i][j]); }else { if (matrix[i][j] < pq.peek()){ pq.poll(); pq.offer(matrix[i][j]); }else { if (i == 0){ break; } onMax = j; } } } } return pq.peek(); }
看到有个评论说的是可以理解为N个有序数组合并,想法比较新颖,不过我的代码复杂度很高。。应该是可以优化的按理说
int[] index = new int[matrix.length]; int rightLen = matrix[0].length; int t= 0; while ( t <k){ int min = Integer.MAX_VALUE; for (int j = 0; j < index.length ; j++) { if (index[j] >= rightLen)continue; min = Math.min(matrix[j][index[j]],min); } for (int j = 0; j < index.length ; j++) { if (index[j] >= rightLen)continue; if (min == matrix[j][index[j]]){ index[j] = ++index[j]; t++; if (t == k){ return min; } } } } return 0;
767 题目的思路是通过一个hash表存放每个字母出现的次数,然后将字母放入堆中,一直拿堆最靠顶的两个相加,然后次数减一,这样最后就能拿到结果。其实快速判断是否有的话可以看出现最多的频率是否比整个字符串的长度(偶数 /2还多, 奇数/2 +1 还多) 如果是的话应该是不满足的。
public static String reorganizeString(String S) { Map<Character,Integer> map = new HashMap<>(); int max = 0; for (int i = 0; i < S.length(); i++) { char c = S.charAt(i); int total = map.getOrDefault(c,0)+1; max = Math.max(max,total); map.put(c,total); } PriorityQueue<Character> pq = new PriorityQueue<>((k1,k2)->map.get(k2)-map.get(k1)); pq.addAll(map.keySet()); List<Character> list = new ArrayList<>(); StringBuilder sb = new StringBuilder(); while (!pq.isEmpty()){ Character t1 = pq.poll(); sb.append(t1); if (pq.isEmpty() ){ if (map.get(t1) > 1 ){ return ""; }else { break; } } Character t2 = pq.poll(); sb.append(t2); if (map.get(t1) != 1){ map.put(t1,map.get(t1)-1); pq.add(t1); } if (map.get(t2) != 1){ map.put(t2,map.get(t2)-1); pq.add(t2); } } return sb.toString(); }
1642 思路就是先用砖头,砖头不够时用梯子,如果当前的差值大于了之前的最大差值,就直接用。如果小于的话就将之前的最大差值用梯子,然后返还多余的砖头。

public static int furthestBuilding(int[] heights, int bricks, int ladders) { PriorityQueue<Integer> pq = new PriorityQueue<>((k1,k2)->k2-k1); for (int i = 1; i < heights.length; i++) { if (heights[i] <= heights[i-1]){ continue; } int cut = heights[i]-heights[i-1]; if (cut <= bricks){ bricks -= cut; }else { if (ladders >0){ ladders --; if ( pq.isEmpty() || cut>=pq.peek() ){ continue; }else { Integer poll = pq.poll(); bricks+=(poll-cut); } }else { return i-1; } } pq.add(cut); } return heights.length-1; }
973

public static int[][] kClosest(int[][] points, int k) { PriorityQueue<int[]> pq = new PriorityQueue<>((k1,k2)->{ return (k2[0]*k2[0]+k2[1]*k2[1]) -(k1[0]*k1[0]+k1[1]*k1[1]); }); for (int i = 0; i < points.length; i++) { if (pq.size() < k){ pq.offer(points[i]); }else { if ( points[i][0]*points[i][0]+points[i][1]*points[i][1] < pq.peek()[0]*pq.peek()[0]+pq.peek()[1]*pq.peek()[1]){ pq.poll(); pq.add(points[i]); } } } int[][] result = new int[pq.size()][2]; for (int i = 0; i < result.length; i++) { result[i] = pq.poll(); } return result; }
1673 之前有做过类似的题,结果这次发现时间超出限制了,看评论才知道用单调栈来解
public static int[] mostCompetitive(int[] nums, int k) { int[] result = new int[k]; LinkedList<Integer> stack = new LinkedList<>(); for (int i = 0; i < nums.length; i++) { while (!stack.isEmpty() && k -stack.size() <= nums.length-i-1 && nums[i] < stack.peek() ){ stack.pop(); } stack.push(nums[i]); } for (int i = 0; i < k; i++) { result[i] = stack.removeLast(); } return result; }
743 .计算网络延迟时间
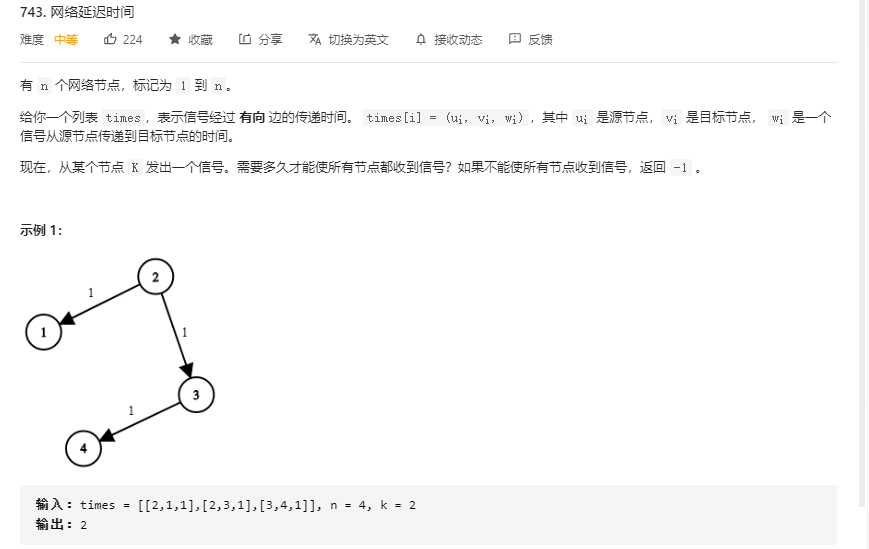
一开始用的递归遍历,效果非常差
public class HeapSimple9 { static Map<Integer,List<int[]>> map = new HashMap<>(); static int[] arrs = null; public static void main(String[] args) { int[][] times = new int[][]{{2,1,1},{2,3,1},{3,4,1}}; System.out.println(networkDelayTime(times,4,2)); } public static int networkDelayTime(int[][] times, int n, int k) { arrs = new int[n]; Arrays.fill(arrs,Integer.MAX_VALUE); arrs[k-1] = 0; for (int i = 0; i < times.length; i++) { int[] data = times[i]; List<int[]> tpl = map.get(data[0]-1); if (tpl == null){ tpl = new ArrayList<>(); tpl.add(data); map.put(data[0]-1,tpl); }else { tpl.add(data); } } handle(k-1); int max = 0; for (int i = 0; i < arrs.length; i++) { max = Math.max(max,arrs[i]); } if ( max == Integer.MAX_VALUE) return -1; return max; } private static void handle(int n){ List<int[]> list = map.get(n); if (list == null){ return; } for (int[] ints : list) { int end = ints[1]; if (arrs[end-1] > arrs[n]+ints[2]){ arrs[end-1] = arrs[n]+ ints[2]; handle(end-1); } } } }
然后改成了用栈来遍历之后效果勉强还行,其实应该还可以优化,就是每次选择当前节点的时候优先选择最短的那个作为下一个遍历的节点,这样应该可以避免更多的重复计算。
public static int networkDelayTime(int[][] times, int n, int k) { Map<Integer,List<int[]>> map = new HashMap<>(); int[] arrs = new int[n]; Arrays.fill(arrs,Integer.MAX_VALUE); arrs[k-1] = 0; for (int i = 0; i < times.length; i++) { int[] data = times[i]; List<int[]> tpl = map.get(data[0]-1); if (tpl == null){ tpl = new ArrayList<>(); tpl.add(data); map.put(data[0]-1,tpl); }else { tpl.add(data); } } LinkedList<Integer> stack = new LinkedList<>(); stack.push(k-1); while (!stack.isEmpty()){ Integer pop = stack.pop(); List<int[]> list = map.get(pop); if (list == null){ continue; } for (int[] ints : list) { int end = ints[1]; if (arrs[end-1] > arrs[pop]+ints[2]){ arrs[end -1] = arrs[pop]+ints[2]; stack.push(end-1); } } } int max = 0; for (int i = 0; i < arrs.length; i++) { max = Math.max(max,arrs[i]); } if ( max == Integer.MAX_VALUE) return -1; return max; }
787 这个题比上题多了个中转限制,但是自己没有想到太好的思路 下面是两种看到的思路

第一种是利用优先队列的方式来遍历,这样保证第一次遍历到目标节点时肯定是最短的
public static int findCheapestPrice(int n, int[][] flights, int src, int dst, int k) { Map<Integer,List<int[]>> map = new HashMap<>(); int[] arrs = new int[n]; Arrays.fill(arrs,Integer.MAX_VALUE); arrs[src] = 0; for (int i = 0; i < flights.length; i++) { int[] data = flights[i]; List<int[]> tpl = map.get(data[0]); if (tpl == null){ tpl = new ArrayList<>(); tpl.add(data); map.put(data[0],tpl); }else { tpl.add(data); } } //0 代表当前站 2代表中转了多少站 3代表花费 PriorityQueue<int[]> pq = new PriorityQueue<>((k1,k2)->k1[2]-k2[2]); pq.add(new int[]{src,0,0}); while (!pq.isEmpty()){ int[] current = pq.poll(); if (current[0] == dst){ return current[2]; } int step = current[1]; List<int[]> list = map.get(current[0]); if (step <= k && list != null){ for (int[] ints : list) { pq.add(new int[]{ints[1],step+1,current[2]+ints[2]}); } } } return -1; }
第二种是dp方式 这个方式原理大概能明白,但代码看不太懂后面懂了再记录下来吧
