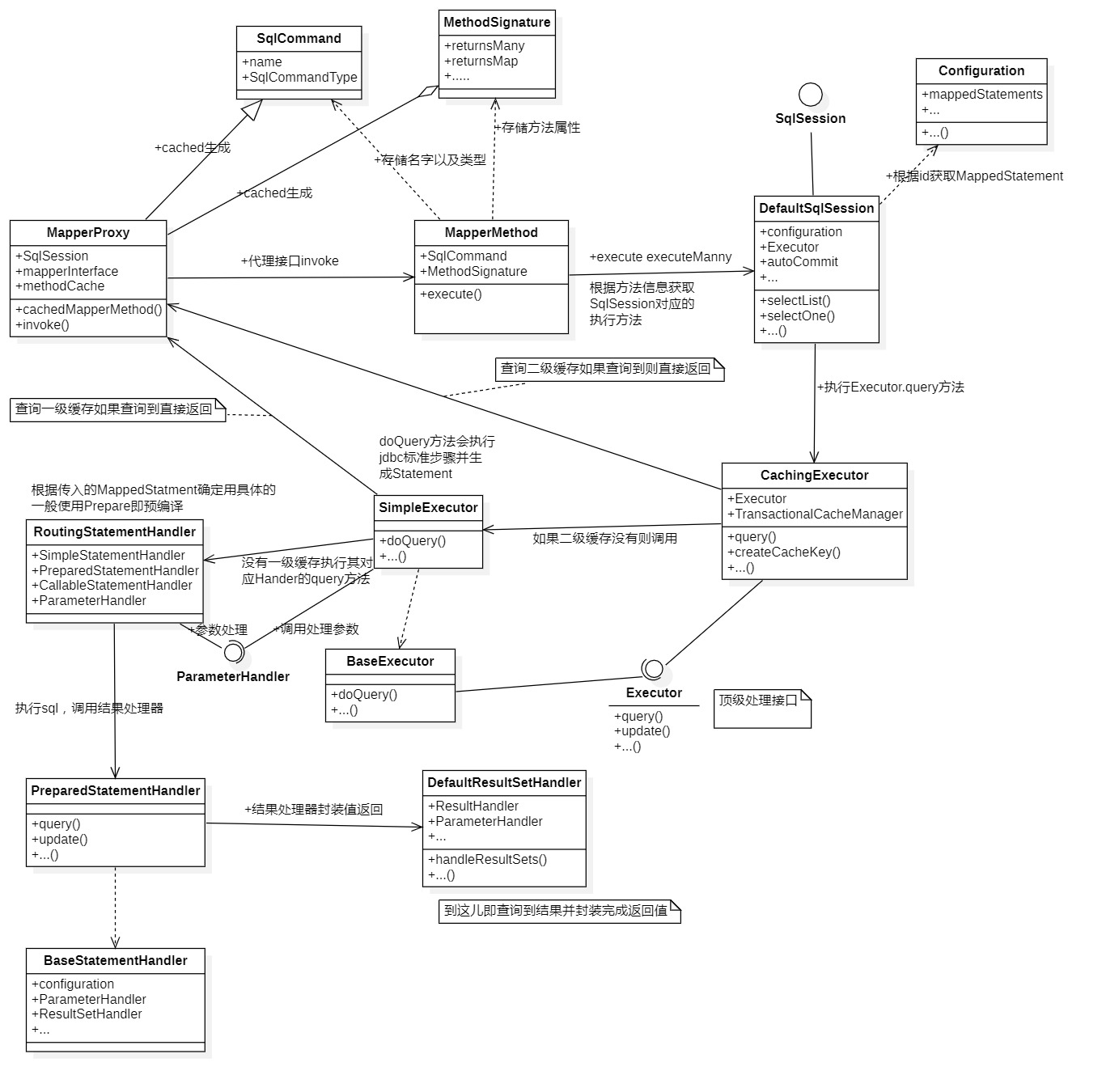
mybatis源码探索笔记-3(使用代理mapper执行方法)
前言
前面两章我们构建了SqlSessionFactory,并通过SqlSessionFactory创建了我们需要的SqlSession,并通过这个SqlSession获取了我们需要的代理mapper。而SqlSession中最重要的则是用来处理请求的Executor,在上一章中我们创建了SimpleExecutor,并使用CachingExecutor代理了一下,我们最终得到了CachingEecutor.本章我们主要研究代理mapper的执行过程。这里再贴一下之前的测试代码
@Autowired private SqlSessionFactory sqlSessionFactory; @GetMapping("/get") public List<AssetInfo> get(){ SqlSession sqlSession = sqlSessionFactory.openSession(); AssetInfoMapper mapper = sqlSession.getMapper(AssetInfoMapper.class); List<AssetInfo> test = mapper.get("测试删除" , "123123123"); System.out.println(test); return test; }
public interface AssetInfoMapper { List<AssetInfo> get(@Param("name") String name, @Param("id")String id); }
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.mapper.AssetInfoMapper">
<select id="get" resultType="com.entity.AssetInfo">
select * from asset_info where id =#{id} and `name` = #{name}
</select>
</mapper>
正文
1.MethodProxy
我们知道代理类最终执行的是我们实现了InvocationHandler接口里面的方法,而我们的创建mapper代理类传入的参数是MethodProxy,所以最终执行的也是这个类里面的invoke方法
//构建的SqlSession private final SqlSession sqlSession; //本mapper对应的接口 private final Class<T> mapperInterface; //方法缓存 里面存储的是方法的签名识别信息等 private final Map<Method, MapperMethod> methodCache; @Override public Object invoke(Object proxy, Method method, Object[] args) throws Throwable { try { //判断下是不是代理的Object类 if (Object.class.equals(method.getDeclaringClass())) { return method.invoke(this, args); } //如果是接口中的default方法 else if (method.isDefault()) { if (privateLookupInMethod == null) { return invokeDefaultMethodJava8(proxy, method, args); } else { return invokeDefaultMethodJava9(proxy, method, args); } } } catch (Throwable t) { throw ExceptionUtil.unwrapThrowable(t); } //如果是普通方法 我们主要分析这儿 这儿的主要目的是将方法的信息存起来 final MapperMethod mapperMethod = cachedMapperMethod(method); //执行其方法 return mapperMethod.execute(sqlSession, args); } //设置方法标志签名 private MapperMethod cachedMapperMethod(Method method) { return methodCache.computeIfAbsent(method, k -> new MapperMethod(mapperInterface, method, sqlSession.getConfiguration())); }
上面的invoke方法中做了一些判断,这儿我们主要分析下常规的方法调用。这儿有两步,第一步是创建我们调用的方法的签名mapperMethod并存储,第二部是调用mapperMethod的execute即执行方法。所以我们先看下是如何创建的方法签名。根据代码可以知道 如果method对应的mapperMethod不存在就调用其有参构造创建一个,所以我们主要看有参构造
public class MapperMethod { private final SqlCommand command; private final MethodSignature method; public MapperMethod(Class<?> mapperInterface, Method method, Configuration config) { //创建该方法的command this.command = new SqlCommand(config, mapperInterface, method); //创建该方法的MethodSignature this.method = new MethodSignature(config, mapperInterface, method); } ........... }
通过上面可以看到,该方法主要创建了两个属性,SqlCommand,MethodSignature。我可以得知后面的execute方法肯定也是围绕这两个属性展开的。我们逐个分析就可以知道它们的作用了
SqlCommand
public SqlCommand(Configuration configuration, Class<?> mapperInterface, Method method) { //获得方法名 例如get final String methodName = method.getName(); //获得方法声明的接口类型 final Class<?> declaringClass = method.getDeclaringClass(); //根据这个获取mybatis初始化时为xml中的每个方法构建的MappedStatement 里面主要存储该sql的信息 MappedStatement ms = resolveMappedStatement(mapperInterface, methodName, declaringClass, configuration); //如果未找到 if (ms == null) { //查看是否为有 @Flush注解 if (method.getAnnotation(Flush.class) != null) { name = null; //说明该方法只是用来刷新的 type = SqlCommandType.FLUSH; } else { throw new BindingException("Invalid bound statement (not found): " + mapperInterface.getName() + "." + methodName); } } else { //获取到该 MappedStatement的id 一般为接口名+'.'+方法名 name = ms.getId(); //获取到方法类型 select|update |delete type = ms.getSqlCommandType(); //如果未知直接抛异常 if (type == SqlCommandType.UNKNOWN) { throw new BindingException("Unknown execution method for: " + name); } } } private MappedStatement resolveMappedStatement(Class<?> mapperInterface, String methodName, Class<?> declaringClass, Configuration configuration) { //获取到该 MappedStatement的id 一般为接口名+'.'+方法名 String statementId = mapperInterface.getName() + "." + methodName; //如果有旧直接返回 if (configuration.hasStatement(statementId)) { return configuration.getMappedStatement(statementId); } //如果没有 但我们传入的接口和方法声明的接口是一个接口 就返回null else if (mapperInterface.equals(declaringClass)) { return null; } //否则有可能是我们的自己的接口继承了mapper的接口,所以找到其父接口(如果有)继续递归调用 for (Class<?> superInterface : mapperInterface.getInterfaces()) { if (declaringClass.isAssignableFrom(superInterface)) { MappedStatement ms = resolveMappedStatement(superInterface, methodName, declaringClass, configuration); if (ms != null) { return ms; } } } return null; }
通过上述代码可以得知SqlCommand主要存储了该方法的类型 | update |delete |select ,以及方法的全名,即声明的接口名+方法名,可能有同学发现了其信息来自于MappedStatment,而这个是根据我们构造的方法全名查到的。其实在第一张解析mapper.xml的过程即介绍xmlMapperBuilder中有提到在构建过程中最后一步为mapper中的每个sql方法构建了一个MappedStatment。这个类将会在后面频繁的用到,所以我们详细讲一下,希望大家仔细看。当时没有详细的讲构建过程,这儿就顺带说一下,我们回顾下那个方法
private void configurationElement(XNode context) { try { //获取该mapper的namespace的值 一般为接口地址 String namespace = context.getStringAttribute("namespace"); //判空 if (namespace == null || namespace.equals("")) { throw new BuilderException("Mapper's namespace cannot be empty"); } //设置当前处理的namespace builderAssistant.setCurrentNamespace(namespace); //设置当前nameSpace的缓存引用 cacheRefElement(context.evalNode("cache-ref")); //设置当前nameSpace的缓存 cacheElement(context.evalNode("cache")); //设置当前nameSpace的所有parameterMap parameterMapElement(context.evalNodes("/mapper/parameterMap")); //设置当前nameSpace的所有resultMap resultMapElements(context.evalNodes("/mapper/resultMap")); //设置当前nameSpace的所有sql语句 sqlElement(context.evalNodes("/mapper/sql")); //设置当前nameSpace 每个sql方法的方法类型 buildStatementFromContext(context.evalNodes("select|insert|update|delete")); } catch (Exception e) { throw new BuilderException("Error parsing Mapper XML. The XML location is '" + resource + "'. Cause: " + e, e); } }
最后一步的buildStatementFromContext方法即是构建方法
private void buildStatementFromContext(List<XNode> list) { if (configuration.getDatabaseId() != null) { buildStatementFromContext(list, configuration.getDatabaseId()); } buildStatementFromContext(list, null); } private void buildStatementFromContext(List<XNode> list, String requiredDatabaseId) { for (XNode context : list) { final XMLStatementBuilder statementParser = new XMLStatementBuilder(configuration, builderAssistant, context, requiredDatabaseId); try { statementParser.parseStatementNode(); } catch (IncompleteElementException e) { configuration.addIncompleteStatement(statementParser); } } }
上面又是很熟悉的创建构建器,然后调用构建器的parsexx方法,我们还是主要看parseStatementNode方法。 注意 该方法中的XNode属性就已经是我们每个方法的sql了。
public void parseStatementNode() { //获取到sql方法定义的id 一般对应接口中的方法名 String id = context.getStringAttribute("id"); //获取到sql方法定义的数据库id 多数据源时会用到 String databaseId = context.getStringAttribute("databaseId"); //如果这儿判断下如果有指定id 那当前数据源是否为指定id if (!databaseIdMatchesCurrent(id, databaseId, this.requiredDatabaseId)) { return; } //获取到该sql方法的名字即类型 |select | delete |update |insert String nodeName = context.getNode().getNodeName(); SqlCommandType sqlCommandType = SqlCommandType.valueOf(nodeName.toUpperCase(Locale.ENGLISH)); //设置是查询操作还是更新操作 boolean isSelect = sqlCommandType == SqlCommandType.SELECT; //是否刷新缓存 boolean flushCache = context.getBooleanAttribute("flushCache", !isSelect); //是否使用二级缓存 boolean useCache = context.getBooleanAttribute("useCache", isSelect); //返回结果是否排序 boolean resultOrdered = context.getBooleanAttribute("resultOrdered", false); // 解析sql方法中包含的节点 例如<if></if>等 XMLIncludeTransformer includeParser = new XMLIncludeTransformer(configuration, builderAssistant); includeParser.applyIncludes(context.getNode()); //获得参数类型 String parameterType = context.getStringAttribute("parameterType"); //获得参数类型对应的class信息 Class<?> parameterTypeClass = resolveClass(parameterType); //获取语言 String lang = context.getStringAttribute("lang"); LanguageDriver langDriver = getLanguageDriver(lang); //暂时不明确这句的作用 processSelectKeyNodes(id, parameterTypeClass, langDriver); // Parse the SQL (pre: <selectKey> and <include> were parsed and removed) KeyGenerator keyGenerator; // id +'!selectKey' String keyStatementId = id + SelectKeyGenerator.SELECT_KEY_SUFFIX; //namespace + id + '!selectKey' keyStatementId = builderAssistant.applyCurrentNamespace(keyStatementId, true); //获取到该方法的key即主键生成器 if (configuration.hasKeyGenerator(keyStatementId)) { keyGenerator = configuration.getKeyGenerator(keyStatementId); } else { keyGenerator = context.getBooleanAttribute("useGeneratedKeys", configuration.isUseGeneratedKeys() && SqlCommandType.INSERT.equals(sqlCommandType)) ? Jdbc3KeyGenerator.INSTANCE : NoKeyGenerator.INSTANCE; } //解析sql语句 这里面会将sql语句解析出来 并将#{xx} 替换为 ? 占位符 SqlSource sqlSource = langDriver.createSqlSource(configuration, context, parameterTypeClass); //获得statementType 默认为PREPARED 即预编译类型 StatementType statementType = StatementType.valueOf(context.getStringAttribute("statementType", StatementType.PREPARED.toString())); //影响期望值 Integer fetchSize = context.getIntAttribute("fetchSize"); //超时时间 Integer timeout = context.getIntAttribute("timeout"); //自定义的parameterMap String parameterMap = context.getStringAttribute("parameterMap"); //返回类型 String resultType = context.getStringAttribute("resultType"); //返回类型的class属性 Class<?> resultTypeClass = resolveClass(resultType); //自定义的返回resultMap String resultMap = context.getStringAttribute("resultMap"); //自定义的resultSetType String resultSetType = context.getStringAttribute("resultSetType"); ResultSetType resultSetTypeEnum = resolveResultSetType(resultSetType); if (resultSetTypeEnum == null) { resultSetTypeEnum = configuration.getDefaultResultSetType(); } //标记唯一属性 String keyProperty = context.getStringAttribute("keyProperty"); //生成的键值 设置列名 String keyColumn = context.getStringAttribute("keyColumn"); //多结果集时使用 String resultSets = context.getStringAttribute("resultSets"); //构建MappedStatement builderAssistant.addMappedStatement(id, sqlSource, statementType, sqlCommandType, fetchSize, timeout, parameterMap, parameterTypeClass, resultMap, resultTypeClass, resultSetTypeEnum, flushCache, useCache, resultOrdered, keyGenerator, keyProperty, keyColumn, databaseId, langDriver, resultSets); }
这个方法就是把sql方法所有的元素解析出来,然后使用builderAssistant.addMappedStatement方法把参数全部传进去 然后构建值,我们接着看
public MappedStatement addMappedStatement() { if (unresolvedCacheRef) { throw new IncompleteElementException("Cache-ref not yet resolved"); } //获取到该MappedStatement的id 这儿为namespace+'.'+id id = applyCurrentNamespace(id, false); //获得方法SqlCommandType boolean isSelect = sqlCommandType == SqlCommandType.SELECT; //构建者模式传入参数 MappedStatement.Builder statementBuilder = new MappedStatement.Builder(configuration, id, sqlSource, sqlCommandType) .resource(resource) .fetchSize(fetchSize) .timeout(timeout) .statementType(statementType) .keyGenerator(keyGenerator) .keyProperty(keyProperty) .keyColumn(keyColumn) .databaseId(databaseId) .lang(lang) .resultOrdered(resultOrdered) .resultSets(resultSets) .resultMaps(getStatementResultMaps(resultMap, resultType, id)) .resultSetType(resultSetType) .flushCacheRequired(valueOrDefault(flushCache, !isSelect)) .useCache(valueOrDefault(useCache, isSelect)) .cache(currentCache); ParameterMap statementParameterMap = getStatementParameterMap(parameterMap, parameterType, id); if (statementParameterMap != null) { //添加ParameterMap statementBuilder.parameterMap(statementParameterMap); } MappedStatement statement = statementBuilder.build(); //添加 configuration.addMappedStatement(statement); return statement; } protected final Map<String, MappedStatement> mappedStatements = new StrictMap<MappedStatement>("Mapped Statements collection") .conflictMessageProducer((savedValue, targetValue) -> ". please check " + savedValue.getResource() + " and " + targetValue.getResource()); public void addMappedStatement(MappedStatement ms) { mappedStatements.put(ms.getId(), ms); }
这个方法就获取到mappedStatment的id以及使用构建者模式构建系列参数,最终创建好后存储到Configuration中的mappedStatements 存储,key则为mappedStatment的id
到此 mappedStatment就创建好了并且成功存储
分析完了SqlCommand顺带分析了mappedStatment后我们接着分析MapperMethod中另一个属性 即MethodSignature的创建过程
MethodSignature
public MethodSignature(Configuration configuration, Class<?> mapperInterface, Method method) { //该方法返回类型 Type resolvedReturnType = TypeParameterResolver.resolveReturnType(method, mapperInterface); if (resolvedReturnType instanceof Class<?>) { this.returnType = (Class<?>) resolvedReturnType; } else if (resolvedReturnType instanceof ParameterizedType) { this.returnType = (Class<?>) ((ParameterizedType) resolvedReturnType).getRawType(); } else { this.returnType = method.getReturnType(); } //是否返回空 this.returnsVoid = void.class.equals(this.returnType); //是否返回多个数据 this.returnsMany = configuration.getObjectFactory().isCollection(this.returnType) || this.returnType.isArray(); //是否返回的是Cursor类型 this.returnsCursor = Cursor.class.equals(this.returnType); //是否返回的是Optional类型 this.returnsOptional = Optional.class.equals(this.returnType); //获取到mapKey 即@MapKey值 this.mapKey = getMapKey(method); //是否返回map this.returnsMap = this.mapKey != null; //参数中是否有RowBounds 即mybatis的分页工具类 this.rowBoundsIndex = getUniqueParamIndex(method, RowBounds.class); //是否有ResultHandler类 this.resultHandlerIndex = getUniqueParamIndex(method, ResultHandler.class); //获取到参数值 即@Param的值,如果有则为里面的value值 如果没有 则为'0','1','2'之类的 this.paramNameResolver = new ParamNameResolver(configuration, method); }
这个比较容易理解,就是解析了下该方法的参数信息之类的。
到此mapperMethod就创建完毕了。接下来就是执行其execute方法了
2.MapperMethod.execute()
该方法就是我们创建好mapperMethod后的重头戏方法了,也是我们调用代理类后最终要调用的方法
public Object execute(SqlSession sqlSession, Object[] args) { Object result; //查看方法类型 switch (command.getType()) { //插入 case INSERT: { //构建参数 Object param = method.convertArgsToSqlCommandParam(args); //执行 result = rowCountResult(sqlSession.insert(command.getName(), param)); break; } //修改 case UPDATE: { //构建参数 Object param = method.convertArgsToSqlCommandParam(args); //执行 result = rowCountResult(sqlSession.update(command.getName(), param)); break; } //删除 case DELETE: { //构建参数 Object param = method.convertArgsToSqlCommandParam(args); //执行 result = rowCountResult(sqlSession.delete(command.getName(), param)); break; } //查询 case SELECT: //如果返回为void 又有结果处理类 那就走这个方法 if (method.returnsVoid() && method.hasResultHandler()) { executeWithResultHandler(sqlSession, args); result = null; //返回多条数据 } else if (method.returnsMany()) { result = executeForMany(sqlSession, args); //返回map } else if (method.returnsMap()) { result = executeForMap(sqlSession, args); //返回多条数据Cursor } else if (method.returnsCursor()) { result = executeForCursor(sqlSession, args); } //返回单条普通数据 else { Object param = method.convertArgsToSqlCommandParam(args); //查询单条数据 result = sqlSession.selectOne(command.getName(), param); //如果返回Optional则包装一下 if (method.returnsOptional() && (result == null || !method.getReturnType().equals(result.getClass()))) { result = Optional.ofNullable(result); } } break; //刷新缓存类型 case FLUSH: result = sqlSession.flushStatements(); break; default: //直接抛异常 throw new BindingException("Unknown execution method for: " + command.getName()); } //如果返回null 而接收值时初始化数据类型 并且接收值不为void 那就抛异常 if (result == null && method.getReturnType().isPrimitive() && !method.returnsVoid()) { throw new BindingException("Mapper method '" + command.getName() + " attempted to return null from a method with a primitive return type (" + method.getReturnType() + ")."); } //返回结果 return result; }
本案例中中是select方法,并返回list,所以我们解析executeForMany(sqlSession, args); 其他查询操作大同小异,至于更新操作本文最后会讲解到。
3.executeForMany(sqlSession, args);
这儿主要是参数转换一下,然后调用SqlSession中的selectList方法 主要传入sqlCommand的id ,包装参数,分页信息。可见最终还是交由我们的SqlSession去执行了。所以又回到了我们上一章构建的DefaultSqlSession中去查询了
private <E> Object executeForMany(SqlSession sqlSession, Object[] args) { List<E> result; //参数转换一下 Object param = method.convertArgsToSqlCommandParam(args); //如果方法有分页类RowBounds if (method.hasRowBounds()) { RowBounds rowBounds = method.extractRowBounds(args); //分页查询 result = sqlSession.selectList(command.getName(), param, rowBounds); } else { //非分页查询 result = sqlSession.selectList(command.getName(), param); } // 由于结果都是Object 所以这儿需要转换下 增加数组支持 if (!method.getReturnType().isAssignableFrom(result.getClass())) { if (method.getReturnType().isArray()) { return convertToArray(result); } else { return convertToDeclaredCollection(sqlSession.getConfiguration(), result); } } return result; }
4.DefaultSqlSession.selectList()
这儿我们通过statementId拿到了我们上面构建的MappedStatement ,也就是标红了让大家注意看的地方。然后调用执行器查询,由于默认打开了二级缓存,所以根据上一章的步骤,这儿使用的是CachingExecutor,并且里面封装了SimpleExecutor
@Override public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) { try { //根据statementId拿到我们构建的MappedStatement 里面包含了该方法的所有xml解析出来的信息 MappedStatement ms = configuration.getMappedStatement(statement); //使用执行器 即CachingExecutor执行查询 return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER); } catch (Exception e) { throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e); } finally { ErrorContext.instance().reset(); } }
5.CachingExecutor.query()
@Override public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException { //拿到sql内容以及有关信息 BoundSql boundSql = ms.getBoundSql(parameterObject); //得到该方法缓存的key 这个key涉及到mybatis的一二级缓存 ,我们下一章讲缓存的时候将会着重讲 CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql); //继续执行重载方法 return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); }
上面的代码主要通过我们的参数拿到对应的BoundSql,里面包含了sql信息,参数信息等。然后通过一系列的参数创建了一个缓存key,这个在mybatis的缓存中起着非常重要的作用。我们下一章讲一二级缓存时将会着重讲。现在我们接着看重载方法
//这儿是SimpleExecutor private final Executor delegate; private final TransactionalCacheManager tcm = new TransactionalCacheManager(); @Override public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { //获取到该方法所在mapper的二级缓存 Cache cache = ms.getCache(); //如果缓存不为null if (cache != null) { //如果该方法需要刷新缓存则刷新二级缓存 flushCacheIfRequired(ms); //如果该方法使用缓存 且没有结果处理器 if (ms.isUseCache() && resultHandler == null) { //确定下参数类型 ensureNoOutParams(ms, boundSql); @SuppressWarnings("unchecked") //根据缓存获取数据 List<E> list = (List<E>) tcm.getObject(cache, key); //如果结果为空 则会调用实际的SimpleExecutor的query方法 //所以如果真实结果为空,那么二级缓存会失效 if (list == null) { list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); //二级缓存存入进去 tcm.putObject(cache, key, list); // issue #578 and #116 } //返回结果 return list; } } //SimpleExecutor的query方法 return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); }
这个方法则体现出了该代理执行器的作用,就是为了二级缓存。我们先接着看具体的查询方法即deletegate.query。这儿的delegate则是我们传入的SimpleExecutor。
6.BaseExecutor.query()方法
我们看下SimpleExecutor的结构,其继承了抽象类BaseExecutor。我们用的query方法则是在BaseExecutor中。
@SuppressWarnings("unchecked")
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
//检查该Executor即SqlSession是否关闭。
if (closed) {
throw new ExecutorException("Executor was closed.");
}
//如果查询的栈深度为0 并且该方法有刷新标志
if (queryStack == 0 && ms.isFlushCacheRequired()) {
//清除本地缓存 即一级缓存
clearLocalCache();
}
List<E> list;
try {
//查询栈深度+1
queryStack++;
//一级缓存查找结果 并且需要结果处理器为空
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
//不为null 但是该select为存储过程的话 执行下存储过程
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
//缓存为空,或者有结果处理器 则从数据库拿 并且数据存入一级缓存中
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
//查询栈深度-1
queryStack--;
}
//如果查询栈深度为0
if (queryStack == 0) {
//将队列中的 延迟重新加载任务加载
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
//清除队列
deferredLoads.clear();
//如果缓存配置是STATEMENT 即一次查询过程 那这个时候清空缓存
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
}
该方法则主要涉及到了一级缓存,由此可以看出二级缓存优先度高于一级缓存。我们接着看从数据库查询数据的逻辑。
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { List<E> list; //插入一个缓存预标识 此时缓存没有真实的结果 localCache.putObject(key, EXECUTION_PLACEHOLDER); try { //执行查询 list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql); } finally { //去掉预标识 localCache.removeObject(key); } //插入真正缓存结果 localCache.putObject(key, list); //如果该次调用是存储过程 if (ms.getStatementType() == StatementType.CALLABLE) { //存储过程参数里缓存这个参数 localOutputParameterCache.putObject(key, parameter); } //返回结果 return list; }
该方法也主要处理一些缓存,实际的调用由doQuery执行,doQuery是BaseExecutor的一个抽象方法,所以具体的实现是在SimpleExecutor中
7.SimpleExecutor.doQuery方法
@Override public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException { Statement stmt = null; try { //获取到该方法的Configuration Configuration configuration = ms.getConfiguration(); //生成一个声明处理器 StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql); //根据这个声明处理器和日志实现类型 来获取jdbc的处理器 stmt = prepareStatement(handler, ms.getStatementLog()); //调用我们创建的预编译处理器执行查询方法 return handler.query(stmt, resultHandler); } finally { closeStatement(stmt); } }
里面创建了两个比较重要的东西,声明处理器和jdbc标准的sql处理器。 我们分别看两个的创建逻辑,先看StatementHandler
public StatementHandler newStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) { //创建一个RoutingStatementHandler StatementHandler statementHandler = new RoutingStatementHandler(executor, mappedStatement, parameterObject, rowBounds, resultHandler, boundSql); //执行一次拦截器的方法 statementHandler = (StatementHandler) interceptorChain.pluginAll(statementHandler); return statementHandler; } private final StatementHandler delegate; public RoutingStatementHandler(Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) { switch (ms.getStatementType()) { case STATEMENT: delegate = new SimpleStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql); break; case PREPARED: delegate = new PreparedStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql); break; case CALLABLE: delegate = new CallableStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql); break; default: throw new ExecutorException("Unknown statement type: " + ms.getStatementType()); } }
通过上面的结果不难发现,虽然我们创建的是RoutingStatementHandler,但是通过其构造函数发现,这个statment只是一个路由的作用,最终的处理器肯定还是根据MappedStatement.getStatementType()决定的。这儿有三个类型从上到下分别是普通处理器,预编译处理器,存储过程处理器。这儿我们使用的则是预编译处理器,也是mybatis默认
还有一个需要注意的地方是这儿又执行了一个拦截器的方法,第一次是在我们创建SqlSession时构建Executor的地方执行过一次。并且都是执行的plugin方法
接下来我们看生成jdbc标准的处理器的逻辑prepareStatement(handler, ms.getStatementLog());
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException { Statement stmt; //获取到jdbc连接 这儿是通过的SpringDataSourceManager Connection connection = getConnection(statementLog); //预编译 最终由BaseStatementHandler执行 (PreparedStatementHandler未实现该方法) stmt = handler.prepare(connection, transaction.getTimeout()); //设置参数 最终由PreparedStatementHandler中的parameterHandler执行 handler.parameterize(stmt); return stmt; }
这段代码相信熟悉jdbc的同学都了解,是在进行java的原生sql连接步骤,即加载驱动获取连接,预编译,设置参数,还有执行,获取结果与释放连接,由于本案例使用的是连接池,所以我们主要关注后面的执行方法了。前面三个步骤也不细讲了,感兴趣的可以去了解下jdbc原生开发步骤即可
8.PreparedStatementHandler.query方法
由于RoutingStatementHandler最终会选择到我们的预执行处理器,所以最终处理器的也就是PreparedStatementHandler.query方法。我们就来分析这个方法
@Override public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException { PreparedStatement ps = (PreparedStatement) statement; ps.execute(); return resultSetHandler.handleResultSets(ps); }
在7中我们已经执行了jdbc中前几个步骤,到这儿直接执行execute方法,jdbc会将sql发送到数据库上,我们则只需要获取返回结果即可,到这儿其实我们的sql就已经执行完毕了,接下来需要做的就是处理返回结果。在看结果前我们先这个resultSetHandler是如何生成的。在该类的构造函数中有这样的逻辑
this.resultSetHandler = configuration.newResultSetHandler(executor, mappedStatement, rowBounds, parameterHandler, resultHandler, boundSql);
可见这个结果处理器是根据我们这个方法的一系列标识来创建的。
public ResultSetHandler newResultSetHandler(Executor executor, MappedStatement mappedStatement, RowBounds rowBounds, ParameterHandler parameterHandler, ResultHandler resultHandler, BoundSql boundSql) { //创建默认的结果处理器 ResultSetHandler resultSetHandler = new DefaultResultSetHandler(executor, mappedStatement, parameterHandler, resultHandler, boundSql, rowBounds); //执行一次拦截器方法 resultSetHandler = (ResultSetHandler) interceptorChain.pluginAll(resultSetHandler); return resultSetHandler; }
创建了一个默认的结果处理器,并且第三次执行了拦截器的plugin方法。我们接着看最后的方法,即结果封装
9.DefaultResultSetHandler.handleResultSets()
@Override public List<Object> handleResultSets(Statement stmt) throws SQLException { ErrorContext.instance().activity("handling results").object(mappedStatement.getId()); //创建集合搜集 final List<Object> multipleResults = new ArrayList<>(); int resultSetCount = 0; //获取到第一个返回结果并包装返回 ResultSetWrapper rsw = getFirstResultSet(stmt); //获取到所有的resultMap List<ResultMap> resultMaps = mappedStatement.getResultMaps(); //获取到ResultMap的数量 int resultMapCount = resultMaps.size(); //验证下有效的数量 即 不能小于1 validateResultMapsCount(rsw, resultMapCount); // while (rsw != null && resultMapCount > resultSetCount) { //获取到当前的resultMap ResultMap resultMap = resultMaps.get(resultSetCount); //将结果存入multipleResults handleResultSet(rsw, resultMap, multipleResults, null); //获取下一个结果 rsw = getNextResultSet(stmt); //清除下缓存 cleanUpAfterHandlingResultSet(); resultSetCount++; } //如果方法多个结果集的情况 String[] resultSets = mappedStatement.getResultSets(); if (resultSets != null) { // 分别设置其对应的值 while (rsw != null && resultSetCount < resultSets.length) { ResultMapping parentMapping = nextResultMaps.get(resultSets[resultSetCount]); if (parentMapping != null) { String nestedResultMapId = parentMapping.getNestedResultMapId(); ResultMap resultMap = configuration.getResultMap(nestedResultMapId); handleResultSet(rsw, resultMap, null, parentMapping); } //获取下一个值 rsw = getNextResultSet(stmt); cleanUpAfterHandlingResultSet(); resultSetCount++; } } return collapseSingleResultList(multipleResults); }
上面则是做了一些判断,然后根据我们定义的ResultMap,或者ResultType 和ResultSet分情况进行封装,由于具体的结果集封装过程非常的长以及篇幅有限,本系列文主要讲解mybatis的原理和流程,所以对具体的封装过程就不详细分析了。
10 有关更新操作
由于delete,update,insert都属于更新操作,最后都会调用相同的方法,所以这儿一并讲解,其实更新操作相比查询操作去掉了结果封装的一步,增加了清空缓存,以及标记修改的功能。其他的步骤一致,所以我只分析几个特别的地方。
10.1 DefaultSqlSession.update 增加修改操作标记
@Override public int update(String statement, Object parameter) { try { //本次SqlSession已出现过修改操作 dirty = true; MappedStatement ms = configuration.getMappedStatement(statement); return executor.update(ms, wrapCollection(parameter)); } catch (Exception e) { throw ExceptionFactory.wrapException("Error updating database. Cause: " + e, e); } finally { ErrorContext.instance().reset(); } }
10.2CachingExecutor.update()清空二级缓存
@Override public int update(MappedStatement ms, Object parameterObject) throws SQLException { flushCacheIfRequired(ms); return delegate.update(ms, parameterObject); } private void flushCacheIfRequired(MappedStatement ms) { Cache cache = ms.getCache(); //更新操作isFlushCacheRequired 即sql方法中的flushCache默认标记为true if (cache != null && ms.isFlushCacheRequired()) { //清空二级缓存 tcm.clear(cache); } }
10.3BaseExecutor.update 清空一级缓存
@Override public int update(MappedStatement ms, Object parameter) throws SQLException { ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId()); if (closed) { throw new ExecutorException("Executor was closed."); } //清除一级缓存 clearLocalCache(); return doUpdate(ms, parameter); } @Override public void clearLocalCache() { if (!closed) { localCache.clear(); localOutputParameterCache.clear(); } }
特殊步骤已做说明,其他的和查询操作一致,相信查询操作理解了修改操作很快也就能理解。不过由于我们创建的DefaultSqlSession的autocommit默认为false,所以有更新操作,需要手动提交事务。我们可以看下事务代码即SqlSession.commit()方法
@Override public void commit(boolean force) { try {
//判断下是否有改动 或者强制提交 然后再commit executor.commit(isCommitOrRollbackRequired(force)); dirty = false; } catch (Exception e) { throw ExceptionFactory.wrapException("Error committing transaction. Cause: " + e, e); } finally { ErrorContext.instance().reset(); } }
提交后本次SqlSession的修改操作又置为false,使用Executor进行提交
@Override public void commit(boolean required) throws SQLException { //清空缓存并提交事务 delegate.commit(required); //清空二级缓存 tcm.commit(); }
我们看最后调用的是BaseExecutor.commit()方法
@Override public void commit(boolean required) throws SQLException { if (closed) { throw new ExecutorException("Cannot commit, transaction is already closed"); } //清空一级缓存 clearLocalCache(); //刷新 flushStatements(); //如果本次操作有必要提交(有改动 或者自动提交设置为true) 或者强制提交再提交事务 if (required) { //我们使用的是SpringManagedTransaction 进行事务提交 transaction.commit(); } }
系统会先判断是否有必要提交(有改动 或者自动提交设置为true) 或者强制提交再提交事务,
完结
现在我们已经成功的通过代理类的方法调用SqlSession中的查找方法,而SqlSession在拿到方法对应的MappedStatment后交由其Executor执行具体的查询方法,中间会涉及到拦截器已即缓存,这个我会在后面专门的章节分析。
提供一张我整理的查询操作的图作为流程思路参考,有完整的从代理类开始调用的逻辑。修改操作原理类