安装Spark与Python代码练习
1.基础环境--环境准备检查
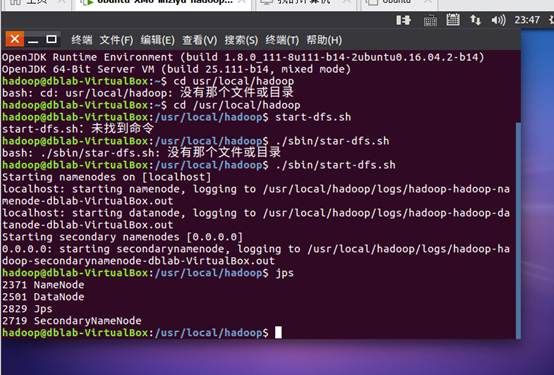
2.环境变量


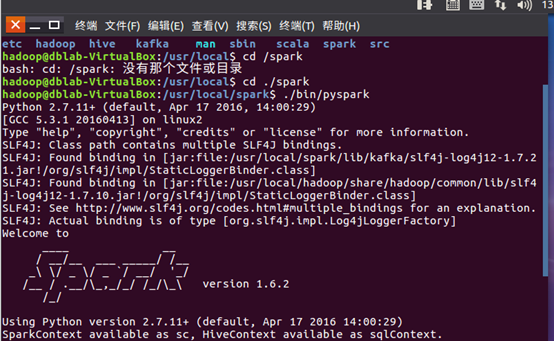
3.运行pyspark
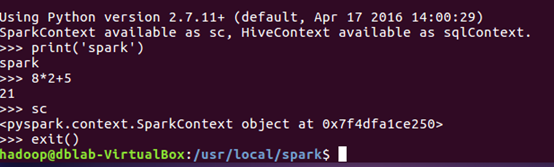
4.python代码测试
二、Python编程练习:英文文本的词频统计
1.准备文本文件
通过终端命令创建文件,一个放英文内容,一是python代码文件
2.读文件
# 1 获取文本 f = open("这里修改为你要读取文件的地址", "r",encoding='UTF-8') txt = f.read() txt = txt.lower() # 将所有字符转换为小写 f.close()
3.划分单词
# 2 划分单词 array = re.split('[ ,.\n]', txt) #print('分词结果',array)
4.词频统计
# 3 词频统计 dic = {} for i in array: if i not in dic: dic[i] = 1 else: dic[i] += 1
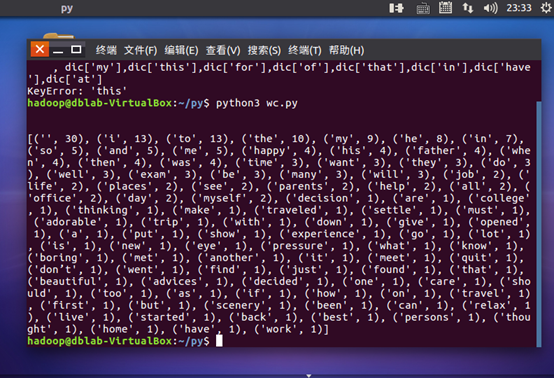
5.输出出现频率最高的100个单词
print('\n') print(order_dict1(dic, 100),)
6.完整代码
import os import re def order_dict(dicts, n): result = [] result1 = [] p = sorted([(k, v) for k, v in dicts.items()], reverse=True) s = set() for i in p: s.add(i[1]) for i in sorted(s, reverse=True)[:n]: for j in p: if j[1] == i: result.append(j) for r in result: result1.append(r[0]) return result1 def order_dict1(dicts, n): # 截取排序结果想要的部分返回就好了 list1 = sorted(dicts.items(), key=lambda x: x[1]) return list1[-1:-(n + 1):-1] # return list1[-2:-(n+2):-1] #去除统计结果为""的情况(前面步骤中,字典没有提前""去掉的情况下) if __name__ == "__main__": # 1 获取文本 f = open("这里修改为你要读取文件的地址", "r",encoding='UTF-8') txt = f.read() txt = txt.lower() # 将所有字符转换为小写 f.close() # 2 划分单词 array = re.split('[ ,.\n]', txt) #print('分词结果',array) # 3 词频统计 dic = {} for i in array: if i not in dic: dic[i] = 1 else: dic[i] += 1 # 4 输出出现频率最高的100个单词 print('\n') print(order_dict1(dic, 100),)
7.结果