自己搭建专属AI:Llama大模型私有化部署
前言
AI新时代,提高了生产力且能帮助用户快速解答问题,现在用的比较多的是Openai、Claude,为了保证个人隐私数据,所以尝试本地(Mac M3)搭建Llama模型进行沟通。
Gpt4all
安装比较简单,根据 https://github.com/nomic-ai/gpt4all 下载客户端软件即可,打开是这样的:

然后选择并下载模型文件,这里以Llama为例:
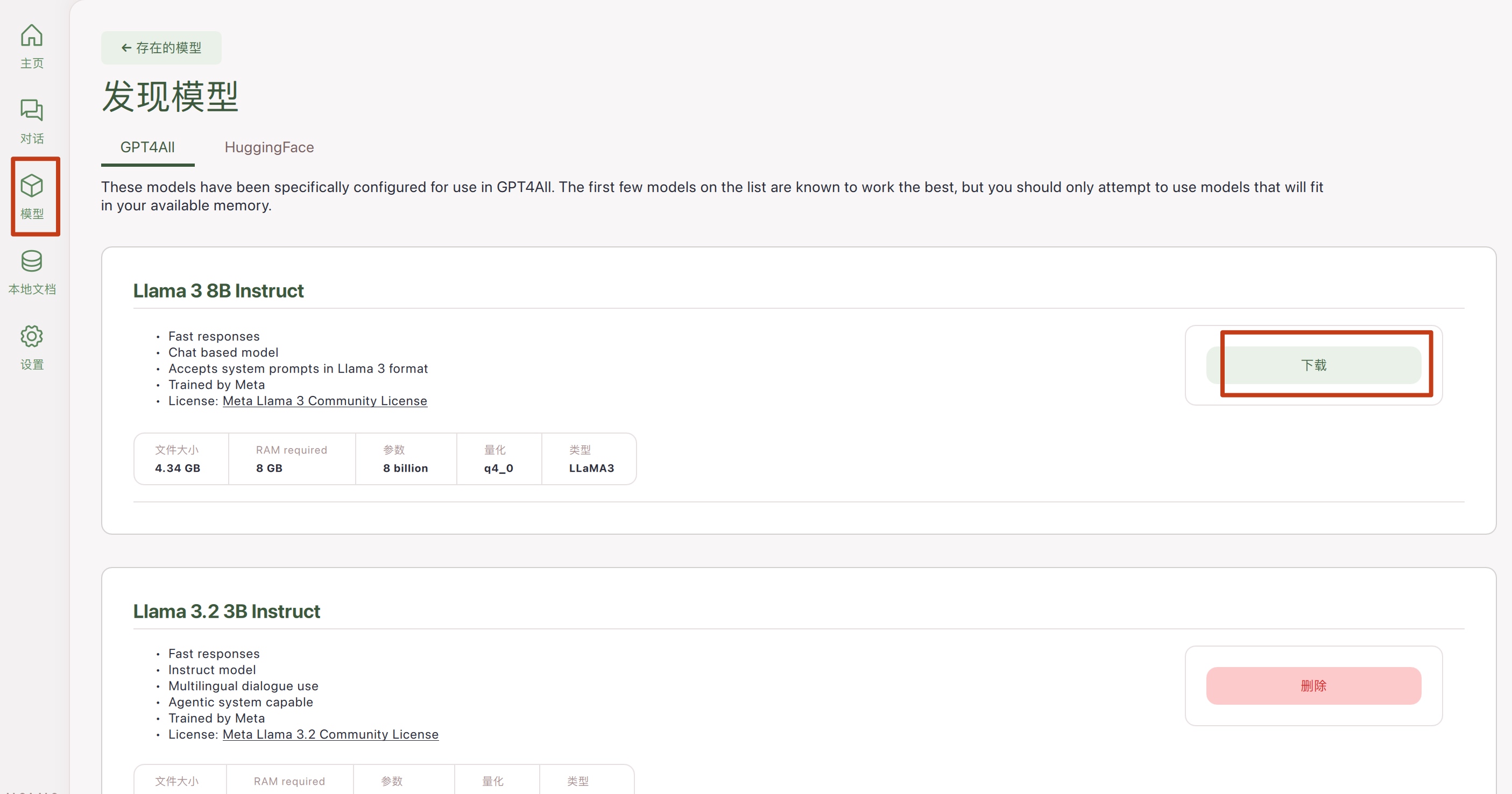
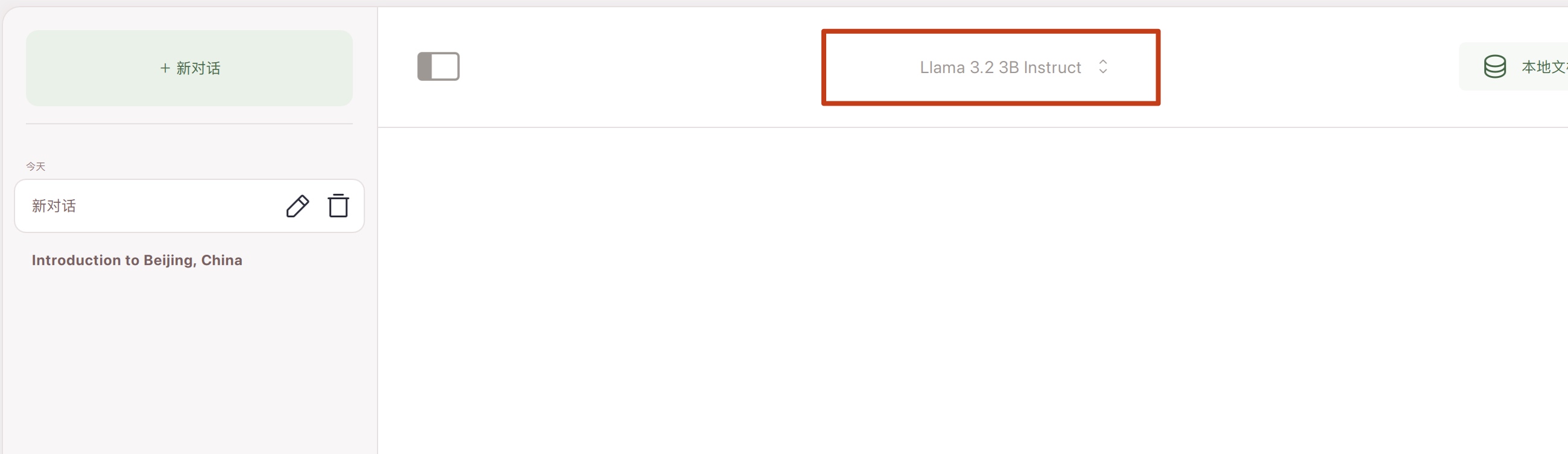
下载模型文件完,选择模型文件则可以进行对话了:
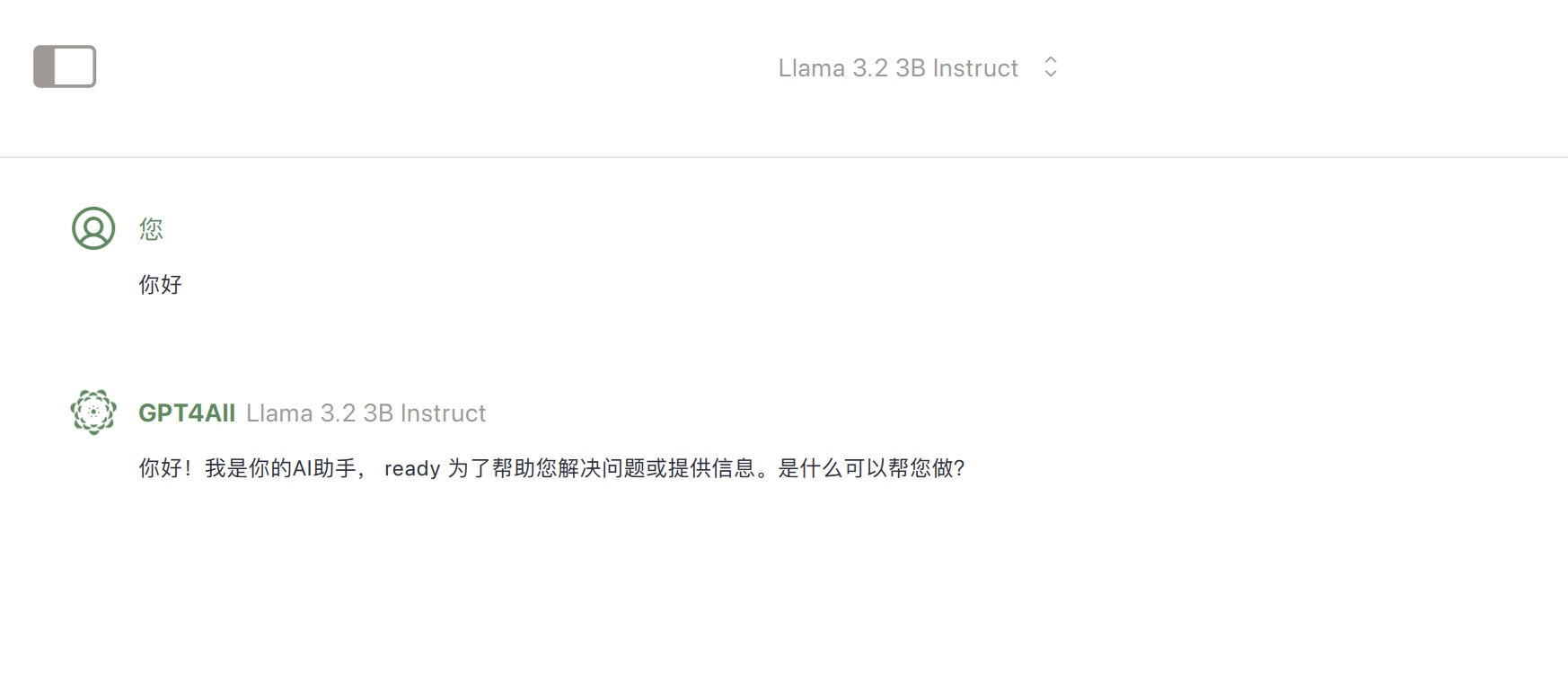
也可以利用基于 nomic-embed-text嵌入模型,把文档转成向量方便语义检索和匹配。选择文档所在的目录:

然后对话中选择对应的文档即可:
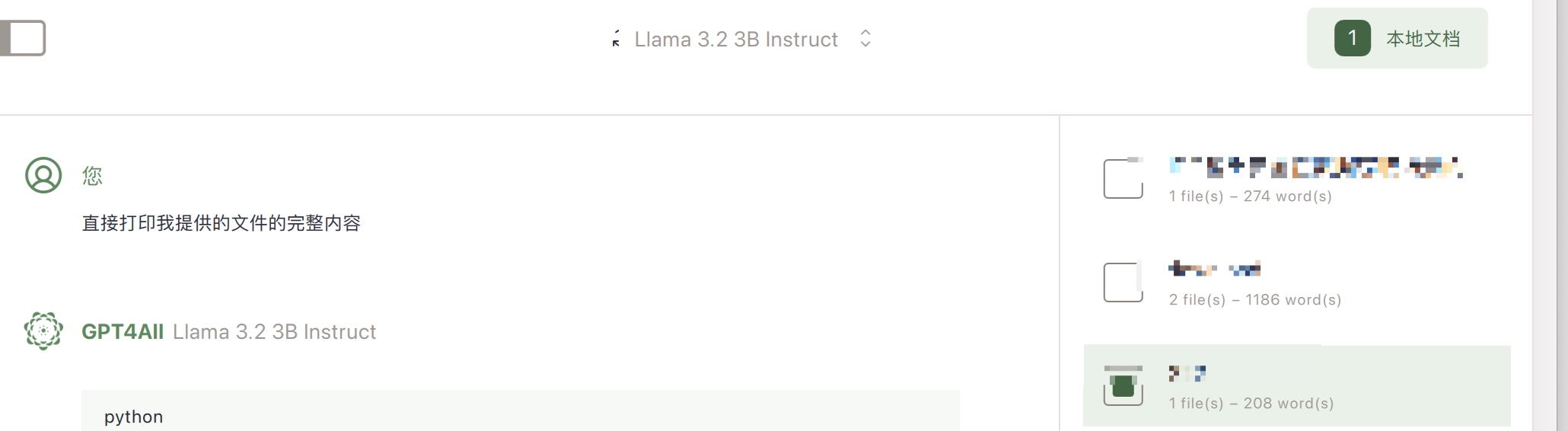
如果文件太大,需要在设置适当添加token大小,太大也不好,处理会慢且机器会卡死:

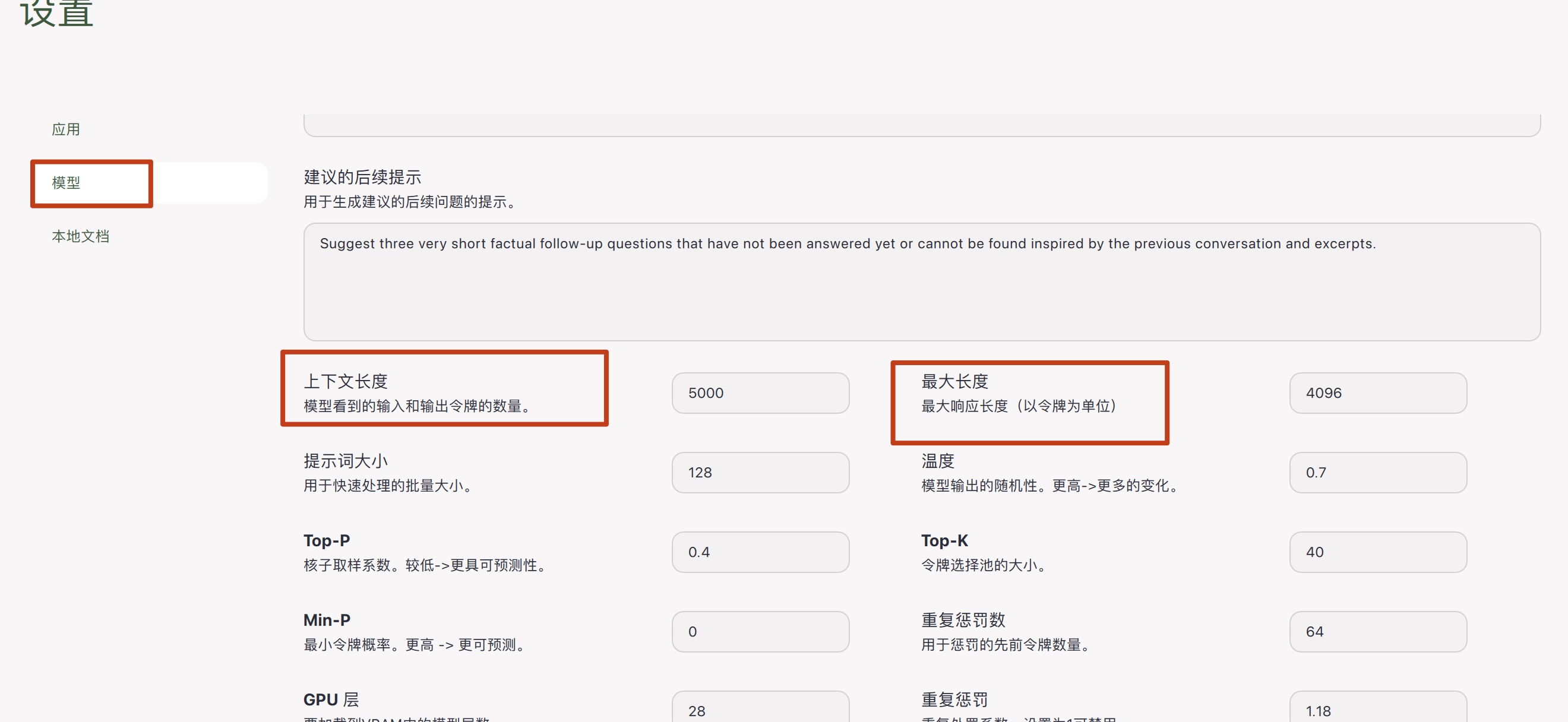
gpt4all使用起来还是比较方便的,但是有几个缺点:有些能在huggingface.co搜到的模型在gpt4all上面搜不到、退出应用后聊天记录会消失。
【----帮助网安学习,以下所有学习资料免费领!加vx:dctintin,备注 “博客园” 获取!】
① 网安学习成长路径思维导图
② 60+网安经典常用工具包
③ 100+SRC漏洞分析报告
④ 150+网安攻防实战技术电子书
⑤ 最权威CISSP 认证考试指南+题库
⑥ 超1800页CTF实战技巧手册
⑦ 最新网安大厂面试题合集(含答案)
⑧ APP客户端安全检测指南(安卓+IOS)
Ollama
安装也很方便,下载 https://ollama.com/download/Ollama-darwin.zip ,然后运行如下命令即可启动Llama:
ollama run llama3.2
为了方便图形化使用,可以借助 https://github.com/open-webui/open-webui 完整图形化的使用,启动也很简单,直接使用官方仓库中的命令即可:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main然后访问本地的3000端口即可:

open-webui的原理也比较简单,Ollama启动后会在本地监听11434端口,open-webui也是利用这个端口来和Ollama通信完成的图形化使用。open-webui还可以多选模型一起回答:
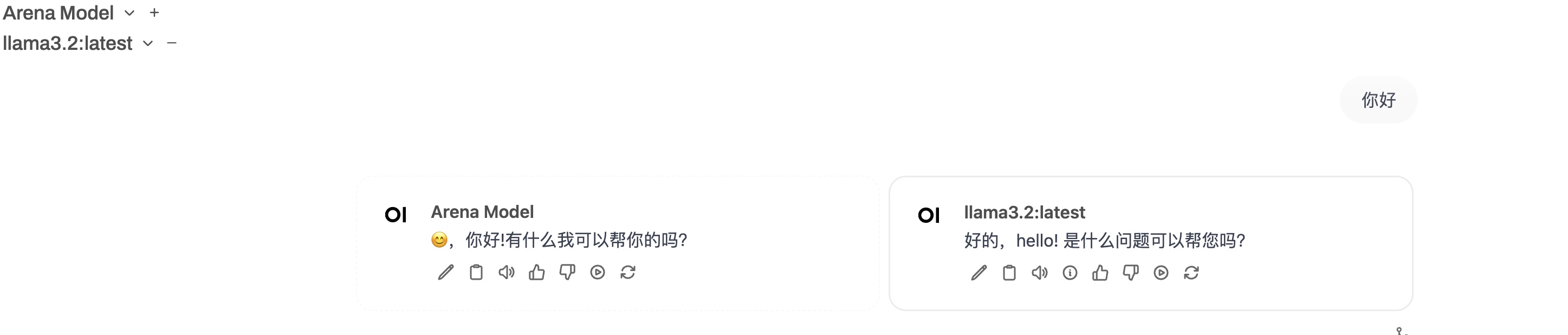
整体测试下来,发现Llama3.2对于文档分析差点意思,给他提供一个pdf文档,也看不出个啥来。但是上面的gpt4all,然后通过nomic-embed-text模型嵌入后好点。
总结
本文演示了通过不同手段来运行Llama模型,来达到本地使用LLM的目的。
更多网安技能的在线实操练习,请点击这里>>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号