深度学习后门攻击分析与实现(二)
前言
在本系列的第一部分中,我们已经掌握了深度学习中的后门攻击的特点以及基础的攻击方式,现在我们在第二部分中首先来学习深度学习后门攻击在传统网络空间安全中的应用。然后再来分析与实现一些颇具特点的深度学习后门攻击方式。
深度学习与网络空间安全的交叉
深度学习作为人工智能的一部分,在许多领域中取得了显著的进展。然而,随着其广泛应用,深度学习模型的安全性也引起了广泛关注。后门攻击就是其中一种重要的威胁,尤其在网络空间安全领域中。
我们已经知道深度学习后门攻击是一种攻击者通过在训练过程中插入恶意行为,使得模型在特定的触发条件下表现异常的攻击方式。具体来说,攻击者在训练数据集中加入带有后门触发器的样本,使得模型在遇到类似的触发器时,产生攻击者期望的错误输出,而在正常情况下,模型仍能表现出高准确率。这种隐蔽性和针对性使得后门攻击非常难以检测和防御。
现在我们举几个例子介绍后门攻击在网络空间安全中的应用场景。
恶意软件检测:在网络安全中,恶意软件检测是一个重要应用。攻击者可以通过后门攻击技术,使得恶意软件检测模型在检测特定样本时失效。例如,攻击者可以在训练恶意软件检测模型时插入带有后门的恶意样本,使得模型在检测带有特定触发器的恶意软件时无法正确识别,从而达到隐蔽恶意软件的目的。
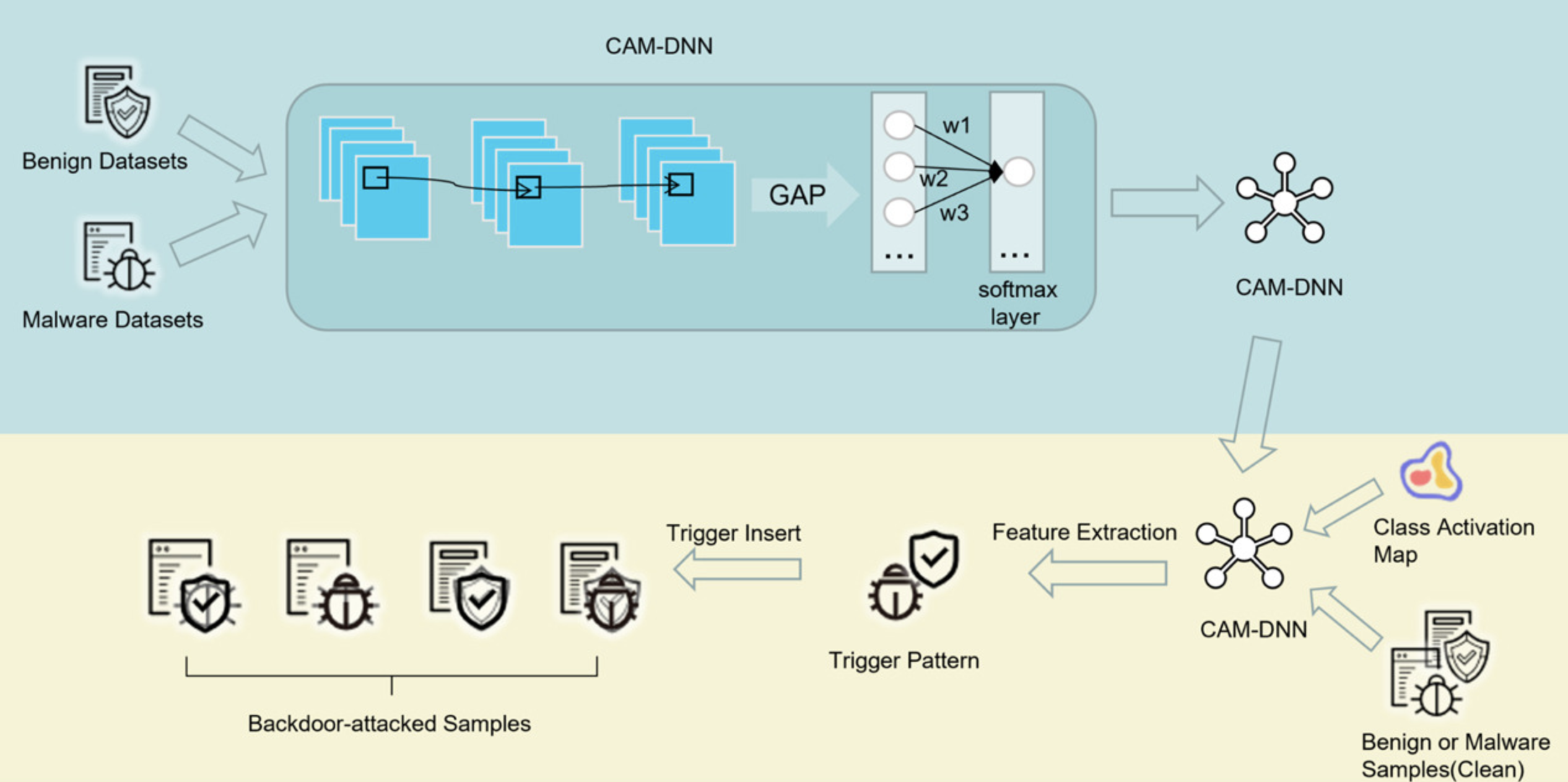
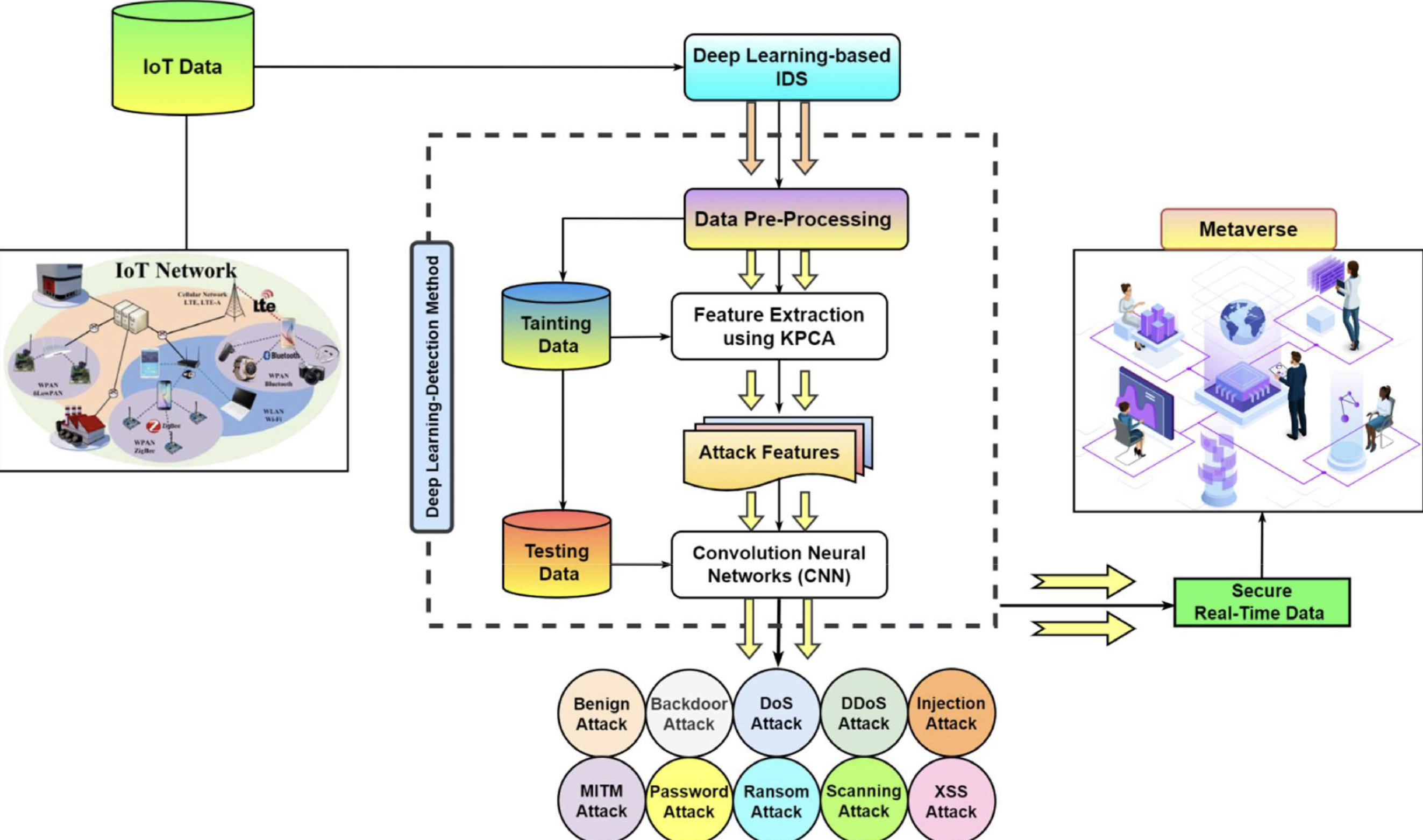
入侵检测系统:入侵检测系统(Intrusion Detection System, IDS)用于监测网络流量并识别潜在的入侵行为。攻击者可以在训练IDS模型时加入后门触发器,使得模型在特定条件下无法识别攻击流量。例如,攻击者可以在训练数据中插入带有特定模式的正常流量,使得模型在检测到这些模式时误判为正常,从而绕过入侵检测系统。
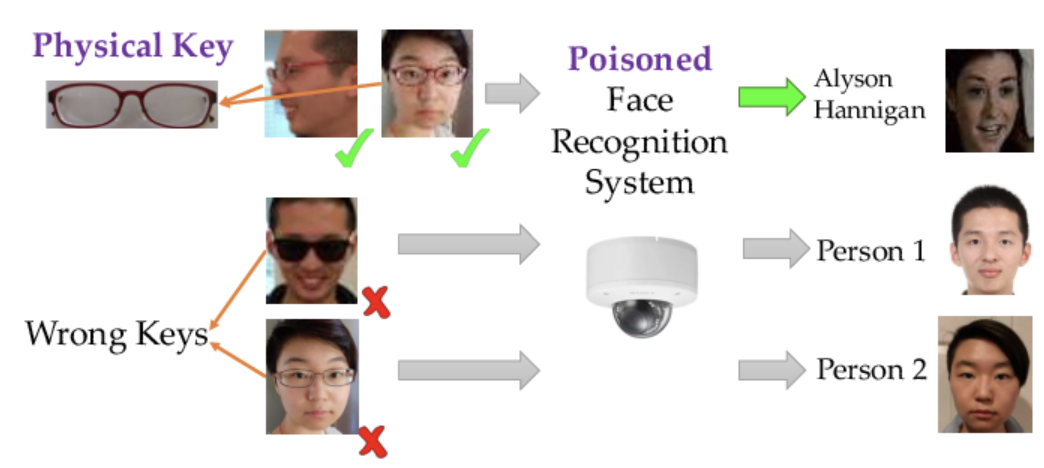
图像识别安全:在网络空间安全中,图像识别技术被广泛应用于身份验证和监控系统中。攻击者可以利用后门攻击,在训练图像识别模型时插入带有后门的图像样本,使得模型在识别带有特定触发器的图像时出现误判。例如,攻击者可以使得带有特定标志的非法图像被识别为合法,从而绕过安全监控系统。
可见后门攻击与网络空间安全其他领域还是存在不少交叉的。
现在我们继续来分析并实现、复现典型的深度学习后门攻击方法。
BppAttack
理论
这篇工作提出了一种名为BPPATTACK的深度神经网络(DNN)木马攻击方法。该攻击利用了人类视觉系统对图像量化和抖动处理不敏感的特性,通过这些技术生成难以被人类察觉的触发器,进而实现对DNN的高效、隐蔽的木马攻击。
现有的攻击使用可见模式(如图像补丁或图像变换)作为触发器,这些触发器容易受到人类检查的影响。比如下图就可以看到很明显的触发器。

BPPATTACK方案的核心思想是利用人类视觉系统对图像微小变化的不敏感性,通过图像量化和抖动技术生成难以被人类察觉的触发器,实现对深度神经网络(DNN)的高效、隐蔽的木马攻击。
人类视觉系统对颜色深度的变化不是特别敏感,特别是当颜色变化非常微小的时候。BPPATTACK正是基于这一生物学原理,通过调整图像的颜色深度来生成触发器。
-
图像量化(Bit-Per-Pixel Reduction):
-
图像量化是减少图像中每种颜色的比特数,从而减少图像的总颜色数量。BPPATTACK通过降低每个像素的比特深度,使用量化后的最近邻颜色值来替换原始颜色值,实现对图像的微小修改。
-
-
抖动技术(Dithering):
-
为了消除由于颜色量化引起的不自然或明显的图像伪影,BPPATTACK采用抖动技术,特别是Floyd-Steinberg抖动算法,来平滑颜色过渡,提高图像的自然度和视觉质量。
BPPATTACK旨在生成一种触发器,它对人类观察者来说是几乎不可察觉的,但对机器学习模型来说足够显著,能够触发预设的木马行为。这种平衡是通过精确控制量化和抖动的程度来实现的。
-
与需要训练额外的图像变换模型或自编码器的攻击不同,BPPATTACK不需要训练任何辅助模型,这简化了攻击流程并提高了效率。
-
为了提高攻击的成功率和隐蔽性,BPPATTACK采用了对比学习和对抗性训练的结合。通过这种方式,模型被训练来识别和利用量化和抖动生成的触发器,同时忽略其他不重要的特征。
-
量化过程涉及将原始图像的颜色深度从( m )位减少到( d )位(( d < m ))。对于每个像素值,使用以下公式进行量化:
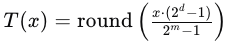
其中:
-
( T(x) ) 是量化后的像素值。
-
( x ) 是原始像素值。
-
( m ) 是原始颜色深度的位数(每个通道)。
-
( d ) 是量化后的目标颜色深度的位数。
-
( \text{round} ) 是四舍五入到最近的整数。
Floyd-Steinberg Dithering:抖动算法用于改善量化后的图像质量,通过将量化误差扩散到邻近像素。对于每个像素,计算量化误差并更新周围像素:
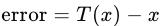
然后,根据Floyd-Steinberg分布,更新当前像素和周围像素:

BPPATTACK方案的关键在于通过量化和抖动技术生成的微小变化对人类视觉系统是不可见的,但对DNN模型是可区分的,从而实现隐蔽的木马攻击。
【----帮助网安学习,以下所有学习资料免费领!加vx:dctintin,备注 “博客园” 获取!】
① 网安学习成长路径思维导图
② 60+网安经典常用工具包
③ 100+SRC漏洞分析报告
④ 150+网安攻防实战技术电子书
⑤ 最权威CISSP 认证考试指南+题库
⑥ 超1800页CTF实战技巧手册
⑦ 最新网安大厂面试题合集(含答案)
⑧ APP客户端安全检测指南(安卓+IOS)
实现
我们来看看该方法得到的部分中毒样本



分析关键函数
-
Bpp类:继承自BadNet,添加了命令行参数处理和数据集准备功能,用于特定处理阶段。 -
set_bd_args方法:配置与攻击设置相关的命令行参数。 -
stage1_non_training_data_prepare方法:准备和变换数据集,设置 DataLoader,并存储阶段 1 的结果。
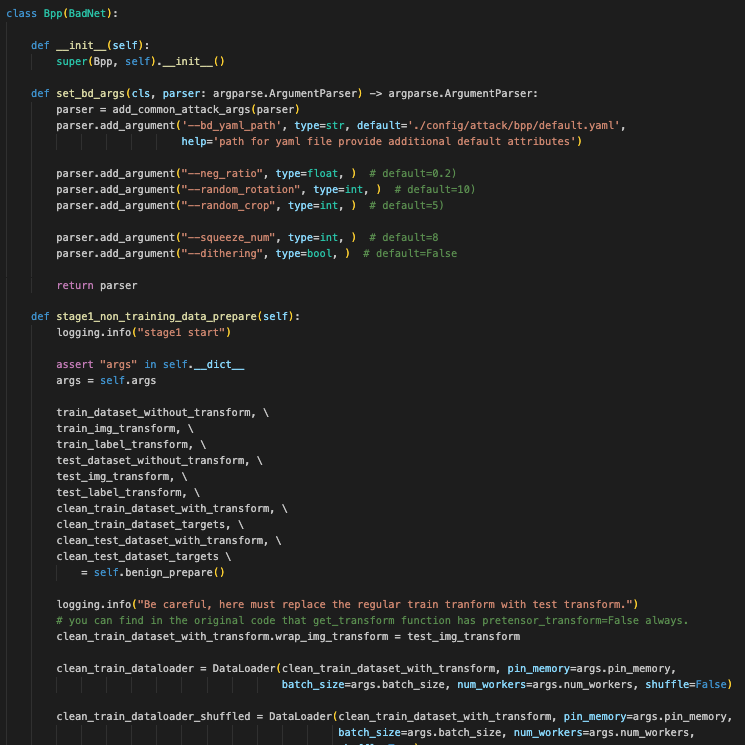
1. 类定义与初始化
-
类声明:
-
class Bpp(BadNet):Bpp是BadNet的一个子类。
-
-
构造函数 (
__init__方法):-
def __init__(self):: 这是Bpp的初始化方法。 -
super(Bpp, self).__init__(): 调用父类BadNet的构造函数,以确保执行父类中的初始化逻辑。
-
2. 设置命令行参数
-
set_bd_args方法:-
def set_bd_args(cls, parser: argparse.ArgumentParser) -> argparse.ArgumentParser:: 这个类方法用于使用argparse库设置命令行参数。 -
parser = add_common_attack_args(parser): 调用add_common_attack_args函数,添加与攻击相关的常见参数。 -
parser.add_argument(...): 添加各种命令行参数:-
--bd_yaml_path: 指定一个 YAML 文件的路径,用于提供额外的默认属性。 -
--neg_ratio,--random_rotation,--random_crop,--squeeze_num,--dithering: 各种与攻击配置相关的参数,如负比率、旋转、裁剪、压缩和抖动。
-
-
-
返回值:
-
返回更新后的
parser对象,其中包含所有添加的参数。
-
3. 准备第一阶段的数据
-
stage1_non_training_data_prepare方法:-
def stage1_non_training_data_prepare(self):: 这个方法用于准备第一阶段的数据。 -
日志记录与断言:
-
logging.info("stage1 start"): 记录阶段 1 的开始。 -
assert "args" in self.__dict__: 确保args属性存在于实例中。
-
-
数据集准备:
-
train_dataset_without_transform,train_img_transform,train_label_transform, 等变量:这些变量被赋值为调用self.benign_prepare()的结果,该方法用于准备数据集和变换。 -
clean_train_dataset_with_transform.wrap_img_transform = test_img_transform: 将训练数据集的图像变换更新为与测试数据集的图像变换一致。
-
-
DataLoader 初始化:
-
clean_train_dataloader: 一个用于清洁训练数据集的 DataLoader,应用了变换。 -
clean_train_dataloader_shuffled: 一个用于清洁训练数据集的 DataLoader,但数据是打乱的。 -
clean_test_dataloader: 一个用于清洁测试数据集的 DataLoader。
-
-
-
存储结果:
-
self.stage1_results: 存储各种数据集和 DataLoader 以备阶段 1 进一步使用。
-
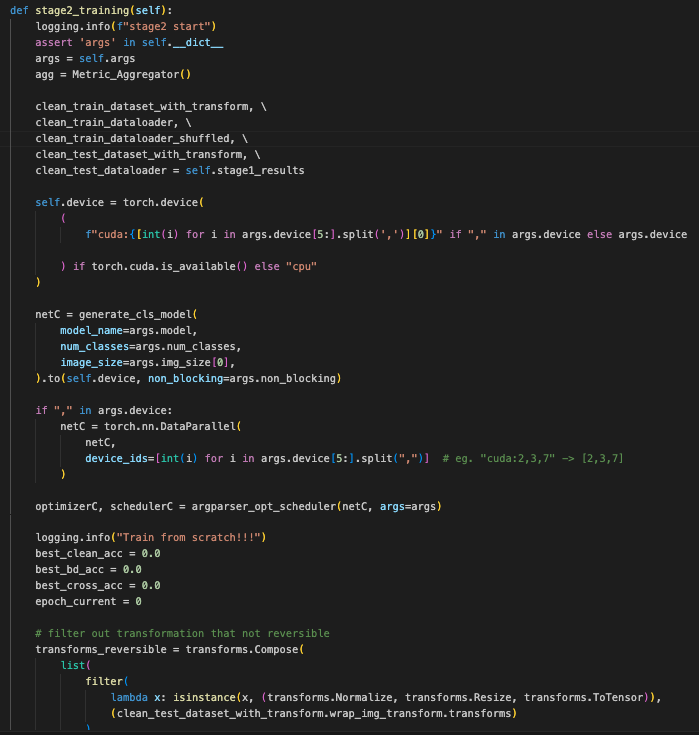
这段代码是一个神经网络训练和评估的流程,具体针对的是后门攻击(backdoor attack)的研究
-
初始化:
-
代码开始时,记录训练阶段2的开始时间。
-
通过断言检查
self对象中是否包含args属性,获取训练参数。
-
-
设备选择:
-
根据是否有可用的 GPU 来设置计算设备。如果
args.device包含多个设备(例如"cuda:2,3,7"),则使用torch.nn.DataParallel来并行计算。
-
-
模型生成:
-
调用
generate_cls_model函数生成分类模型netC,并将其移动到指定的设备上。
-
-
优化器和学习率调度器:
-
调用
argparser_opt_scheduler函数获取优化器和学习率调度器。
-
-
数据预处理:
-
过滤出可逆的图像变换(如标准化、缩放、转换为张量)。
-
创建干净和背门攻击的数据集,分别保存处理后的数据集。
-
-
训练数据处理:
-
遍历干净训练数据,通过反归一化得到原始图像。
-
根据攻击标签转换类型("all2one" 或 "all2all")来生成背门攻击数据。
-
处理数据集中的每一批次,并将干净样本和背门样本保存到数据集中。
-
-
测试数据处理:
-
对测试数据进行类似的预处理和保存操作,包括处理干净测试数据和背门测试数据。
-
评估背门效果,并根据攻击标签转换类型生成相应的标签和数据。
-
-
负样本生成:
-
如果指定了负样本比率(
neg_ratio),生成负样本数据。这些负样本用于评估背门攻击的效果。 -
将负样本与其他数据合并,并保存处理后的数据。
-
-
模型训练和评估:
-
对每个 epoch 执行训练和评估步骤。记录训练损失、准确率、背门攻击成功率等指标。
-
将每个 epoch 的训练和测试结果保存到列表中,并绘制训练和测试指标的图表。
-
-
模型保存和结果输出:
-
在训练周期结束时保存模型状态、学习率调度器状态、优化器状态等。
-
将训练和测试结果保存到 CSV 文件中,并生成最终的攻击结果数据。
-
-
完成:
-
输出“done”表示训练和保存过程已完成。
-
每个步骤都有明确的目标,从数据处理到模型训练,再到最终结果保存,涵盖了整个训练和评估的过程。
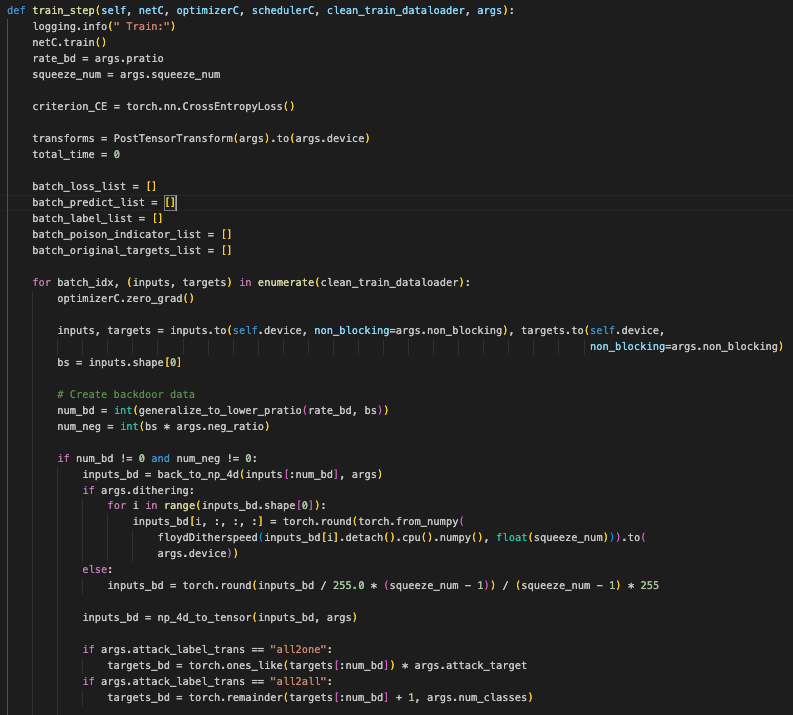
这段代码包含了两个主要的函数:train_step 和 eval_step。它们分别用于训练和评估模型
train_step 函数
功能: 执行一个训练步骤,处理数据、计算损失、更新模型权重,并计算各种指标。
-
初始化:
-
记录日志,设置模型为训练模式。
-
获取训练参数,包括背门比率(
rate_bd)和压缩数(squeeze_num)。 -
初始化交叉熵损失函数(
criterion_CE)和数据转换对象(transforms)。 -
初始化一些用于记录的列表。
-
-
数据处理:
-
对每个批次的数据进行处理:
-
清空优化器的梯度。
-
将输入数据和目标标签移动到指定设备(GPU/CPU)。
-
计算背门样本和负样本的数量。
-
根据是否存在背门样本和负样本,生成相应的数据:
-
背门样本: 对背门样本进行处理(如抖动处理)并生成标签。
-
负样本: 生成负样本数据并合并到训练数据中。
-
-
处理数据集中的每一批次,将背门样本和负样本合并到一起。
-
应用数据转换函数。
-
-
-
模型训练:
-
计算模型的预测结果,并记录计算时间。
-
计算损失,进行反向传播,更新优化器。
-
记录每个批次的损失、预测结果、标签等信息。
-
-
计算指标:
-
计算每个 epoch 的平均损失和准确率。
-
根据背门样本、负样本和干净样本的指标,计算背门攻击成功率(ASR)、干净样本准确率等。
-
-
返回:
-
返回训练过程中的各种指标:平均损失、混合准确率、干净样本准确率、背门攻击成功率、背门样本恢复准确率、交叉样本准确率。
-
eval_step 函数
功能: 执行模型评估,计算不同数据集(干净数据集、背门数据集、交叉数据集等)的损失和准确率。
-
清洁测试数据集评估:
-
使用
given_dataloader_test函数评估干净测试数据集,获取损失和准确率。
-
-
背门数据集评估:
-
使用
given_dataloader_test函数评估背门测试数据集,获取损失和准确率。
-
-
背门样本恢复(RA)数据集评估:
-
对背门样本恢复数据集进行转换和评估,获取损失和准确率。
-
-
交叉数据集评估:
-
使用
given_dataloader_test函数评估交叉测试数据集,获取损失和准确率。
-
-
返回:
-
返回不同数据集的损失和准确率:干净测试集损失和准确率、背门测试集损失和准确率、交叉测试集损失和准确率、恢复测试集损失和准确率。
-
这些函数一起构成了一个完整的训练和评估流程,涵盖了数据处理、模型训练、指标计算和评估等多个方面。
开始进行后门注入
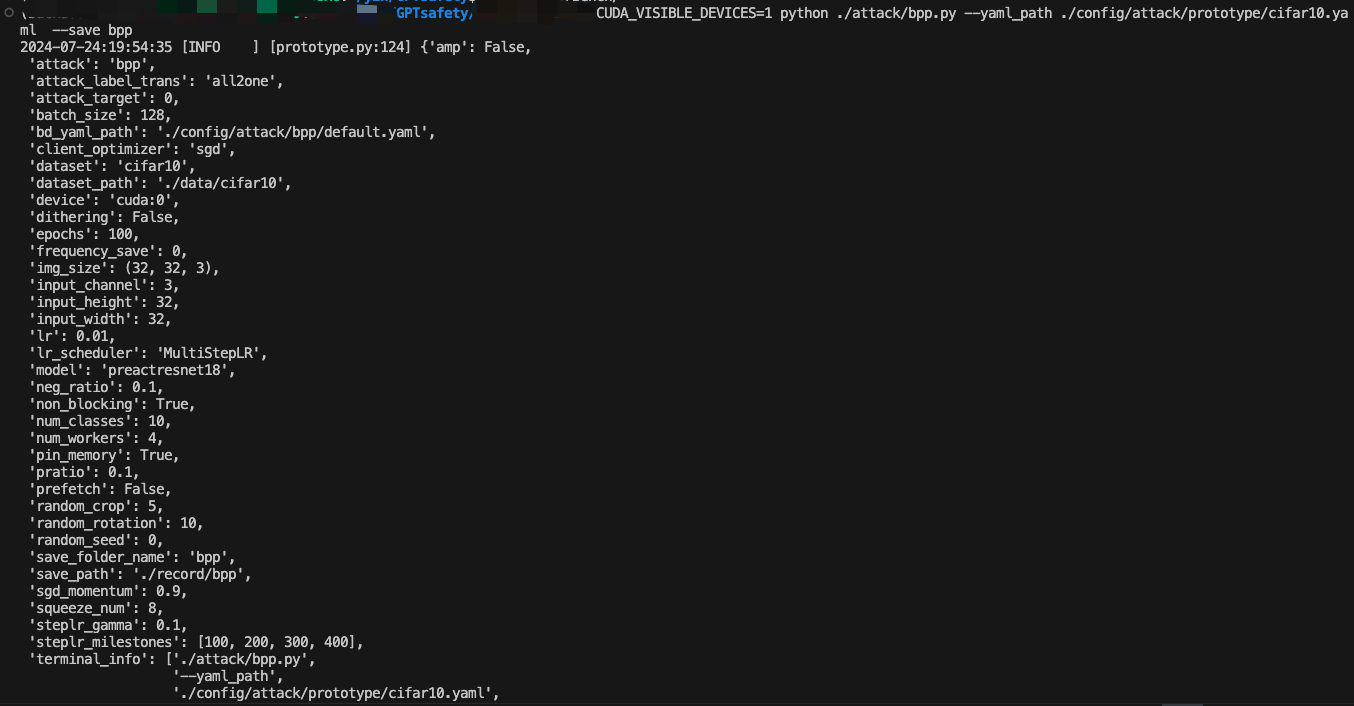
攻击配置如下所示
训练期间的部分截图如下
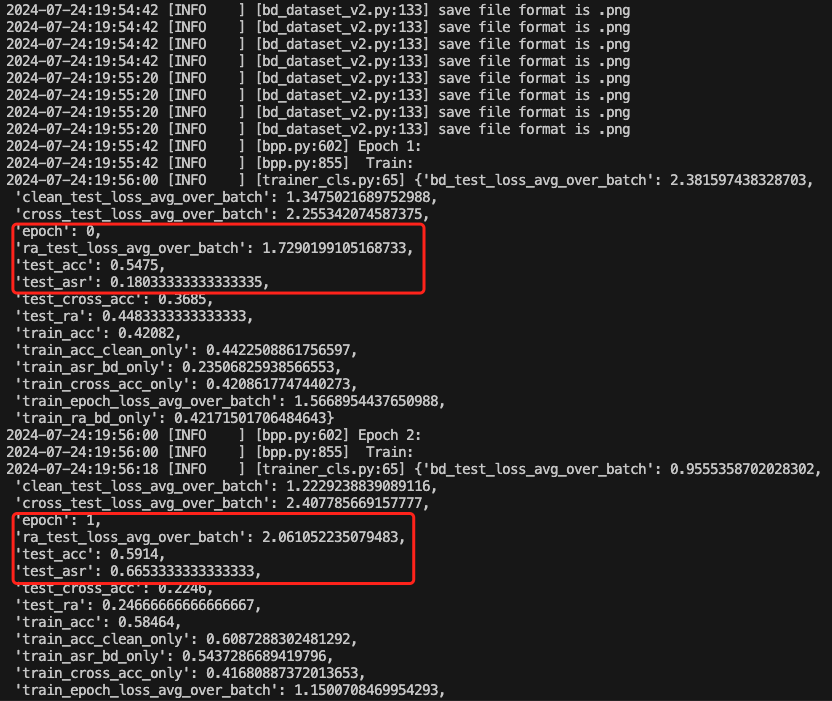
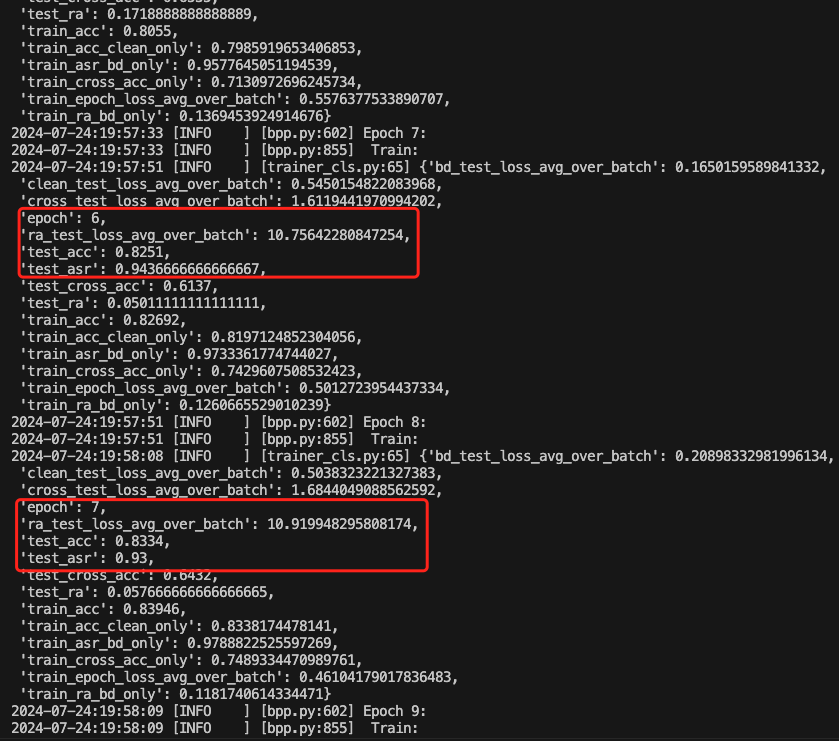
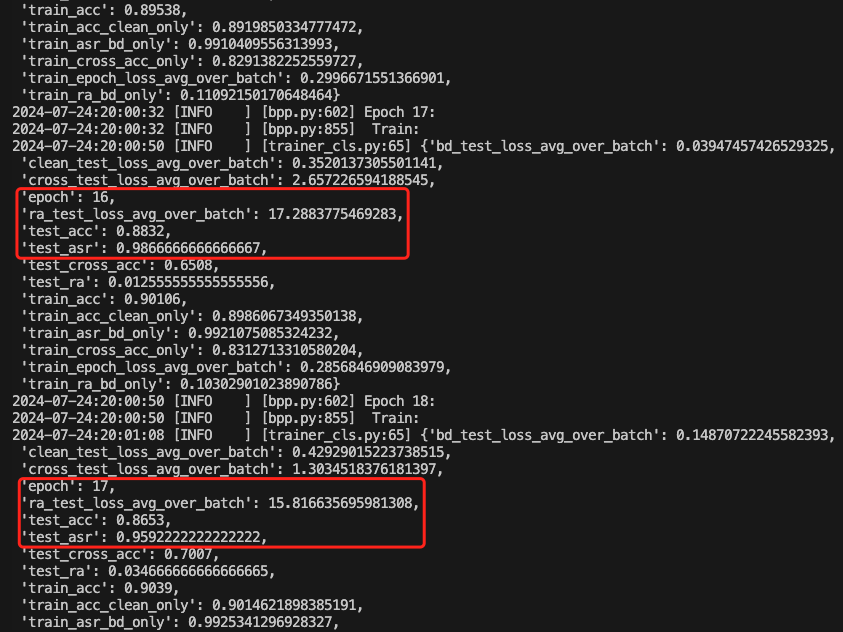
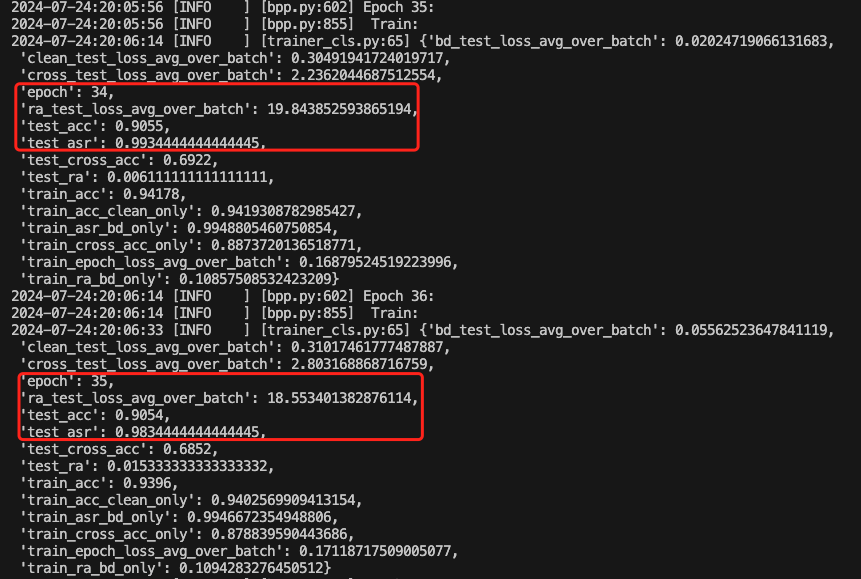
也可以查看acc的变化情况
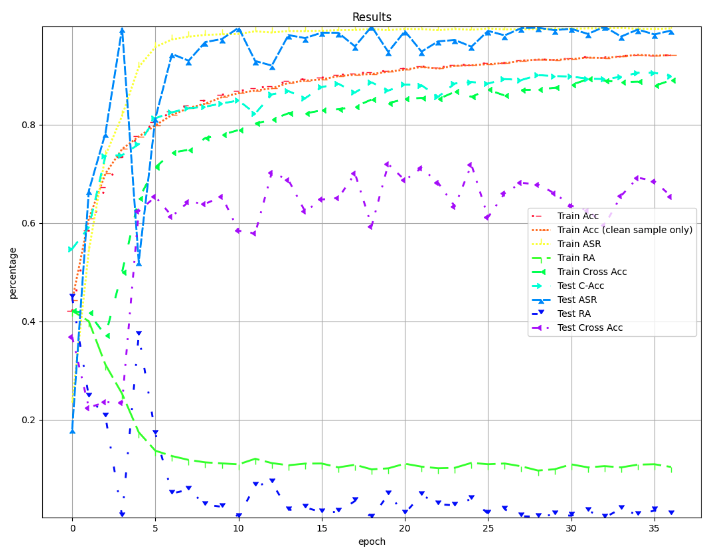
可以看到主要关注的指标都在稳步上升
以35epoch为例,此时的后门攻击成功率达到了0.98,而深度学习模型执行正常任务的准确率达到了0.91
FTrojan
理论
FTrojan攻击的核心思想是在频率域中注入触发器。这种方法利用了两个关键直觉:
-
在频率域中的小扰动对应于整个图像中分散的小像素级扰动,这使得图像在视觉上与原始图像难以区分。
-
卷积神经网络(CNN)能够学习并记住频率域中的特征,即使输入的是空间域像素。
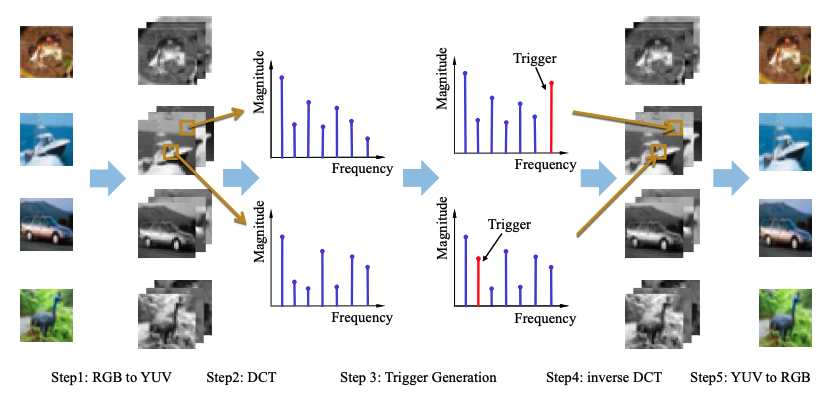
FTrojan攻击包括以下步骤:
-
将图像从RGB色彩空间转换到YUV色彩空间,因为人的视觉系统对YUV中的UV(色度)分量不那么敏感。
-
对图像的UV分量进行离散余弦变换(DCT),将其从空间域转换到频率域。
-
在频率域中生成触发器,选择固定大小的频率带作为触发器。
-
应用逆DCT将图像从频率域转换回空间域。
-
最后,将图像从YUV色彩空间转换回RGB色彩空间。
我们来分析关键细节
FTrojan攻击方法的核心在于利用频率域的特性来注入难以被检测到的后门触发器。
-
颜色空间转换(RGB到YUV):
-
使用线性变换将RGB图像转换为YUV空间。YUV空间将颜色图像分解为亮度(Y)和色度(U, V)分量。人的视觉系统对色度分量的变化不如亮度分量敏感,因此在色度分量中注入触发器对视觉的影响较小。
-
-
离散余弦变换(DCT):
-
对YUV空间中的U和V分量应用DCT,将图像从空间域转换到频率域。DCT将图像表示为不同频率的余弦函数的集合,能量集中在低频部分,高频部分则包含图像的边缘和细节信息。
DCT公式如下:
![image-20240727213411222]()
其中,(X(u, v))是DCT系数,(x(x, y))是图像在空间域的像素值,(M)和(N)是图像的宽度和高度,(u)和(v)是频率索引。
-
-
触发器生成:
-
在频率域中选择特定的频率带作为触发器。触发器的频率和幅度是两个关键参数:
-
触发器频率:选择中频和高频带的组合,以平衡人类视觉感知的敏感性和触发器的鲁棒性。
-
触发器幅度:选择适中的幅度以确保触发器对CNN是可学习的,同时对人类视觉系统是不可见的。
-
-
-
逆离散余弦变换(Inverse DCT):
-
使用逆DCT将修改后的频率域图像转换回空间域,得到注入了后门触发器的图像。
逆DCT公式如下:
![image-20240727213421592]()
-
-
颜色空间转换(YUV回到RGB):
-
最后,将修改后的YUV图像转换回RGB空间,因为大多数CNN模型是在RGB空间上训练的。
-
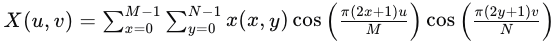
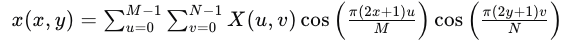
完整的攻击流程如下图所示
下图是本方法生成的中毒样本与触发器,可以看到是具有一定隐蔽性的

下图是通过 FTrojan 攻击来得到的中毒图像。混频将触发器混合在中频和高频成分中。我们可以观察到,当触发器存在于具有适中幅度的高频和中频成分中时,中毒图像在视觉上很难被检测到。

复现
攻击类
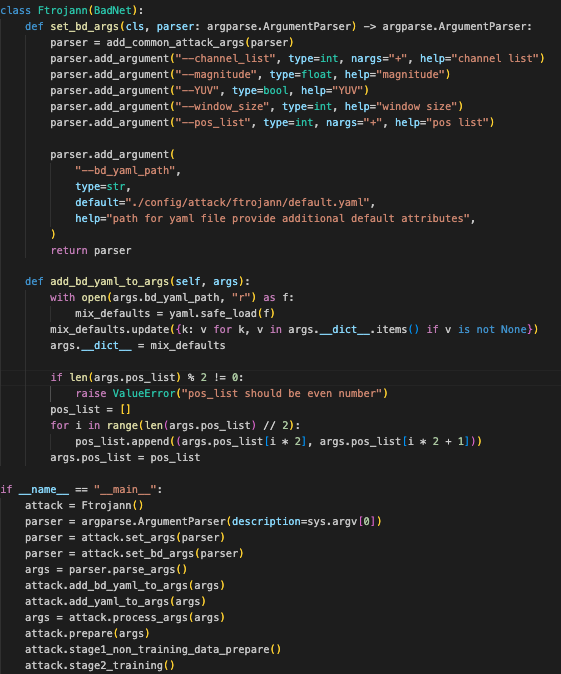
这段代码定义了一个 Ftrojann 类,继承自 BadNet。下面是代码的功能解释:
-
set_bd_args方法:-
这个方法用于设置命令行参数。它接受一个
argparse.ArgumentParser对象作为输入,并返回一个更新后的ArgumentParser对象。 -
add_common_attack_args(parser)是一个函数调用,可能会向parser中添加一些通用的攻击相关参数。 -
添加了多个特定参数:
-
--channel_list:接收一个整数列表,代表频道列表。 -
--magnitude:接收一个浮点数,表示强度。 -
--YUV:接收一个布尔值,表示是否使用 YUV 格式。 -
--window_size:接收一个整数,表示窗口大小。 -
--pos_list:接收一个整数列表,表示位置列表。 -
--bd_yaml_path:接收一个字符串,指定 YAML 文件的路径,该文件提供附加的默认属性。默认路径是./config/attack/ftrojann/default.yaml。
-
-
-
add_bd_yaml_to_args方法:-
这个方法用于将 YAML 文件中的默认属性添加到
args参数中,并进行一些额外的处理。 -
从
args.bd_yaml_path指定的路径读取 YAML 文件内容,解析为字典mix_defaults。 -
将
args对象中非None的参数更新到mix_defaults中。 -
将
args对象的__dict__属性(存储了所有参数)更新为合并后的字典。 -
检查
pos_list的长度是否为偶数,如果不是,抛出ValueError。 -
将
pos_list转换为一对一对的元组列表,例如,将[x1, y1, x2, y2]转换为[(x1, y1), (x2, y2)]。
-
着重查看对于数据集的处理代码
这个类的主要功能是处理带有后门攻击的图像数据集,支持图像和标签的预处理、状态恢复和复制。
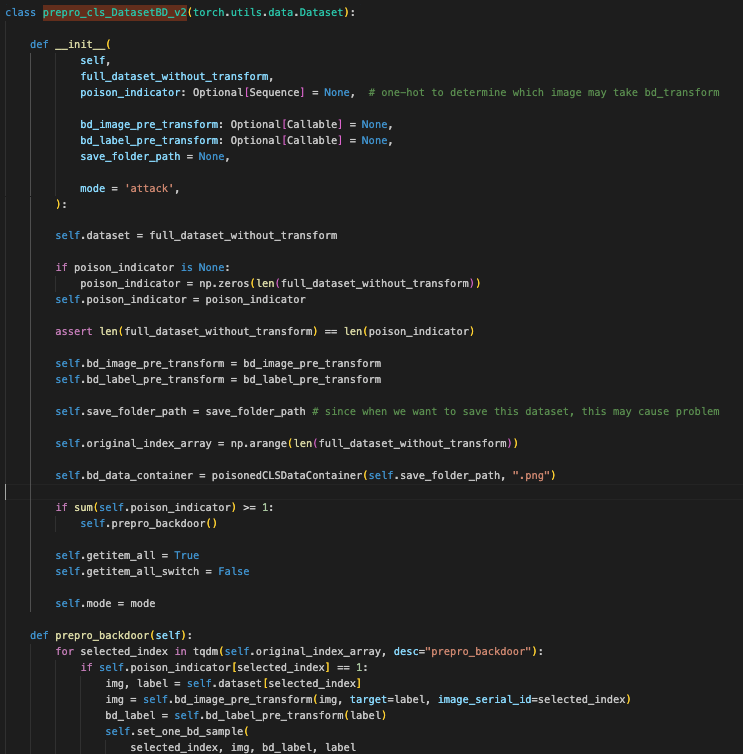
这段代码定义了一个名为 prepro_cls_DatasetBD_v2 的 PyTorch 数据集类。这个类扩展了 torch.utils.data.Dataset,用于处理带有后门攻击(backdoor attack)的数据集
-
__init__方法:-
参数:
-
full_dataset_without_transform: 原始数据集,没有应用任何变换。 -
poison_indicator: 一个可选的序列,表示哪些图像需要应用后门变换(使用 one-hot 编码)。默认为None,如果没有提供,则初始化为全零的数组。 -
bd_image_pre_transform: 应用在图像上的后门变换函数。 -
bd_label_pre_transform: 应用在标签上的后门变换函数。 -
save_folder_path: 保存后门图像的文件夹路径。 -
mode: 当前模式,默认为'attack'。
-
-
操作:
-
初始化数据集和相关属性。
-
检查
poison_indicator的长度是否与数据集长度匹配。 -
如果
poison_indicator中的值大于等于 1,则调用prepro_backdoor()方法进行后门数据预处理。 -
设置其他属性,如
getitem_all和getitem_all_switch,用于控制数据集的取值方式。
-
-
-
prepro_backdoor方法:-
对所有需要后门变换的样本进行处理。
-
遍历数据集的所有索引,如果
poison_indicator表示该样本需要变换,则应用图像和标签的变换,并调用set_one_bd_sample()方法保存变换后的样本。
-
-
set_one_bd_sample方法:-
将图像和标签变换后的样本保存到
bd_data_container中。 -
确保图像被转换为 PIL 图像格式(如果不是的话)。
-
更新
poison_indicator,标记该样本为后门样本。
-
-
__len__方法:-
返回数据集中样本的总数。
-
-
__getitem__方法:-
根据索引获取样本。
-
如果样本是干净的(
poison_indicator为 0),则从原始数据集中获取图像和标签。 -
如果样本是后门的(
poison_indicator为 1),则从bd_data_container中获取图像和标签。 -
根据
getitem_all和getitem_all_switch的设置,返回不同格式的数据。
-
-
subset方法:-
根据给定的索引列表更新
original_index_array,从而选择数据集的子集。
-
-
retrieve_state方法:-
返回当前对象的状态,包括
bd_data_container、getitem_all、getitem_all_switch、original_index_array、poison_indicator和save_folder_path。
-
-
copy方法:-
创建一个
prepro_cls_DatasetBD_v2的副本。 -
深度复制当前对象的状态,并设置到新副本中。
-
-
set_state方法:-
根据提供的状态文件恢复对象的状态。
-
包括恢复
bd_data_container和其他属性。
-
在我们的实现中得到的部分中毒样本如下所示


注入后门
攻击配置
后门注入期间的部分截图如下所示
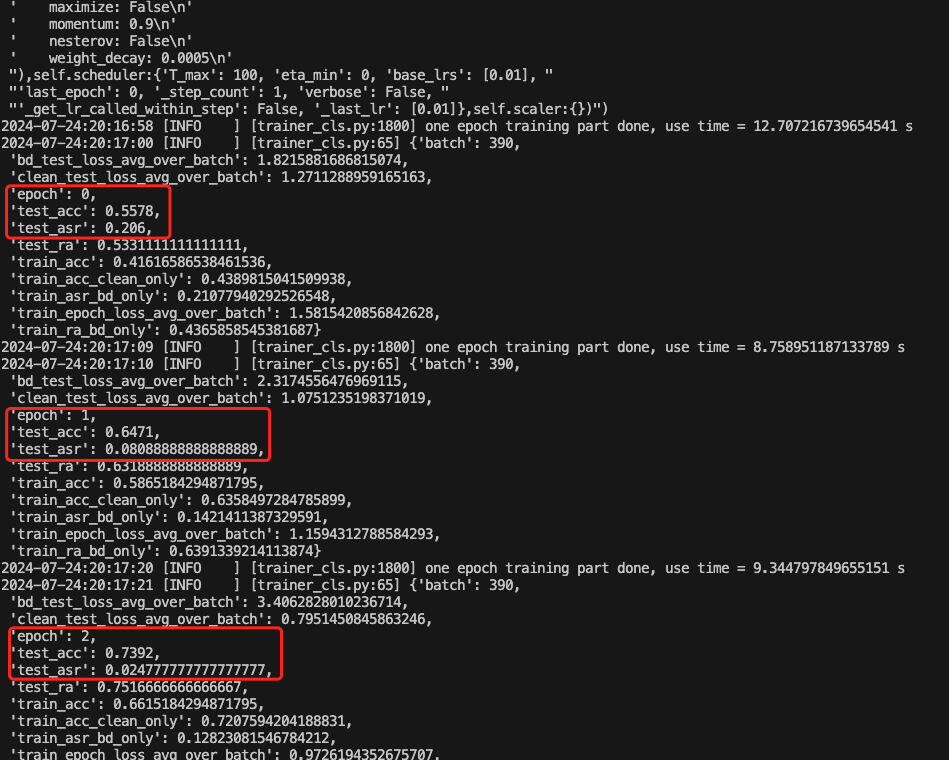
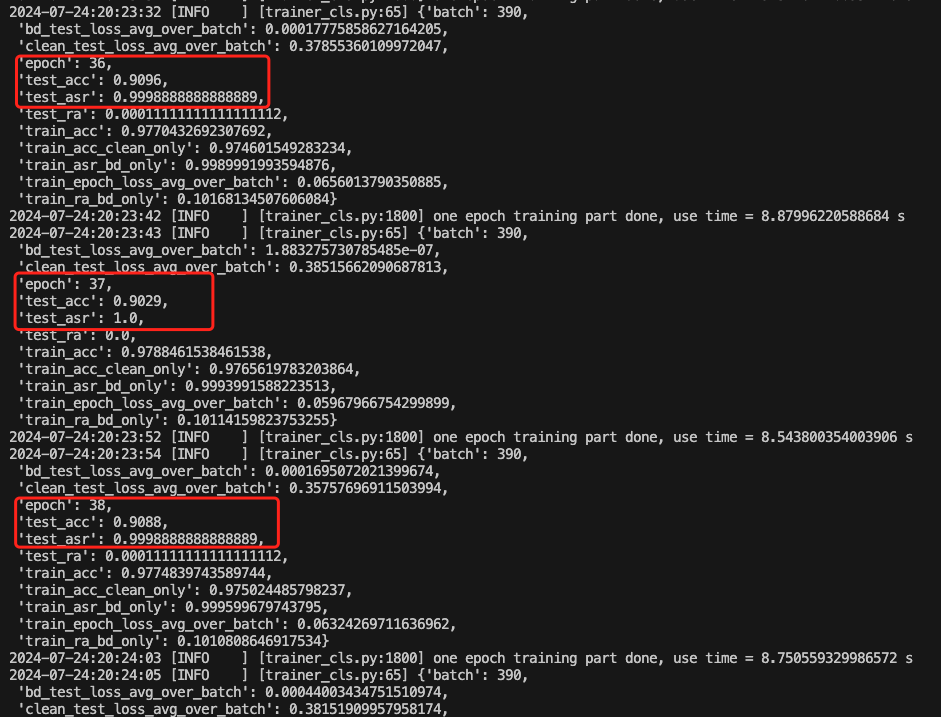
以第38个epoch为例,此时的后门攻击成功率达到了接近100%,而正常任务的准确率达到了0.91
CTRL
理论
之前我们提到的后门攻击都是通过监督学习的方式实现的,这一节我们来分析自监督学习后门攻击。
自监督学习(SSL)是一种无需标签即可学习复杂数据高质量表示的机器学习范式。SSL在对抗性鲁棒性方面相较于监督学习有优势,但是否对其他类型的攻击(如后门攻击)同样具有鲁棒性尚未明确。
CTRL攻击通过在训练数据中掺入少量(≤1%)的投毒样本,这些样本对数据增强操作具有抗性,使得在推理阶段,任何含有特定触发器的输入都会被错误地分类到攻击者预定的类别。
触发器 ( r ) 是一种在输入数据的频谱空间中的扰动,它对数据增强(如随机裁剪)不敏感。触发器的设计使其在视觉上几乎不可察觉,但在频域中具有特定的模式。
-
假设攻击者可以访问到一小部分目标类别的输入样本集 ( \tilde{D} )。
-
通过在这些样本上添加触发器 ( r ) 来生成投毒数据 ( D^* )。
-
嵌入:将触发器 ( r ) 嵌入到输入 ( x ) 中,形成触发输入 ( x^* = x \oplus r )。这里 ( \oplus ) 表示触发器嵌入操作。
-
激活:在推理时,攻击者可以调整触发器的幅度来激活后门,而不影响模型对清洁数据的分类性能。
SSL中的对比损失函数旨在最小化正样本对(相同输入的不同增强视图)之间的距离,同时最大化负样本对(不同输入)之间的距离。对比损失可以表示为:
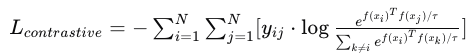
其中,( f ) 是编码器,( x_i ) 和 ( x_j ) 是正样本对,( y_{ij} ) 是指示器(如果 ( x_i ) 和 ( x_j ) 是正样本对,则为1,否则为0),( \tau ) 是温度参数。
CTRL攻击利用了SSL的表示不变性属性,即不同增强视图的同一输入应具有相似的表示。数学上,这可以表示为:
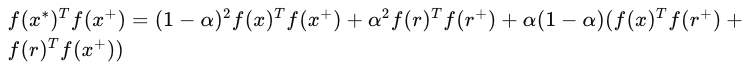
这里,( x^* ) 是触发输入,( x^+ ) 是增强后的正样本,( r ) 是触发器,( \alpha ) 是混合权重。
通过调整触发器的幅度,攻击者可以控制攻击的效果。
完整的攻击流程如下图所示
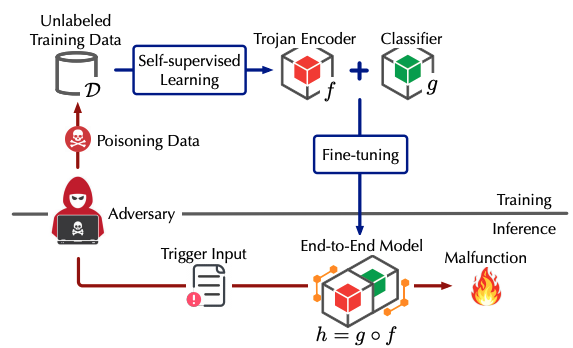
下图演示了触发器的生成流程

复现
分析关键代码
ctrl类的stage1_non_training_data_prepare` 方法负责准备背门攻击的数据,包括训练和测试数据集的生成。它先从干净数据中准备基础数据,然后生成背门样本,最后创建背门训练和测试数据集,并将结果保存以备后续使用。这一过程涵盖了从数据预处理到背门攻击数据的生成,并最终包装成适合训练和评估的格式。
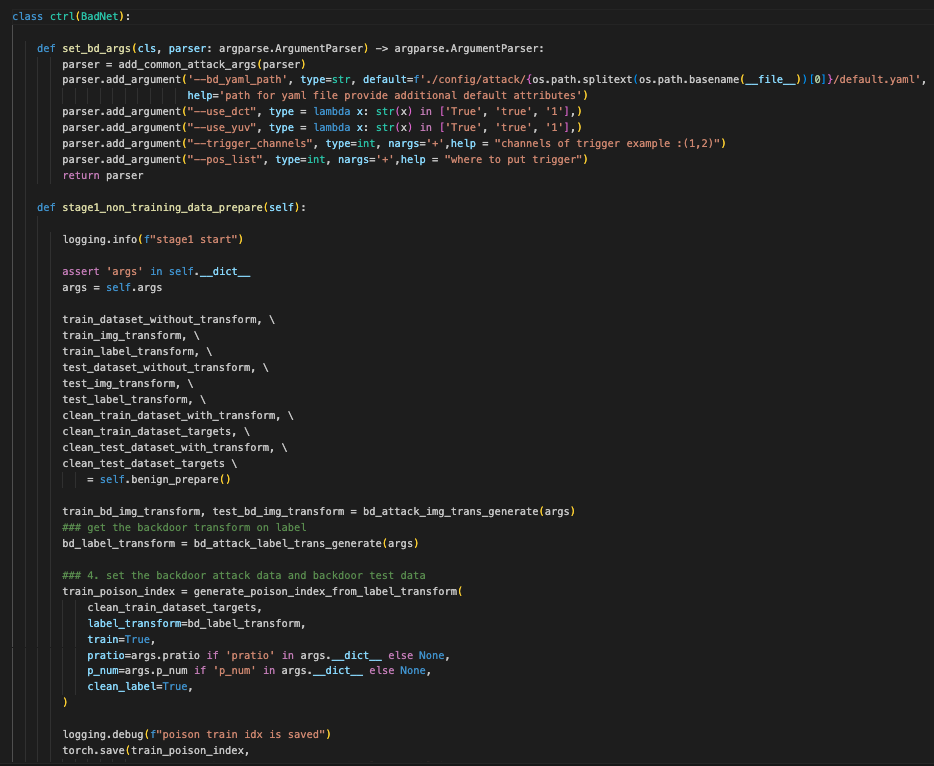
这段代码是一个名为 ctrl 的类的定义,它继承自 BadNet 类。主要功能是准备阶段1的数据,包括生成后门攻击数据和测试数据
1. set_bd_args 方法
功能: 设置用于背门攻击的命令行参数。
-
bd_yaml_path: 指定 YAML 配置文件的路径。 -
use_dct: 布尔值,指示是否使用 DCT(离散余弦变换)。 -
use_yuv: 布尔值,指示是否使用 YUV(视频色彩空间)。 -
trigger_channels: 触发器的通道。 -
pos_list: 触发器的位置。
2. stage1_non_training_data_prepare 方法
功能: 准备数据,包括清洁训练数据、背门训练数据和测试数据。
-
初始化:
-
记录日志并确保
args存在。 -
从
benign_prepare方法中获取不同的数据集和转换方法。
-
-
生成背门数据集:
-
调用
bd_attack_img_trans_generate和bd_attack_label_trans_generate方法生成背门数据集所需的图像和标签转换。 -
使用
generate_poison_index_from_label_transform方法生成训练数据中的背门样本索引。 -
保存背门样本索引到文件。
-
-
创建背门训练数据集:
-
使用
prepro_cls_DatasetBD_v2方法生成背门训练数据集,并应用转换。 -
创建数据集包装器
dataset_wrapper_with_transform。
-
-
生成背门测试数据集:
-
使用
generate_poison_index_from_label_transform方法生成测试数据中的背门样本索引。 -
使用
prepro_cls_DatasetBD_v2方法生成背门测试数据集,并应用转换。 -
使用
subset方法筛选测试数据集中的背门样本。
-
-
保存结果:
-
将准备好的数据集保存到
self.stage1_results中。
-
执行
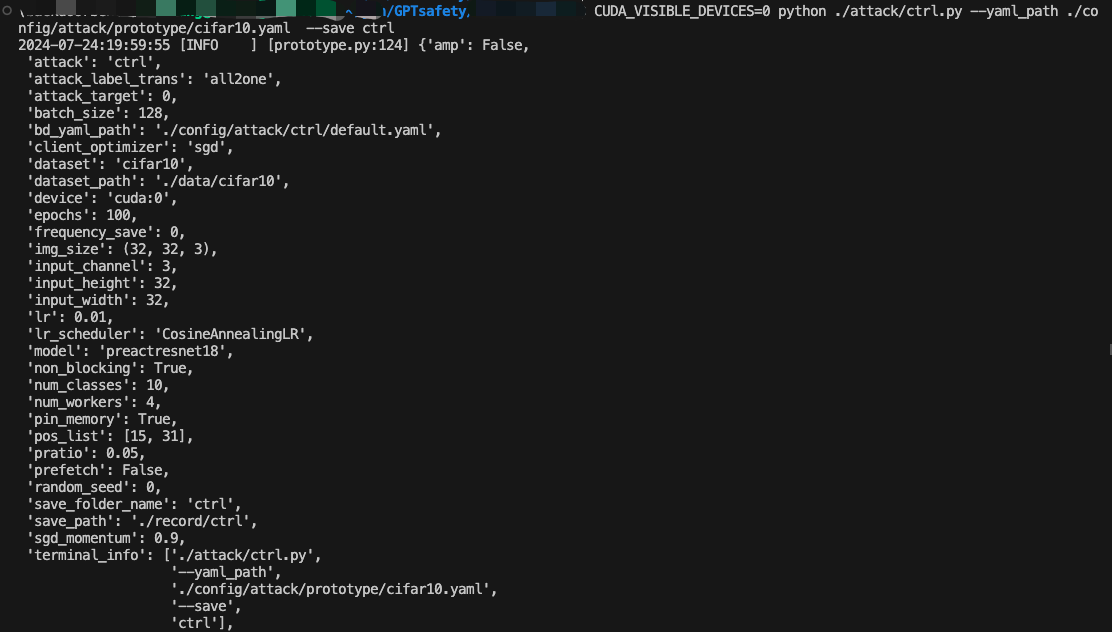
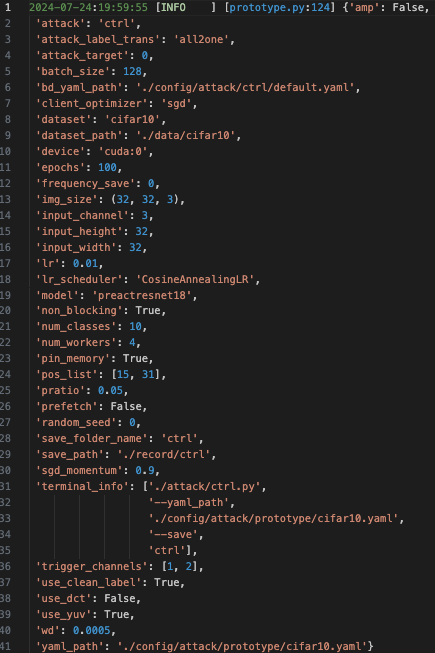
攻击配置如下
训练期间部分截图如下
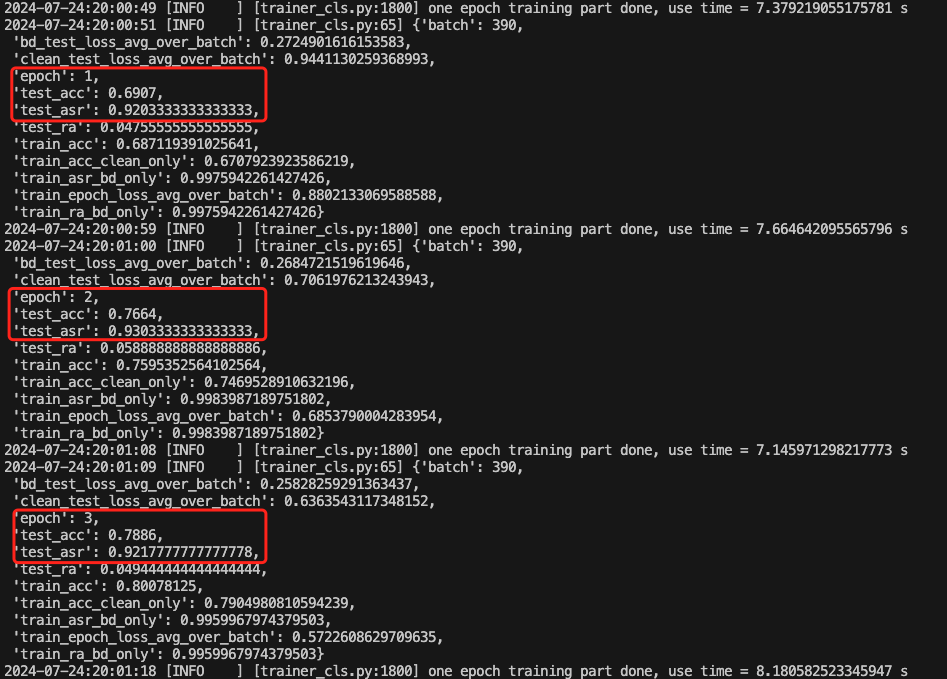
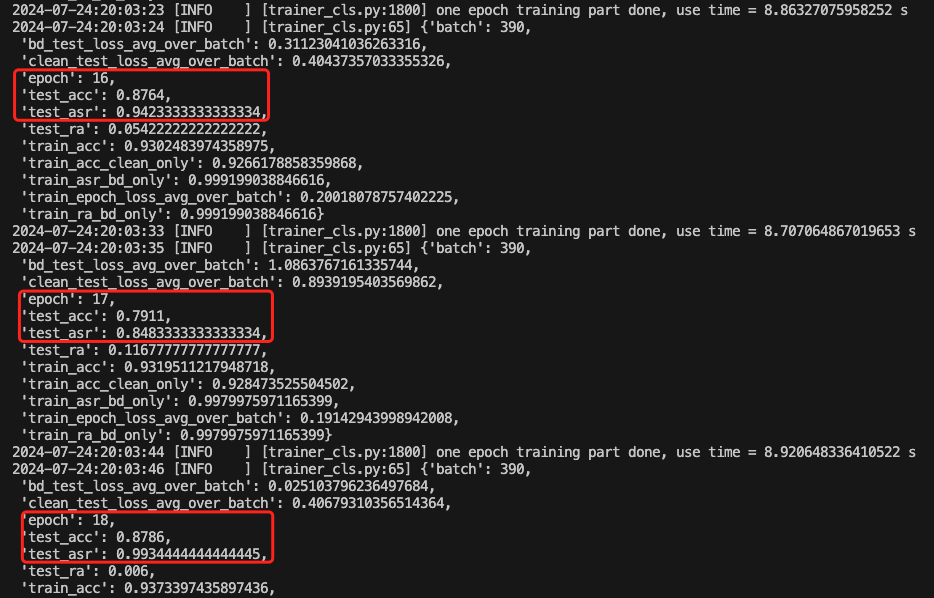
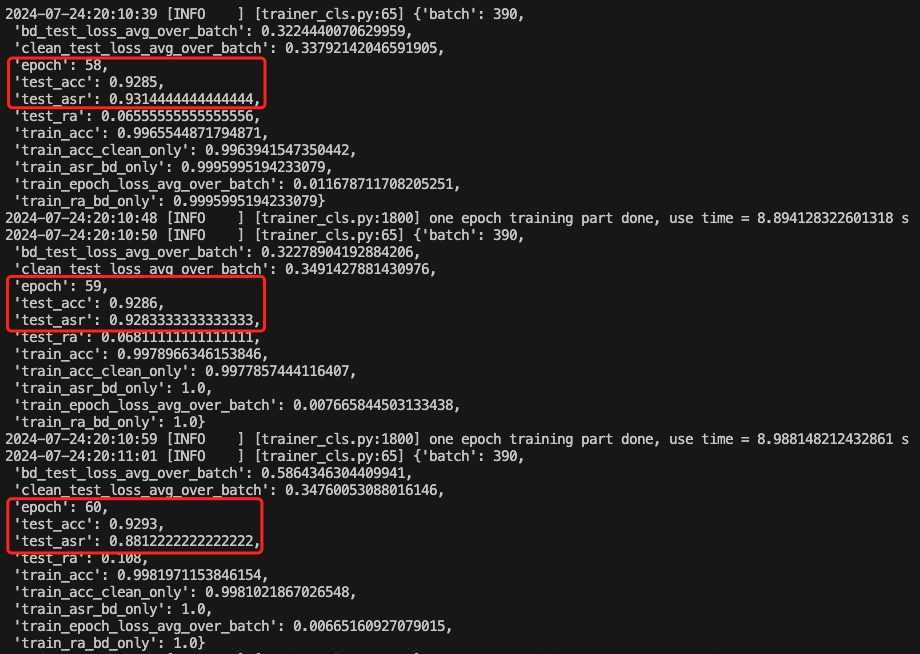
可以看到,CTRL在后门攻击成功率上稍低,比如在第59个epoch时,攻击成功率为0.93,正常任务准确率为0.93。
更多网安技能的在线实操练习,请点击这里>>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号