编译原理系列 实验一词法分析
刚好把四次实验都给做完了,在实验过程中发现学长学姐留下的实验参考不太够……就留下我的实验结果供大家参考吧~
实验一 词法分析实验
一、实验目的
根据PL/0语言的文法规范,编写PL/0语言的词法分析程序。要求:
把词法分析器设计成一个独立一遍的过程。
词法分析器的输出形式采用二元式序列,即:(单词种类, 单词的值)。
二、题目
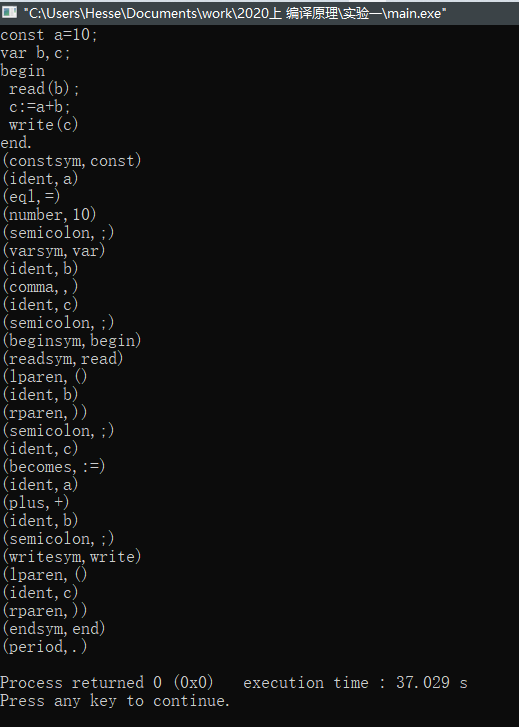
【样例输入】
const a=10;
var b,c;
begin
read(b);
c:=a+b;
write(c)
end.
【样例输出】
(constsym,const)
(ident,a)
(eql,=)
(number,10)
(semicolon,;)
(varsym,var)
(ident,b)
(comma,,)
(ident,c)
(semicolon,;)
(beginsym,begin)
(readsym,read)
(lparen,()
(ident,b)
(rparen,))
(semicolon,;)
(ident,c)
(becomes,:=)
(ident,a)
(plus,+)
(ident,b)
(semicolon,;)
(writesym,write)
(lparen,()
(ident,c)
(rparen,))
(endsym,end)
(period,.)
三、源程序
#include<fstream>
#include<cstring>
#include<string>
#include<fstream>
#include<sstream>
#include<iostream>
#include<map>
#include<bits/stdc++.h>
using namespace std;
map<string,string> words;
std::map<string,string>::iterator it;//words的指针
void words_init(){//对应关系进行初始化
words["+"]="plus";
words["-"]="minus";
words["*"]="times";
words["/"]="slash";
words["="]="eql";
words["<>"]="neq";
words["<"]="lss";
words["<="]="leq";
words[">"]="gtr";
words[">="]="geq";
words[":="]="becomes";
words["("]="lparen";
words[")"]="rparen";
words[","]="comma";
words[";"]="semicolon";
words["."]="period";
words["read"]="readsym";
words["then"]="thensym";
words["if"]="ifsym";
words["odd"]="oddsym";
words["procedure"]="proceduresym";
words["var"]="varsym";
words["while"]="whilesym";
words["write"]="writesym";
words["begin"]="beginsym";
words["do"]="dosym";
words["end"]="endsym";
words["call"]="callsym";
words["const"]="constsym";
}
int main(){
words_init();//初始化
// 读入输入串
char ins[100];
int i=0;
ins[i] = getchar();
while(ins[i] != '.'){
ins[++i] = getchar();
}
string inputs = ins;
// 处理输入串
int insize=inputs.length();
string word;
for(int i=0; i<insize; i++)
{
// 空白符跳过
while(inputs[i] == ' ' || inputs[i] == '\n')
i++;
// 标志符/基本字捕捉
if(isalpha(inputs[i])){
// 拿出一个标志符/基本字
word = inputs[i++];
while(isalpha(inputs[i]) || isdigit(inputs[i]))
word += inputs[i++];
// 在map中找到相应的词性,并输出
it = words.find(word);
if(it != words.end())
cout << "(" << words[word] << "," << word << ")" << endl;
else
cout << "(ident" << "," << word << ")" << endl;
i--;
}
// 常数
else if(isdigit(inputs[i])){
// 拿出常数
word=inputs[i++];
while(isdigit(inputs[i]))
word+=inputs[i++];
cout << "(number" << "," << word << ")" << endl;
i--;
}
// <、<=号
else if(inputs[i]=='<'){
word=inputs[i++];
if(inputs[i]=='>'){
word+=inputs[i];
cout << "(" << words[word] << "," << word << ")" << endl;
}else if(inputs[i]=='='){
word+=inputs[i];
cout << "(" <<words[word] << "," << word << ")" << endl;
}else if(inputs[i]!=' '||!isdigit(inputs[i])||!isalpha(inputs[i])){
cout << "(" << words[word] << "," << word << ")" << endl;
}else{
//cout << "error!" << endl;
}
i--;
}
// >、>=
else if(inputs[i]=='>'){
word=inputs[i++];
if(inputs[i]=='='){
word+=inputs[i];
cout<<"("<<words[word]<<","<<word<<")"<<endl;
}else if(inputs[i]!=' '||!isdigit(inputs[i])||!isalpha(inputs[i])){
cout<<"("<<words[word]<<","<<word<<")"<<endl;
}else{
//cout<<"error!"<<endl;
}
i--;
}
//:=
else if(inputs[i]==':'){
word=inputs[i++];
if(inputs[i]=='='){
word+=inputs[i];
cout<<"("<<words[word]<<","<<word<<")"<<endl;
}else{
//cout<<"error!"<<endl;
}
//i--;
}
//其他的基本字
else{
word=inputs[i];
it=words.find(word);
if(it!=words.end()){
cout<<"("<<words[word]<<","<<word<<")"<<endl;
}else{
//cout<<"error!"<<endl;
}
}
}
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号