
python:异常处理和网络编程requests
异常处理:
异常处理要用到try,except,else,finally等
eg1:
dic={
"id":1,
"name":"houning",
"sex":"nv"
}
choice=input('请输入您要查看的属性:')
try: #异常处理要用到try
print(dic[choice]) #如果代码没有异常,输出这句代码
except Exception as e: #这个Exception能捕捉到所有的异常;也可换成其他类型的异常词,但其他的异常信息(比如KeyError)捕捉都比较单一
print('出异常了',e) #python3这样用,e打印出来的是异常信息,出了异常的话,会输出e;也可以写其他,但一般都写e
except KeyError as e: #有把握的情况下可以写针对性的异常信息
print('输入的key错误')
else: #没有出异常的话,走else这里;也可以不写
print('ok')
finally: #有没有出异常都会走finally;操作数据库或文件等时,需要关闭,要用到finally,在finally后面关闭文件或数据库
print('over')
traceback模块:
利用traceback模块
开头添加import traceback
eg1:
dic={
"id":1,
"name":"houning",
"sex":"nv"
}
choice=input('请输入您要查看的属性:')
try: #异常处理要用到try
print(dic[choice]) #如果代码没有异常,输出这句代码
except Exception as e: #这个Exception能捕捉到所有的异常;也可换成其他类型的异常词,但其他的异常信息(比如KeyError)捕捉都比较单一
print('出异常了',e) #python3这样用,e打印出来的是异常信息,出了异常的话,会输出e;也可以写其他,但一般都写e
else: #没有出异常的话,走else这里;也可以不写
print('ok')
eg2:
用traceback 结尾改成:
try:
print(dic[choice])
except Exception as e:
print('出异常了',e)
traceback.print_exc() #程序运行会输出异常发生时候完整的栈信息,包括调用顺序、异常发生的语句额、错误类型等。
else:
print('ok')
错误信息如下:traceback.print_exc()方法打印出的信息包括3部分:错误类型、错误对应的值以及具体的trace信息,包括文件名、具体的行数、函数名以及对应的源代码。

Traceback模块常用的几个方法:
traceback.print_exception(type,value,traceback[,limit[,file]]),根据limit的设置打印栈信息,file为None的情况下定位到sys.stderr,否侧则写入文件;其中type、value、traceback这3个参数对应的值可以从sys.exc_info()中获取。traceback.print_exc([limit[,file]]),为print_exception()函数的缩写,不需要传入type、value、traceback这3个参数。traceback.format_exc([limit]),与print_exc()类似,区别在于返回字符串。traceback.extract_stack([file,[,limit]]),从当前栈帧中提取trace信息。
常见的一些异常信息:
AttributeError: 试图访问一个对象没有的属性,比如foo.x,但是foo没有属性x
IOError:输入/输出异常,一般是无法打开文件
ImportError: 无法导入模块或包,一般是路径问题或名称错误
IndentationError:代码没有正确对齐,属于语法错误
IndexError:下标索引超出序列边界,比如x只有三个元素,却试图访问x[3]
KeyError:试图访问字典里不存在的键
KeyboardInterrupt:Ctrl+C被按下
NameError:使用一个还未被赋予对象的变量
SyntaxError: 语法错误
TypeError: 传入对象类型与要求的不符
UnboundLocalError:试图访问一个还未被设置的局部变量,一般是由于在代码块外部还有另一个同名变量
ValueError: 传入一个调用者不期望的值,即使值的类型是正确的
eg2:
判断是不是小数,用异常仅需几行代码就可判断
def is_float(s):
try:
float(s) #float方法是强制转换为小数类型
except Exception as e:
return False
return True
主动抛出异常:
def is_correct_sql(sql):
sql_start=['select','update','insert','delete']
for start in sql_start:
if sql.startswith(start):
return True
else:
raise TypeError #用raise主动抛出TypeError这个异常;当sql错误的时候,异常信息是TypeError;
如果在被调用的函数里没有捕捉到这个主动异常的话,那在它上一级调用的函数里面只要出现异常,也可以捕捉到这个主动异常
python网络编程:
即python操作网络,即怎么用python打开一个网站,或者调用一个接口。使用urllib模块或requests模块。
urllib模块是一个标准模块,直接import urllib即可,在python3里面只有urllib模块,在python2里面有urllib模块和urllib2模块。
urllib模块:
from urllib.request import urlopen
from urllib.parse import urlencode,quote,unquote
import urllib,json
url='https://www.baidu.com'
res=urlopen(url).read().decode() #打开这个url,获取数据;.decode()是把字节转化成字符串
#urlopen(url)这个是发送get请求;requests发送get请求是requests.get(‘http://baidu.com’)
new_res=json.loads(res) #把返回的list的json串转成python的list数据类型
url2='http://python.nnzhp.cn/reg'
data={
"username":"hahaha",
"passwd":"123456",
"c_passwd":"123456"
}
param=urlencode(data) #这个可以把data字典里的key value拼接起来,即username=hahaha&passwd=123456&c_passwd=123456
print(urlopen(url2,param.encode()).read().decode()) #这个是发post请求;encode()可以把字符串转成字节类型的
url3='http://python.nnzhp.cn/reg:/,.'
print(quote(url3)) #quote是把特殊字符转化成url编码,比如%3A%3D等;
#unquote是把URL编码变成原来的特殊字符
requests模块(可以做爬虫、测接口、下载东西)
#requests模块就是基于urllib模块开发的,更好用import requests
url4='https://www.baidu.com'
requests.get(url).text #发get请求;text方式返回的是字符串类型
requests.get(url).json() #返回的是json类型,不同情况用不同的返回类型
url5="http://python.nnzhp.cn/reg?username=hn&passwd=123456"
requests.post(url5).text #发key value入参的post请求;text也可换成json(),意思同上
url6="http://python.nnzhp.cn/set_sites"
d={
"site":"nnzhp",
"url":"http://www.nnzhp.cn"
}
requests.post(url6,json=d).json() #发json串入参的post请求
url='http://www.nnzhp.cn'
#入参get请求
res=requests.get(url,params={'stu':'小黑'}) #发送get请求,有参数直接传字典就行
print(res.json()) #.json直接把返回结果转成字典,只适用于返回结果是json的url
#入参post请求
res=requests.post(url,data={'username':'hn','passwd':'guTF23vGhu9'}) #发送post请求
print(res.json())
#入参json请求
data1={
"name":"hnn",
"grade":"jjhh",
"phone":18826152671,
"sex":'nv',
"age":20
}
res=requests.post(url,json=data1) #入参是json类型
print(res.json())
#访问添加cookie的url
data={"userid":1,"money":999}
cookie={"token":"token12345"}
res=requests.post(url,data,cookies=cookie).json() #括号里写data可以直接拼接;使用cookies参数指定cookie
print(res)
#访问添加header的url,同cookie
head_url='http://api.nnzhp.cn/getuser2'
data={'userid':1}
header={'Content-Type':"application/json"}
res=requests.post(head_url,data,headers=header).json()
#访问上传文件的url
url='http://118.24.3.40/api/file/file_upload'
data={'file':open('music.mp3','rb')} #用rb,用wb的话会清空文件;上传文件需要这么用
res=requests.post(url,files=data)
print(res.json())
#返回结果是字符串的
url='http://www.nnzhp.cn'
res=requests.get(url)
print(res.text) #返回的都是字符串
#返回结果是二进制的,一般用于下载文件
url='http://qiniuuwmp3.changba.com/1084511584.mp3' #一首歌
res=requests.get(url,verify=False) #如果是https的url,要加上verify=False
print(res.content) #返回的是二进制,下载图片、音乐等文件需要用这个
with open('music.mp3','wb') as fw: #wb是写二进制的内容
fw.write(res.content) #把文件保存到本地
#返回结果是cookies、headers
print(res.cookies) #获取到返回的所有的cookie,是字典格式的。不是上面说的上传的cookies
print(res.headers) #获取到返回的所有的headers,是字典格式的
print(res.status_code) #获取到http的状态码,200就是通的
#添加权限验证
url = 'http://api.nnzhp.cn/setmoney'
data = {'userid':1,"money":91999}
res = requests.post(url,data,auth=('admin','123456')).json()
#使用auth参数指定权限验证的账号密码,auth传的是一个元组
#下载图片:
import requests
url='http://s2.cdn.xiachufang.com/47cbe32287bd11e6a9a10242ac110002_600w_400h.jpg'
res=requests.get(url).content #打开图片的链接用content
fw=open('a.jpg','wb') #wb指打开二进制的文件,b是bytes的意思
fw.write(res)
fw.close()
#下载东西的步骤差不多都这样
#关于Content-Type: multipart/form-data; boundary=----xxxxxxx(上传图片)接口调用方法
有两种调用方式,但是目前还没搞清楚有什么区别
方式一:请求头加上Content-Type
这样接口的请求头包含一个特殊的请求头信息:Content-Type,类型为:multipart/form-data,有一个内容分割符 (boundary) 用于分割请求体中的多个post的内容。
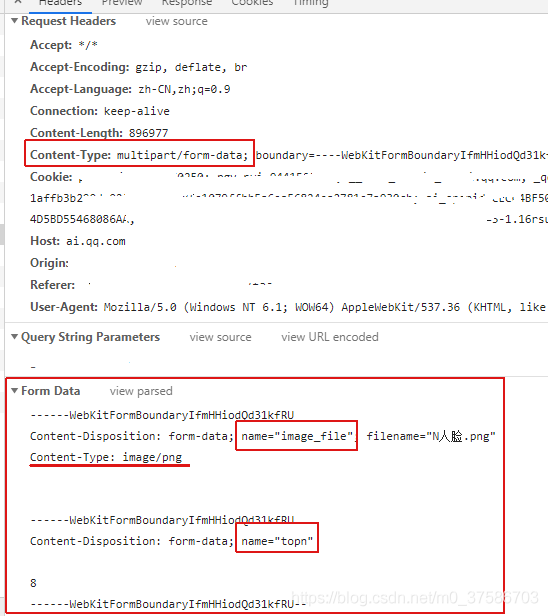
boundary后面是一个随机码,调接口时如果header里要加上content_type,那么就需要在Python中上传和生成这个随机码信息,需要用到 requests_toolbelt 这个库。
import requests,jsonpath from requests_toolbelt import MultipartEncoder def get_imageUrl(): url="http://192.168.1.44:2080/prod-api/device/site/upload" m=MultipartEncoder( #Content-Type: multipart/form-data; boundary=----xxx这种格式的接口,需要用到requests_toolbelt库 fields={ #fields是固定写法 "topn":(None,'2'), "image_file": ("1.jpg", open('1.jpg', 'rb'), "image/jpeg") #这里的key对应的时form-data中name的值 } ) print(m.content_type) #结果是multipart/form-data; boundary=74b2cde8dd9248fc86eb5960067ddfb1 header={ 'Content-Type': m.content_type, "Authorization": "Bearer eyJhbGciOiJIUzUxMiJ9.eyJsb2dpbl91c2VyX2tleSI6Ijg1ZWE0MzIxLTk5MGEtNGMwMS1hZTc4LTAyMGJmMjQyZjhmZCJ9.6" } res=requests.post(url,data=m , headers = header).json()
方式二:不要header里的content_type
这种方式就不需要requests_toolbelt库
比如下面这个请求体里,有上传文件,也有其他入参
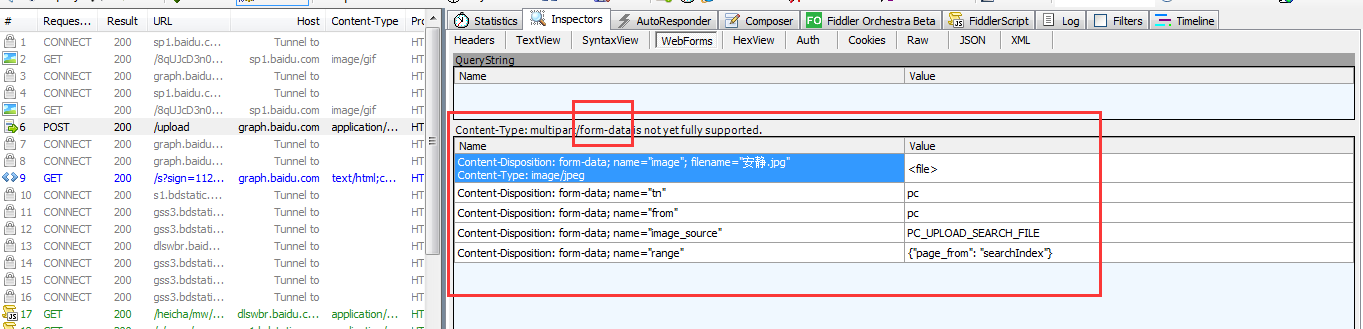
代码如下:
url="http://192.168.1.44:2080/prod-api/device/site/upload"
header={
"Authorization": "Bearer eyJhbGciOiJIUzUxMiJ9.eyJsb2dpbl91c2VyX2tleSI6IjhiYTQzMTdlLWU4MmQtNGJmMi04YTkxLTJlZWQ3MDZkMzYzMyJ9.S1R"
}
files = {
"tn":"pc",
"image":("123.jpg",open('123.jpg','rb'),"image/jpeg"),
"from":"pc",
"image_source":"PC_UPLOAD_SEARCH_FILE",
"range":'{"page_from": "searchIndex"}'
}
res=requests.post(url,headers=header,files=files).json()
print(res)
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号