python:模块(shutil pandas numpy)
一、shutil模块
shutil.copyfile(file1,file2)
file1为需要复制的源文件的文件路径,file2为目标文件的文件路径+文件名
如下:将/data15/data/a.jpg复制到/data18/data下并重命名为b.jpg
src = os.path.join("/data15/data/a.jpg")
dst = os.path.join("/data18/data/b.jpg")
shutil.copyfile(src, dst)
shutil.copy(file,folder)
将某个文件复制到另一个文件夹下
如下:将src文件夹下面的所有文件,都复制到dst文件下,这个没法改文件名字
src = os.path.join("/data15/data") dst = os.path.join("/data18/data") list=glob.glob(os.path.join(src,'*')) for x in list: shutil.copy(x, dst)
二、pandas模块
pandas处理表格型数据,时常需要读入excel表格数据,很多人一般都是直接这么用:
pd.read_excel(r“D:\data\test.xlsx”) #r是对\进行转义
它的参数如下
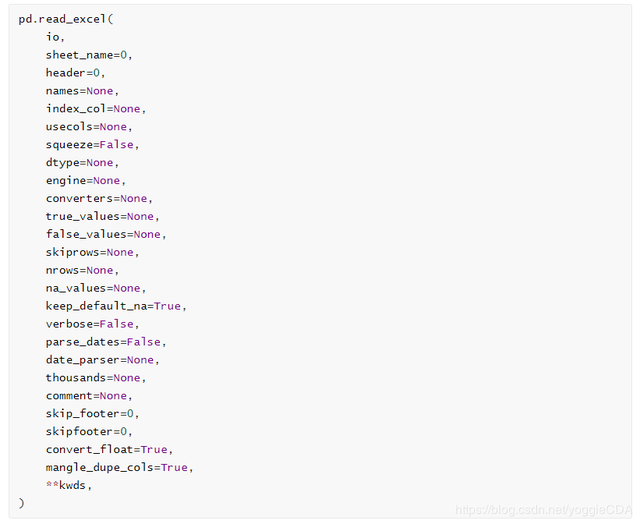
io参数
io参数主要就是传excel文件,可接收:str,Excel文件,xlrd.Book,路径对象或类似文件的对象。其中最常用的是str,一般是文件路径+文件名
sheet_name
第几个sheet页,可以指定第几个或sheet页名字,比如sheet_name=1或sheet_name='data2';不填的话,默认是第一个sheet页
header
指定哪一行作为列名,不填默认把第0行作为列名;header=2指定第3行作为列名;header=[2,3],可以指定两行作为列名;如果不需要列名,可设置header = None
names
指定列名的名字,不填 默认是none;指定第3行作为列名,名字重命名为列表里的:header=2,names=['学校','语文','数学','英语']
index_col
指定用哪一列作为行索引,可以指定多列。不填 默认是none,自动给个索引;index_col=0,index_col=[0,1],指定第一列、或者第一二列作为行索引
usercols
指定读取哪些列。不填 默认是None 读取所有列;usecols=10,读取第1到第10列;usecols=[2],只读取第2列;usecols=[2,5],只读取第2列和第5列;usecols=[‘语文’],读取字段名为“语文”的列
https://baijiahao.baidu.com/s?id=1667358973408895202&wfr=spider&for=pc 未完待续

 浙公网安备 33010602011771号
浙公网安备 33010602011771号