第1章 关于对象
第1章 关于对象
在C语言中, "数据"和"处理数据的操作(函数)"是分开来声明的, 也就是说语言本身并没有支持"数据和函数"之间的关联性. 把这种程序方法称为程序性, 有一组"分布在各个以功能为向导的函数中"的算法所驱动, 它们处理的是共同的外部数据. **C++支持封装的性质并没有带来任何空间或执行期的不良后果. C++在布局以及存取时间上主要的额外负担是由virtual引起的, 包括: **
数据成员直接放在每一个类对象之中. 而成员函数虽在class的声明之内, 却不出现在对象之中. 每一个non-inline member function只会诞生一个函数实例. 至于每一个"拥有零个或一个定义"的inline function则会在其每一个使用者(模块)身上产生一个函数实例
- virtual function机制, 用以支持一个有效的"执行期绑定"
- virtual base class用以实现"多次出现在继承体系中的base class, 有一个单一而被共享的实例"
此外还有一些多重继承下的额外负担, 发生在"一个derived class和其第二或后继之base class的转换"之间
1.1 C++对象模型
C++中, 有两种数据成员: static和nonstatic, 以及三种类成员函数: static, nonstatic和virtual.
class Point {
public:
Point(float xval);
virtual ~Point();
float x() const;
static int PointCount();
protected:
virtual ostream& print(ostream &os) const;
float _x;
static int _point_count;
};
简单对象模型
成员本身并不放在对象之中. 只有"指向成员的指针"才放在object内. 这么做可以避免"members有不同的类型, 因而需要不同的存储空间"所招致的问题. 它可能是为了尽量减低C++编译器的设计复杂度而开发出来的, 赔上的则是空间和执行期的效率.
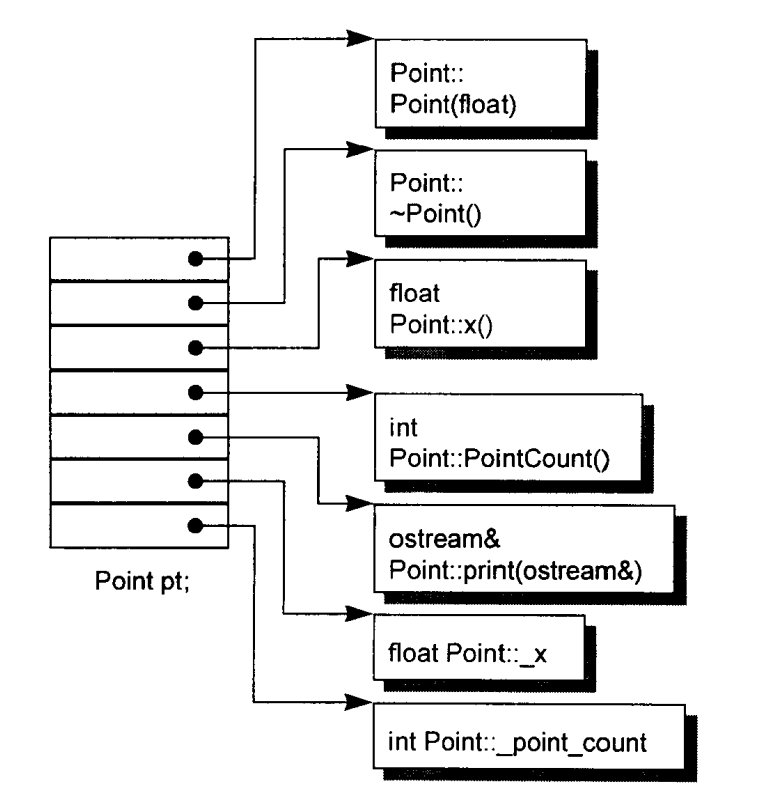
虽然这个模型并没有应用到实际产品上, 不过关于索引或slot个数的观念倒是被应用到C++的"指向成员的指针"(point-to-member)观念之中
表格驱动对象模型
为对所有类的对象都有一致的表达方式, 把所有与成员相关的信息抽取出来, 放在一个data member table和一个member functio table指针, 类对象本身则内含指向这两个表格的指针.
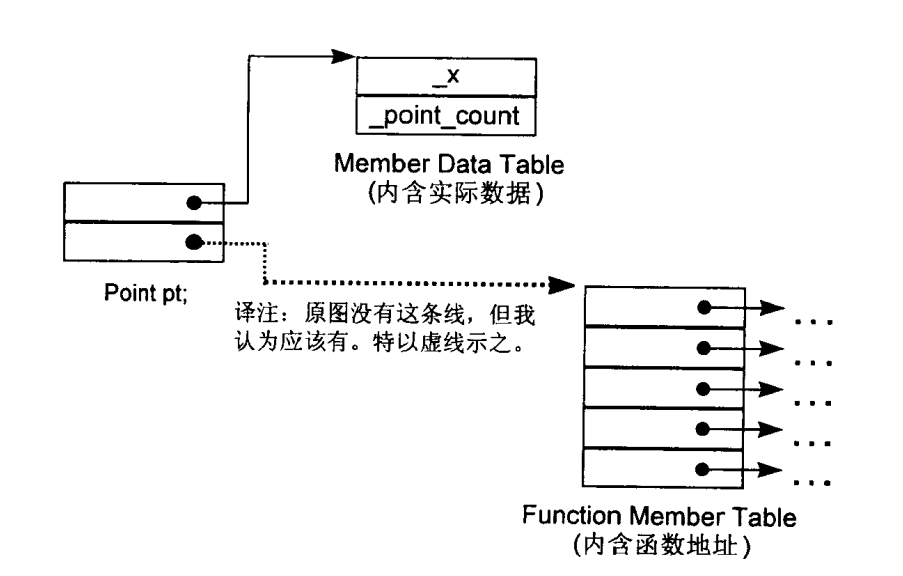
虽然这个模型没有实际应用于真正的C++编译器身上, 但member function table这个观念却成为支持virtual functions的一个有效方案
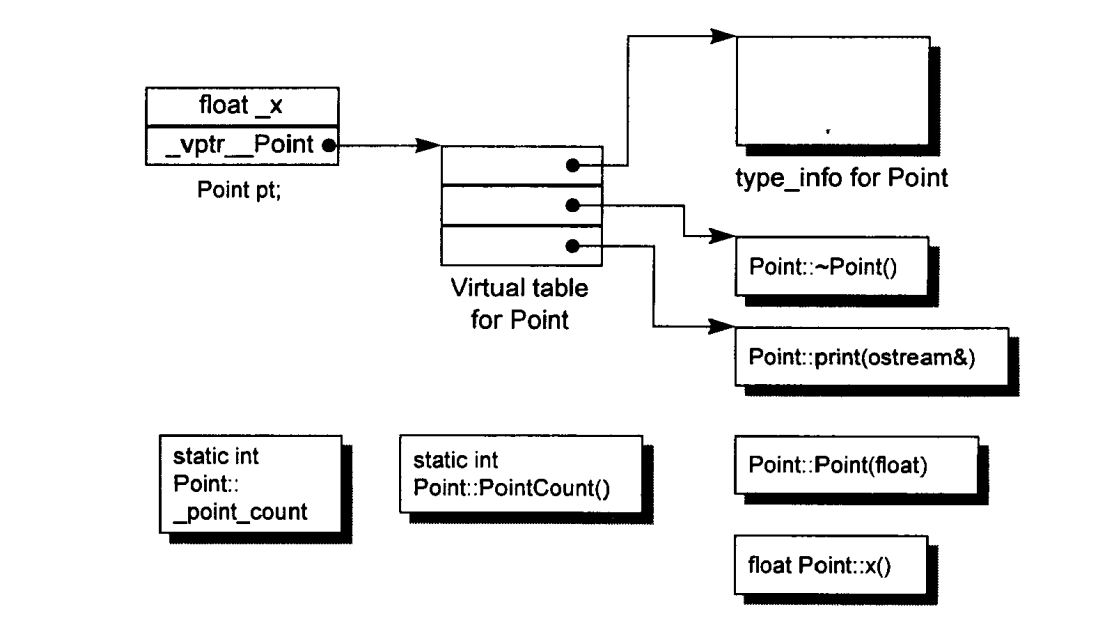
C++ 对象模型
nonstatic data members被配置于每一个class object之内, static data members则被存放在个别的class object之外. static和nonstatic function members也被存放在个别的class object之外, virtual functions则以两个步骤支持之:
- 每一个class产生出一堆指向virtual functions的指针, 放在表格指针, 这个表格被称为virtual table(vtbl)
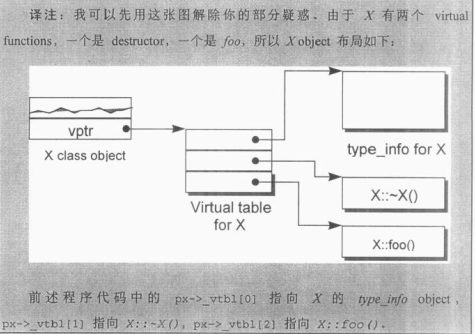
- 每一个class object被安插一个指针, 指向相关的虚函数表. 通常这个指针被称为vptr. vptr的设定和重置都有每一个类的constructor, destructor和copy assignment运算符自动完成. 每一个类所关联的type_info object(用以支持runtime type identification, RTTI)也经由虚函数表指出, 通常放在表格的第一个slot
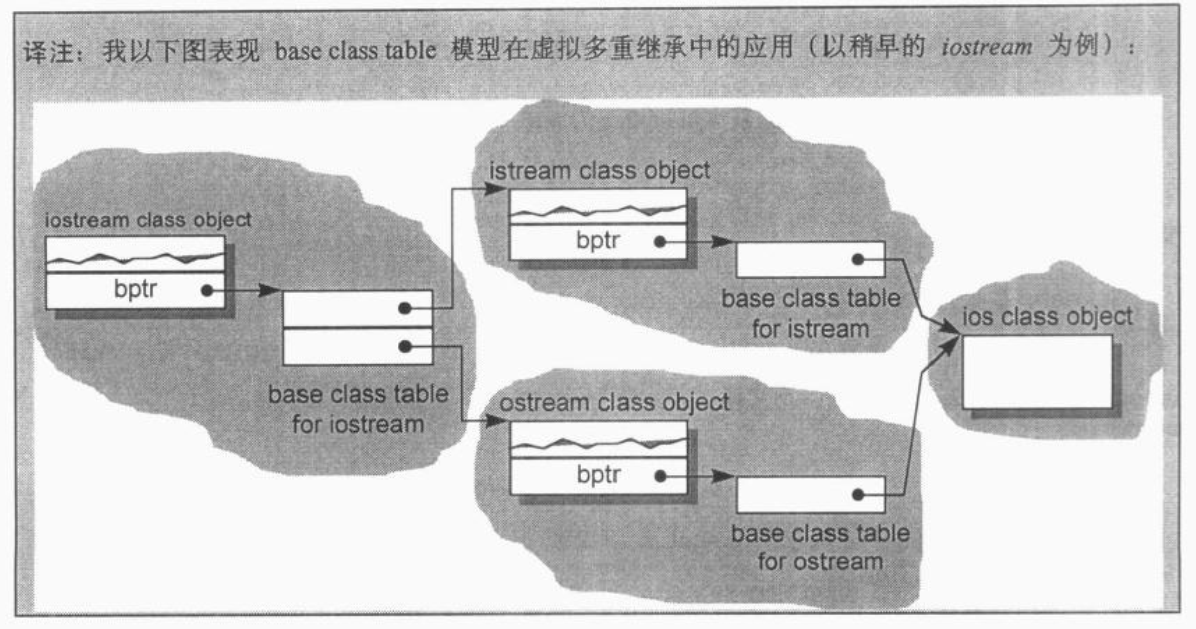
加上继承: C++支持单一继承, 多继承和虚继承(在虚拟继承的情况下, 基类不管在继承串链中被派生多少次, 永远只会存在一个实例, 例如iostream之中就只有virtual ios基类的一个实例)
一个derived class如何在本质上模塑其base class:
- "简单对象模型": 每一个基类可以被派生类实内的一个slot指出, 该 slot含有基类对象的地址.
主要缺点是, 因为间接性而导致的空间和存取时间上的额外负担,
优点则是类对象的大小不会因其基类的改变而改变 - base class table: 这里所说的base class table被产生出来时, 表格中的每一个slot内含一个相关的基类地址, 这很像虚函数表内涵每一个虚函数的地址一样. 每一个类对象内含有一个bptr, 他会被初始化, 指向其base class table.
主要缺点是由于间接性而导致空间和存取时间上的额外负担,
优点则是在每一个类对象中对于继承都有一致的表现方式: 每一个类对象都应该在某个固定位置上安防一个base table(基类表?)指针, 与基类的大小或个数无关. 第二个优点是, 无须改变类对象本身, 就可以放大, 缩小, 或更改基类表
C++最初采用的继承模型并不运用任何间接性, 即base class subobject的data members被直接放置于derived class object中. 这提供了对base class members最紧凑而且最有效率的存取. 缺点是: base class members的任何改变, 包括增加, 移除或改变类型等等, 都使得所有用到"此base class或其derived class之objects"者必须重新编译
自C++ 2.0起才导入的virtual base class, 需要一些间接性的base class表现方法. virtual base class的原始模型是在class object中为每一个有关联的virtual base class加上一个指针. 其他演化出来的模型则要不是导入一个virtual base class table, 就是扩充原已存在的virtual table, 以便维护每一个virtual base class的位置. 3.4节有这方面的详细讨论
对象模型如何影响程序
不同的对象模型, 会导致"现有的程序代码必须修改"以及"必须加入新的程序代码"连个结果, 例如下面这个函数, 其中class X定义了一个copy constructor, 一个virtual destructor和一个virtual function
X foobar() {
X xx;
X *px = new X;
// foo()是一个virtual function
xx.foo();
px->foo();
delete px;
return xx;
};
这个函数有可能在内部被转化为
// 可能的内部转化结果
// 虚拟C++代码
void foobar(X &_result) {
// 构造_result
// _result用来取代local xx ...
_result.X::X();
// 扩展X *px = new X;
px = _new(sizeof(X));
if (px != 0)
px->X::X();
// 扩展xx.foo()但不使用virtual机制
// 以_result取代xx
foo(&_result);
// 使用virtual机制扩展px->foo()
(*px->vtbl[2])(px);
// 扩展delete px;
if (px != 0) {
(*px->vtbl[1])(px); // destructor
_delete(px);
}
// 无须使用named return statement
// 无须摧毁local object xx
return;
};
1.2 关键词所带来的差异
关键词困惑
两个node重定义
class node {};
struct node {};
报错
template<struct Type>
struct number {};
不报错
template<class Type>
struct numble {};
策略性正确的struct
待补充
1.3 对象的差异
C++程序设计模型直接支持三种程序设计规范(programming paradigms): 1. 程序模型; 2. 抽象数据类型模型; 3. 面向对象模型
虽然可以直接或简介处理继承体系中的一个基类对象, 但只有通过指针或引用的间接处理, 才支持OO程序设计所需的多态性质
thing1的定义和运用逸出了OO的习惯, 它反应的是ADT paradigm的行为
Library_materials thing1;
// class Book : public Library_materials { ... };
Book book;
// thing1不是一个Book!
// book被裁减
// 不过thing1仍保有一个Library_materials
thing1 = book;
// 调用的是Library_maternal::check_in()
thing1.check_in();
thing2的定义和语言, 是OO paradigm中的一个良好例证
// OK: 现在thing2参考到book
Library_maternal &thing2 = book;
// OK 现在引发的是Book::check_in()
thing2.check_in();
在OO paradigm之中, 程序员需要处理一个位置实例, 它的类型虽然有所界定, 却有无穷可能. 这组类型受限于其继承体系, 然而该体系理论上没有深度和广度的限制. 在C++中, 只有通过指针和引用的操作来完成. 相反, 在ADT paradigm中, 程序员处理的是一个拥有固定而单一类型的实例, 它在编译期间就已经完全定义好了
// 描述objects: 不确定类型
Librar_maternal *px = retrieve_some_maternal();
Librar_maternal &rx = *px;
// 描述已知物: 不可能有令人惊讶的结果产生
Librar_maternal dx = *px
没有办法确定地说出px或tx到底指向何种类型对象, 只能确定要么是一个Librar_maternal类型要么就是Librar_maternal的子类型. dx可以确定是Librar_maternal类的一个对象
C++中指针或引用的处理不是多态的必要结果
// 没有多态, 因为操作对象不是class object
int *pi;
// 没有语言所支持的多态, 因为操作对象不是class object
void *pvi;
// ok: class x视为一个基类, 可以有多态效果
x *px;
在C++, 多态只存在与一个个public class体系中. 举个例子, px可能指向某个类型的object, 或指向根据public继承关系派生而来的一个子类型(不考虑不良转换操作). nonpublic的派生行为以及类型为void*的指针可以说是多态的, 但它们并没有被语言明确地支持, 也就是说它们必须由程序员通过显示的转换操作来管理
C++以下列方法支持多态:
- 经由一组隐式的转化操作. 例如把一个derived class指针转化为一个指向其public base type的指针:
shape *ps = new circle(); - 经由virtual function机制:
ps->rotate(); - 经由dynamic_cast和typeid运算符:
if ( circle *pc = dynamic_cast< circle* > ( ps ))...
一般而言类对象所需内存要有
- 其非静态数据成员的总和大小
- 加上由于alignment的需求而填补上去的空间(可能存在于成员之间, 也可能存在于集合体边界), 好像就是字节对齐的意思
- 加上为了支持virtual而由内部产生的任何额外的负担
指针的类型
指针的大小都是一样的, 都是存储指向对象的地址, 区别仅仅是"指针类型", 它会教导编译器如何解释某个特定地址中的内存内容及大小, 即影响解释方式
class ZooAnimal {
public:
ZooAnimal();
virtual ~ZooAnimal();
// ...
virtual void rotate();
protected:
int loc;
string name;
};
ZooAnimal za("Zoey");
ZooAnimal *pza = &za;
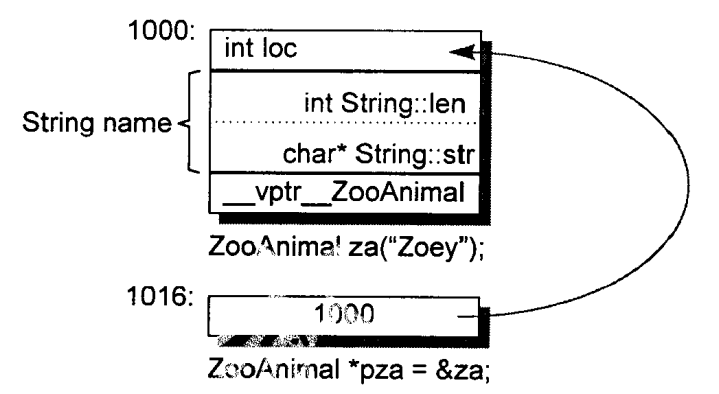
那么一个指向地址1000而类型为void *的指针, 将涵盖怎样的地址空间? 这个无从知道. 这就是为什么一个类型为void *的指针只能够持有一个地址, 而不能够通过它操作所指之object的缘故
所以转换(cast)其实是一种编译器指令. 大部分情况下它并不改变一个指针所含的真正地址, 它只影响"被指出之内存的大小和其内容"
加上多态之后
class Bear : public ZooAnimal {
public:
Bear();
~Bear();
// ...
void rotate();
virtual void dance();
// ...
protected:
enum Dances {...};
Dance dances_know;
int cell_block;
};
Bear b("Yogi");
Bear *pb = &b;
Bear &rb = *pb;
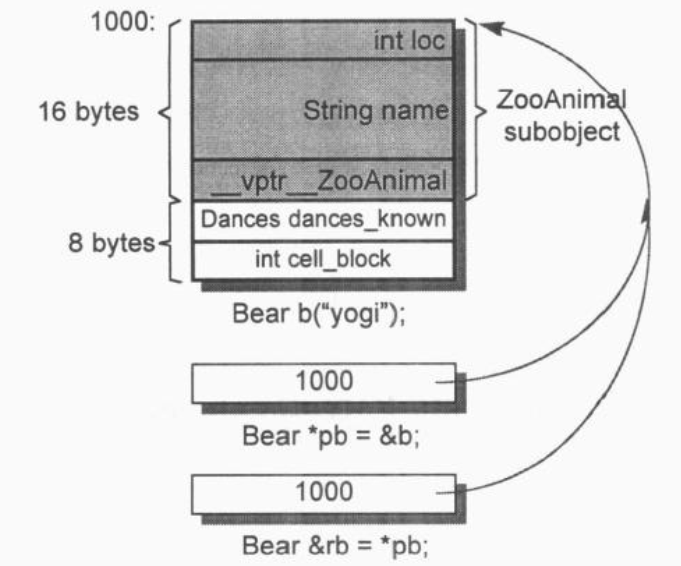
它们每个都指向Bear对象的第一个byte. 期间的差别是, pb所涵盖的地址包含整个Bear对象, 而pz所涵盖的地址只包含Bear对象中的ZooAnimal subobject. 除了ZooAnimal中出现的成员, 不能使用pz来直接处理Bear的任何成员, 可通过转换pz的类型间接实现. 唯一例外的是通过virtual机制
Bear b;
ZooAnimal *pz = &b;
Bear *pb = &b;
// 不合法: cell_block不是ZooAnimal的一个member,
// 虽然知道pz目前指向一个Bear object
pz->cell_block;
// ok: 经过一个显示的downcast操作就没有问题!
(static_cast< Bear* >( pz ))->cell_block;
// 下面这样更好, 但它是一个run-time operator(成本较高)
if ( Bear* pb2 = dynamic_cast< Bear* >(pz))
pb2->cell_block;
// ok: 因为cell_block是一个Bear的一个member
pb->cell_block;
执行pz->rotate();时, pz的类型将在编译期间决定以下两点:
- 固定可用接口. 也就是说, pz只能够调用ZooAnimal的public接口
- 该接口的access level, 例如rotate()是ZooAnimal的一个public member
在每一个执行点, pz所指的object类型可以决定rotate()所调用的实例. 类型信息的封装并不是维护于pz之中, 而是维护于link之中, 此link存在于"object的vptr"和"vptr所指的virtual table"之间(4.2节对virtual functions有一个完整的讨论)
Bear b;
ZooAnimal za = b; // 会引起切割
// 调用ZooAnimal::rotate()
za.rotate();
这里会引起两个问题: 1.为什么rotate()所调用的是ZooAnimal实例而不是Bear实例? 2.如果初始化函数讲一个对象内容完整拷贝到另一个对象去, 为什么za的vptr不指向Bear的virtual table
- za并不是(而且也绝不会是)一个Bear, 它是(并且只能是)一个ZooAnimal. 多态所造成的"一个以上的类型"的潜在力量, 并不能够实际发挥在"直接存储对象"这件事情上. 有一个似是而非的观念: OO程序设计并不支持对object的直接处理.
- 编译器在(1)初始化及(2)指定操作(将一个类对象指定给另一个类对象)之间做出了仲裁. 编译器必须确保如果某个object含有一个或一个以上的vptrs, 那些vptrs的内容不会被基类对象初始化或改变
例子:
ZooAnimal za;
ZooAnimal *pza;
Bear b;
Panda *pb = new Panda;
pza = &b;
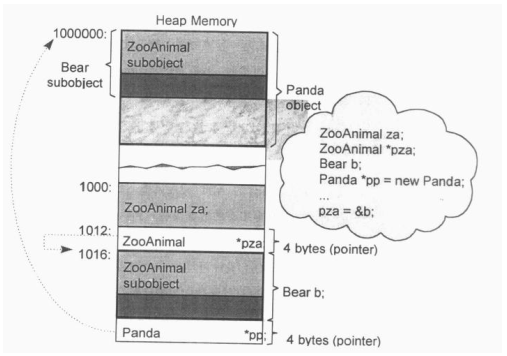
将za或b的地址, 或pp所含的内容(也就是个地址), 指定给pza, 显然不是问题. 一个pointer或一个reference之所以支持多态, 是因为它们并不引发内存中任何"与类型有关的内存委托操作(type-dependent commitment)"; 会受到改变的, 只有它们所指向的内存的"大小和内容解释方式"而已
然而, 任何人如果企图改变object za的大小, 会违反其定义中的受契约保护的"资源需求量". 如果把整个Bear object指定给za, 则会溢出它所配置得到的内存. 执行结果当然也就不对了
当一个base class object被直接初始化为(或指定为)一个derived class object时, derived object就会切割(sliced)以塞入较小的base type内存中, derived type将没有留下任何蛛丝马迹. 多态于是不再呈现, 而一个严格的编译器可以在编译时期解析一个"通过此object而触发的virtual function调用操作", 因而回避virtual机制. 如果virtual function被定义为inline, 则更有效率上的大收获
总而言之, 多态是一种威力强大的设计机制, 允许继一个抽象的public接口之后, 封装相关的类型. 需要付出的代价就是额外间接性, 不论是在"内存的获得"或是在"类型的决断"上. C++通过class的pointers和references来支持多态, 这种程序设计风格就称为"面向对象"

 浙公网安备 33010602011771号
浙公网安备 33010602011771号