
SQL语句
数据查询:SELECT
以下所有的查询都基于以下的表格:
学生表:STUDENT(SNO,Sname,ssex,sage,sdept);
课程表:course(cno,cnama,cpno,ccredit)
学生选修表:sc(sno,cno,grade)
单表查询
Select [all|distinct] 目标列表达式,…
From 表或视图
Where 条件表达式
1.Where子句常用查询条件:
- 比较:
=,>,<,>=,<=,!=,<>(不等于),!>,!< ,NOT +上述表达式
- 确定集合:
IN,NOT IN
- 字符匹配:
LIKE, NOT LIKE
- 空值:
IS NULL ,IS NOT NULL
- 多重条件:
AND ,OR,NOT
- 确定范围:
BETWEEN... AND... ,NOT BETWEEN ...AND...
当不需要where语句时,也可以省去;
如:
Select *
From sc ;
//查询sc表中所有的信息,*表示表中所有的列
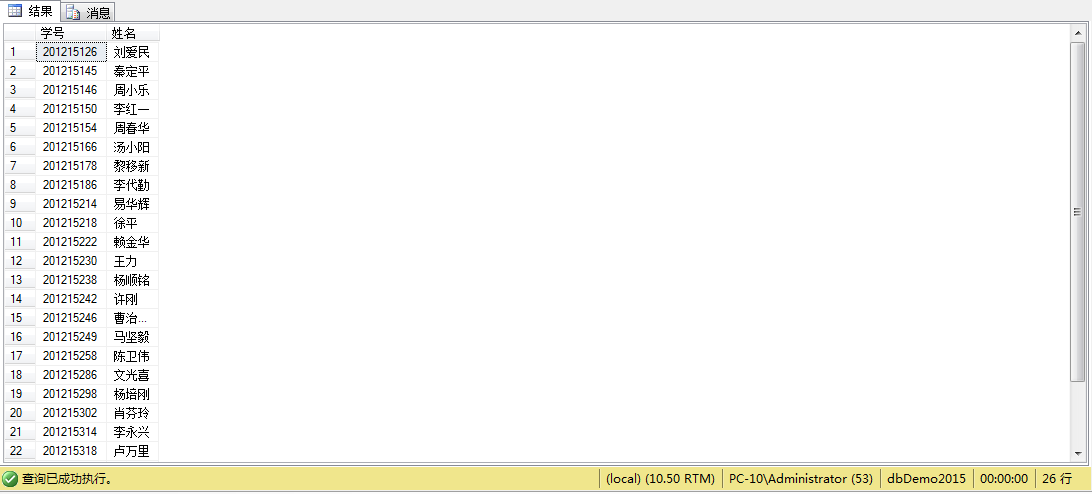
例1、查询CS系所有未成年男生的学号和姓名
select STUDENT.SNO '学号',Sname'姓名'
from STUDENT
where sdept='cs' and sage<18 and ssex='男'
LIKE :一般语法格式: [NOT] LIKE 匹配串 [escape 换码字符]
匹配串可以是一个完整的字符串,也可以是一个含有通配符%和_ 。
其中,%(百分号)代表任意长度(长度可以为0)的字符串。例如a%b :以a开头,以b结尾的任意长度的字符串。
_(下划线)代表任意单个字符。例如:a_b 表示以开头,以b结尾的长度为3的任意字符串。
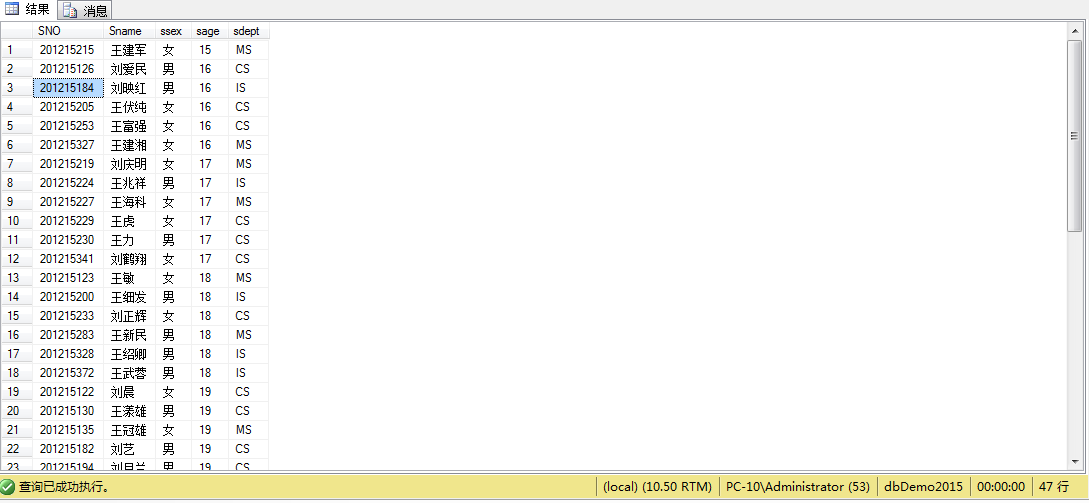
例2、查询所有姓刘以及姓王的同学的信息,并按年龄升序排列,年龄相同的按学号升序排列
select *
from STUDENT
where Sname Like '刘%'or Sname Like '王%'
order by sage asc , SNO
/*Order by 列名2 [ASC|DESC] /*对查询结果进行排序,ASC为升序,DESC 为降序,其中默认为升序*/*/
注意当查询的字符串本省含有通配符%和_时,需要使用ESCAPE<换码符>短语对通配符进行转义,
例子:
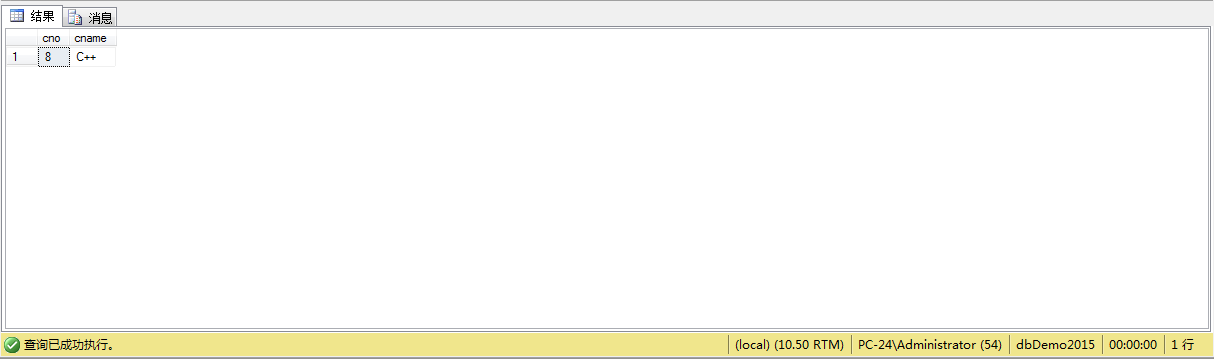
查询DB_Design课程的课程号和学分;
Select cno,ccredit
From course
Where cname like ‘DB\_Design’ escape‘\’;
escape‘\’表示‘\’为换码字符,这样匹配串中紧跟在“\”后面的字符“_”不在具有通配符的含义,转义为普通的“_”字符。
2.Order by
语法:Order by 列名2 [ASC|DESC]
对查询结果进行排序,ASC为升序,DESC 为降序,其中默认为升序
3..聚集函数:
Count(*) :统计元组的个数,可以理解为有多少行;
Count([distinct|all] 列名) :统计一列中的个数
Sum([distinct|all] 列名 ):计算一列值的总和(此列必须是数值型)
AVG([distinct|all] 列名 ):计算一列值的平均值(此列必须是数值型)
MAX([distinct|all] 列名 ):计算一列值的中的最大值
MIN([distinct|all] 列名 ):计算一列值中的最小值
Distinct:避免重复计算,ALL :计算所有的。
注意:where 子句不能用聚集函数作为条件表达式。
例子:
查询选修了课程的学生人数:
Select count(distinct sno) /*避免重复计算学生人数**/
From sc;
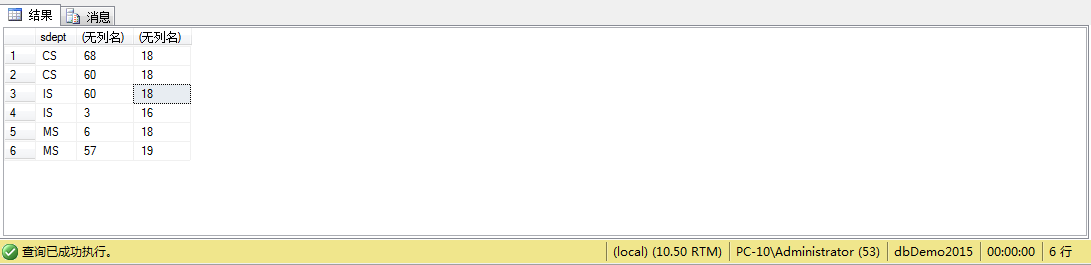
例3、查询各个系中男生和女生的总人数及平均年龄
select sdept , COUNT(sno),AVG(sage)
from STUDENT
Group by sdept ,ssex
order by sdept
4.group by:
语法:Group by 列名1 Having 条件表达式
将查询结果安某一列或多列的值来分组,值相等的为一组,分组后聚集函数将作用与每一组,也就是每一组都有一个函数值。
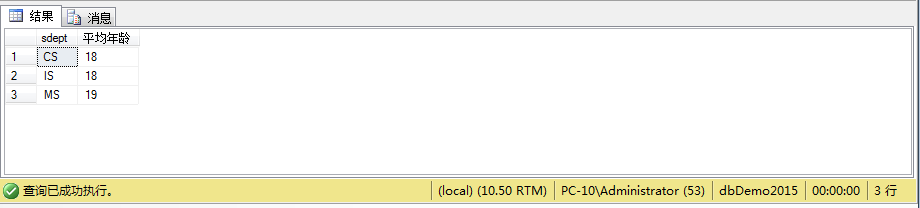
例4、查询平均年龄超过17的系
select STUDENT.sdept,AVG(sage) '平均年龄'
from STUDENT
Group By sdept
Having AVG(sage)>17;
注意:where子句和having的区别:where作用于基本表或者视图,而having作用于组(group by 语句分出来的组),同时当聚集表达式要作为条件表达式时要放在Having语句中。
例5、查询选修四门以上课程的学生总成绩(不统计不及格的课程),并要求按总成绩的降序排列出来
select sno ,SUM(grade)
from sc
group by sno
having COUNT(cno)>=4
order by SUM(grade) desc ;

连接查询:
表和表之间连接进行查询
Select student.*,sc.*
From student,sc;
这样没有连接语句的查询语句,查询出来的结果是一个迪卡集。而我们在实际的过程中,我们需要查询的是迪卡集中,有实际意义的部分,所以我们需要用到连接条件或者连接谓词,放在where语句中。
Select student.*,sc.*
From student,sc;
Where student.sno=sc.sno;/*将student和sc中同一学生的元组连接起来*/
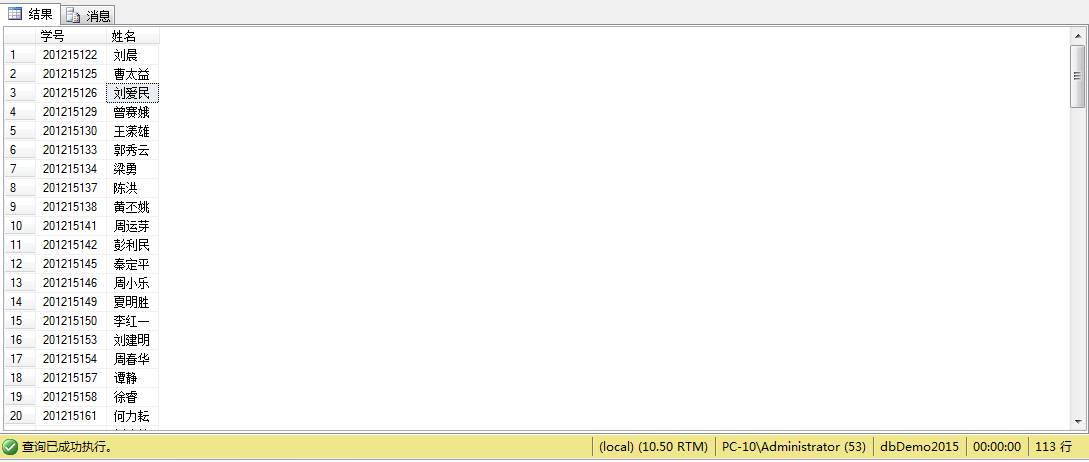
例6、查询CS系中选修了‘数据结构’课程的学生学号和姓名
select STUDENT.SNO '学号',Sname'姓名'
from STUDENT,course,sc
where sdept='cs'and cname='数据结构'
and STUDENT.SNO =sc.sno and sc.cno=course.cno
自身连接:
一个表和其自己进行连接,在这个过程中需要起一个别名来区分两个表。
例如:
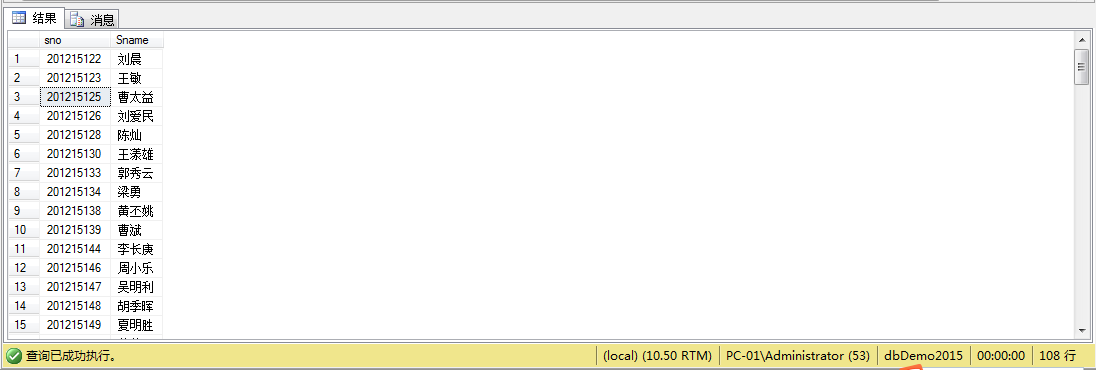
例7、查询选修课程包括“201215125”号学生所学的课程的学生学号及姓名
select distinct STUDENT.sno , STUDENT.Sname
from STUDENT,sc scx
where STUDENT.SNO=scx.sno and not exists
(
select *
from sc scy
where scy.sno='201215125'and
not exists(
select *
from sc scz
where scz.sno=scx.sno and scz.cno =scy.cno
)
);
嵌套查询
一个select—from-where 语句称为一个查询块。将一个查询语句块嵌套在另一个查询块的where子句或having短句的条件的查询称为嵌套查询。
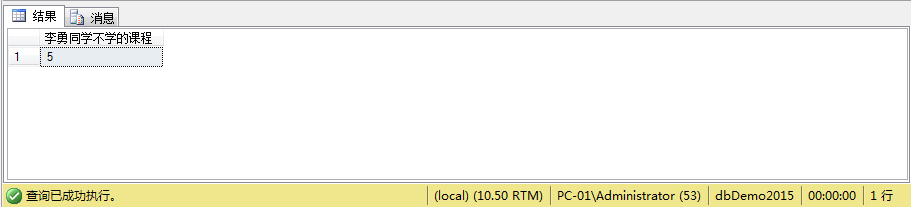
例8、查询“李勇”同学不学课程的课程号
Select course.cno 李勇同学不学的课程 /*外层循环**/
from course
where cno!=all( //!=all :不等于子查询结果中的所有值
select sc.cno /*内层循环**/
from STUDENT,sc
where STUDENT.SNO=sc.sno
and Sname='李勇');
注意:内层查询(也称为子查询)的select语句中不能使用Order By子句,order by 子句只能对最终的查询结果排序。!=all :为子查询语句的谓语,表示不等于子查询结果中的所有值。
1.带有IN谓语的子查询
外层查询结果要在子查询的结果(往往是一个集合
)中查找。
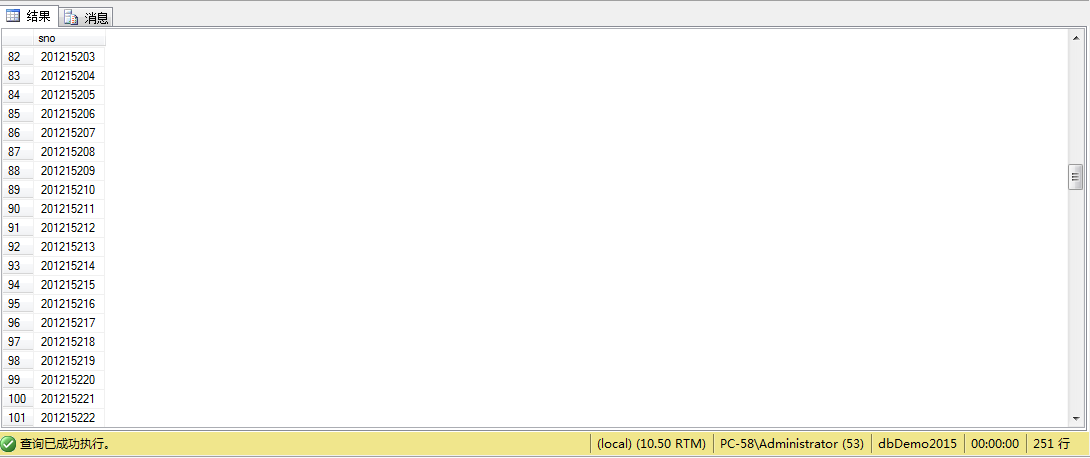
例9、查询选修课程以“数据处理”为先修课的学生学号
select distinct sno
from sc
where cno in(
select c1.cno
from course c1,course c2
where c1.cpno=c2.cno
and c2.cname ='数据处理');
2.带有比较运算负的子查询
>,<,=,>=,<=,!=或<>,当子查询语句时一个值是可以用该查询语句。
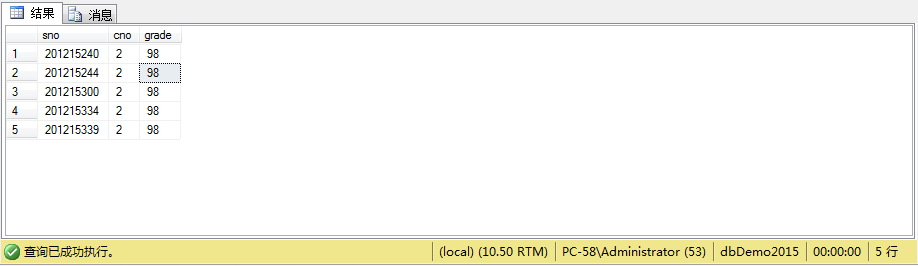
例10查询选修课程号“2”的学生中成绩最高的学生的学号
select *
from sc
where sc.cno='2'
and grade=(
select MAX(grade)
from sc
where sc.cno='2');
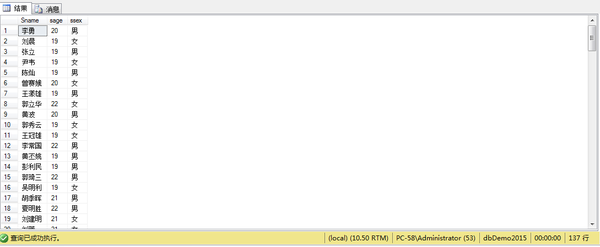
例11、查询所有比“王敏”年龄大的学生姓名、年龄和性别
select Sname,sage,ssex
from STUDENT
where sage>(
select sage
from STUDENT
where Sname='王敏')
3.带有ANY(some)或ALL谓语
>any :大于子查询结果中的某个值
>all :大于子查询结果中的所有值
<any :小于子查询结果中的某个值
<all :小于子查询结果中的所有值
>=any :大于等于子查询结果中的某个值
>=all :大于等于子查询结果中的所有值
<=any : 小于等于子查询结果中的某个值
<=all :小于等于子查询结果中的所有值
=any : 等于子查询结果中的某个值
=all :等于子查询结果中的所有值(通常没有实际意义)
!=any :不等于子查询结果中的某个值
!=all :不等于子查询结果中的任何一个值
例12、查询“李勇”同学不学课程的课程号
Select course.cno 李勇同学不学的课程
from course
where cno!=all(
select sc.cno
from STUDENT,sc
where STUDENT.SNO=sc.sno
and Sname='李勇');
4.带有exists谓语的子查询
Exists代表存在量词,带有exists谓词的子查询不返回任何数据,只产生逻辑真值“true”或者逻辑假值“false”。
Exists:当内层查询结果不为空,则外层的where子句返回真值,否则返回假值。
Not Exists:当内层查询结果为空,则外层的where子句返回真值,否则返回假值。
例子:
查询所有选修了1号课程的学生姓名
Select sname
From student
Where exists(
Select *
From sc
Where sno=student.sno and cno=’1’
);
查询没有选修了1号课程的学生姓名
Select sname
From student
Where not exists(
Select *
From sc
Where sno=student.sno and cno=’1’
);
一些带exists或 谓语的子查询不能被其他形式的子查询等价替换,但所有带in谓语,比较运算符,any和all谓语的子查询都能用带exists谓语的子句等价替换。
SQL语句中没有全称量词,但是可以用存在量词来等价替换(双重否定表肯定)。
例如:
例13、查询所有学生都选了的课程的课程号、课程名
select cno,cname
from course
where not exists
(select*
from sc scx
where not exists
(select*
from sc scy
where scy.cno=course.cno
and scy.sno=scx.sno));
集合查询:
并操作Union:从两个查询结果中取并集
交操作intersect:从两个查询结果中取交集
差操作 except:从一个查询结果中去除和另外一个查询结果中相同的值。
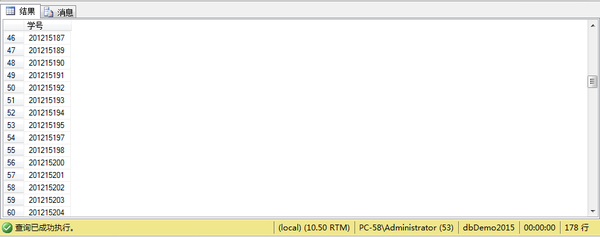
例14、查询至少学习了课程号为“1”和“2”的学生的学号
Select sno 学号
from sc
where cno ='1'
intersect
Select sno
from sc
where cno ='2'
例15、查询至少选修了1、2、3、4这几门课的学生的学号及姓名
select STUDENT.SNO,sname
from STUDENT
where STUDENT.SNO in(
Select sno 学号
from sc
where cno ='1'
intersect
Select sno
from sc
where cno ='2'
intersect
Select sno
from sc
where cno ='3'
intersect
Select sno
from sc
where cno ='4'
);
总结:
一般格式为:
Select [all|distinct] 目标列表达式,…
From 表或视图
Where 条件表达式
Group by 列名1 Having 条件表达式
Order by 列名2 [ASC|DESC]
/*all:保留结果表中取值重复的行,distinct:去掉结果表中重复的行*/
数据更新
插入元素:
Insert
Into 表名(属性列1,属性列2,...)
Value(常量,常量2 , ...);
将新元组插入到数据库中,如果在Into子句中没有出现属性列,新的元组在这些没有出现的属性列将会取空值。但是表级定义不能为空的值,不能去空,必须赋值。
另外into子句没有指明任何属性列时,新插入的元组必须在每一个属性列上都有值,而且value中常量必须和数据库中列的排列循序一样,一一对应,否则会出现错误。
插入子查询结果
Insert
Into 表名(属性列1,属性列2,...)
子查询;
修改数据
Update 表名
Set 列名=表达式,列名=表达式....
[where 条件]
删除数据
Delete
From 表名
[Where 条件]
视图:
Create view 视图名 [列名,列名]
row_number() over (partition by COL1 order by COL2) :根据COL1分组,在分组内部根据 COL2排序,而此函数计算的值就表示每组内部排序后的顺序编号(组内连续的唯一的)

