初始集群,一个真实的故事
初始集群,一个真实的故事
前言
现在,讲述一个真实的故事!
一天小黑在完成项目任务,美滋滋的开始准备和对象约会的时候。突然接到命令,公司谈了个大项目,预计一天后,将会有海量的搜索请求访问小黑写的接口。小黑慌了啊!该怎么办?该怎么办?是删库还是跑路?手里目前就运行着一台es实例、有三台备用的服务器。你自己该如何搞?赶紧拉个QQ群,把之前的朋友资源都用上!鼓捣一圈,发现没人能救得了自己!这个苦逼群主就管理自己!后来就准备死磕es了。谢天谢地,可爱的elasticsearch集群还真能救得了!
在elasticsearch中,一个节点(node)就是一个elasticsearch实例,而一个集群(cluster)由一个或多个节点组成,它们具有相同的cluster.name,它们协同工作,分享数据和负载。当加入新的节点或者删除一个节点时,集群就会感知到并平衡数据。
当Elasticsearch用于构建高可用和可扩展的系统时(解决小黑的燃眉之急)。扩展的方式可以是:
- 购买更好的服务器(纵向扩展(vertical scale or scaling up))
- 购买更多的服务器(横向扩展(horizontal scale or scaling out))
Elasticsearch虽然能从更强大的硬件中获得更好的性能,但是纵向扩展有它的局限性。真正的扩展应该是横向的,它通过增加节点来均摊负载和增加可靠性。
对于大多数数据库而言,横向扩展意味着你的程序将做非常大的改动才能利用这些新添加的设备。对比来说,Elasticsearch天生就是分布式的:它知道如何管理节点来提供高扩展和高可用。这意味着你的程序不需要关心这些。
这正好合了小黑的意,正好有三台备用服务器。只需要这个水平扩展就可以继续美滋滋的去约会了。集群看起来难,做起来——试试看!
向集群中加入节点
小黑首先在本地环境搭建集群,那么只需要三步就行了:
- 在本地单独的目录中,再复制一份elasticsearch文件
- 分别启动bin目录中的启动文件
- 貌似没有第三步了.....
然后,在浏览器地址栏输入:
http://127.0.0.1:9200/_cluster/health?pretty返回的结果中:
cluster_name "elasticsearch"
status "green"
timed_out false
number_of_nodes 2
number_of_data_nodes 2
active_primary_shards 0
active_shards 0
relocating_shards 0
initializing_shards 0
unassigned_shards 0
delayed_unassigned_shards 0
number_of_pending_tasks 0
number_of_in_flight_fetch 0
task_max_waiting_in_queue_millis 0
active_shards_percent_as_number 100通过number_of_nodes可以看到,目前集群中已经有了两个节点了。小黑一看,这完事了啊!走走走,去约会!
发现节点
小黑在约会的路上突然对一个问题很好奇,这两个es实例是如何发现相互发现,并且自动的加入集群的?谁是群主?不由自主的思考入迷......
es使用两种不同的方式来发现对方:
- 广播
- 单播
也可以同时使用两者,但默认的广播,单播需要已知节点列表来完成。
广播
当es实例启动的时候,它发送了广播的ping请求到地址224.2.2.4:54328。而其他的es实例使用同样的集群名称响应了这个请求。
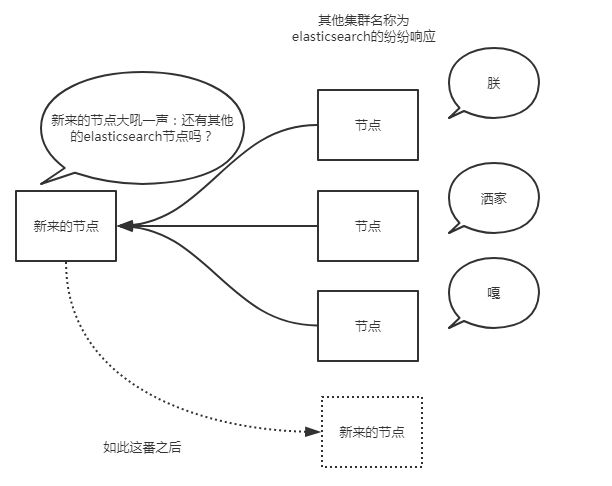
一般这个默认的集群名称就是上面的cluster_name对应的elasticsearch。通常而言,广播是个很好地方式。想象一下,广播发现就像你大吼一声:别说话了,再说话我就发红包了!然后大家纷纷响应你,这一来二去的......
但是,广播也有不好之处,是不是有人也悄悄地领了红包。
单播
当节点的ip(想象一下我们的ip地址是不是一直在变)不经常变化的时候,或者es只连接特定的节点。单播发现是个很理想的模式。使用单播时,我们告诉es集群其他节点的ip及(可选的)端口及端口范围。我们在elasticsearch.yml配置文件中设置:
discovery.zen.ping.unicast.hosts: ["10.0.0.1", "10.0.0.3:9300", "10.0.0.6[9300-9400]"]大家就像交换微信名片一样,相互传传就加群了.....
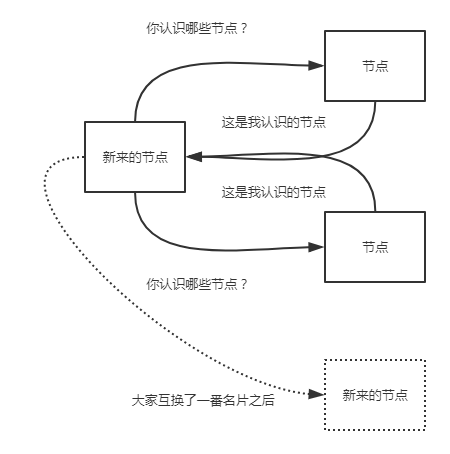
一般的,我们没必要关闭单播发现,如果你需要广播发现的话,配置文件中的列表保持空白即可。
选取主节点
无论是广播发现还是到单播发现,一旦集群中的节点发生变化,它们就会协商谁将成为主节点,elasticsearch认为所有节点都有资格成为主节点。如果集群中只有一个节点,那么该节点首先会等一段时间,如果还是没有发现其他节点,就会任命自己为主节点。
对于节点数较少的集群,我们可以设置主节点的最小数量,虽然这么设置看上去集群可以拥有多个主节点。实际上这么设置是告诉集群有多少个节点有资格成为主节点。怎么设置呢?修改配置文件中的:
discovery.zen.minimum_master_nodes: 3一般的规则是集群节点数除以2(向下取整)再加一。比如3个节点集群要设置为2。这么着是为了防止脑裂(split brain)问题。
什么是脑裂
脑裂这个词描述的是这样的一个场景:(通常是在重负荷或网络存在问题时)elasticsearch集群中一个或者多个节点失去和主节点的通信,然后小老弟们(各节点)就开始选举新的主节点,继续处理请求。这个时候,可能有两个不同的集群在相互运行着,这就是脑裂一词的由来,因为单一集群被分成了两部分。为了防止这种情况的发生,我们就需要设置集群节点的总数,否则就是节点总数除以2再加一。这样,当一个或者多个节点失去通信,小老弟们就无法选举出新的主节点来形成新的集群。因为这些小老弟们无法获取所需节点的数量。
那么,主节点是如何知道某个小老弟(节点)还活着呢?这就要说到错误识别了。
错误识别
其实错误识别,就是当主节点被确定后,建立起内部的ping机制来确保每个节点在集群中保持活跃和健康,这就是错误识别。
主节点ping集群中的其他节点,而且每个节点也会ping主节点来确认主节点还活着,如果没有响应,则宣布该节点失联。想象一下,老大要时不常的看看(循环)小弟们是否还活着,而小老弟们也要时不常的看看老大还在不在,不在了就赶紧再选举一个出来!

但是,怎么看?多久没联系算是失联?这些细节都是可以设置的,不是一拍脑门子,就说某个小老弟挂了!在配置文件中,可以设置:
discovery.zen.fd.ping_interval: 1
discovery.zen.fd.ping_timeout: 30
discovery_zen.fd.ping_retries: 3每个节点每个discovery.zen.fd.ping_interval的时间(默认1秒)发送一个ping请求,等待discovery.zen.fd.ping_timeout的时间(默认30秒),并尝试最多discovery.zen.fd.ping_retries次(默认3次),无果的话,宣布节点失联,并且在需要的时候进行新的分片和主节点选举。
根据开发环境,适当修改这些值。
小黑觉得研究的差不多了就美滋滋的要继续约会,但是恍然大悟——我是条单身狗,哪来的女朋友,就看着右手,陷入了沉思........
欢迎斧正,that's all

 浙公网安备 33010602011771号
浙公网安备 33010602011771号