zookeeper 基本原理
一。zookeeper简介
- zookeeper 是apache旗下的hadoop子项目,它一个开源的,分布式的服务协调器。同样通过zookeeper可以实现服务间的同步与配置维护。通常情况下,在分布式应用开发中,协调服务这样的工作不是件容易的事,很容易出现死锁,不恰当的选举竞争等。zookeeper就是担负起了分布式协调的重担。
zookeeper选举机制
zookeeper 默认的算法是 FastLeaderElection,采用投票数大于半数则胜出的逻辑。
相关内容: Zab协议 、数据可以两阶段提交协议
1. 与选举相关的概念
服务器 ID
比如有三台服务器,编号分别是 1,2,3。
编号越大在选择算法中的权重越大。选举状态
LOOKING,竞选状态。
FOLLOWING,随从状态,同步 leader 状态,参与投票。
OBSERVING,观察状态,同步 leader 状态,不参与投票。
LEADING,领导者状态。数据 ID
服务器中存放的最新数据 version。
值越大说明数据越新,在选举算法中数据越新权重越大。逻辑时钟
也叫投票的次数,同一轮投票过程中的逻辑时钟值是相同的。每投完一次票这个数据就会增加,然后与接收到的其它服务器返回的投票信息中的数值相比,根据不同的值做出不同的判断。
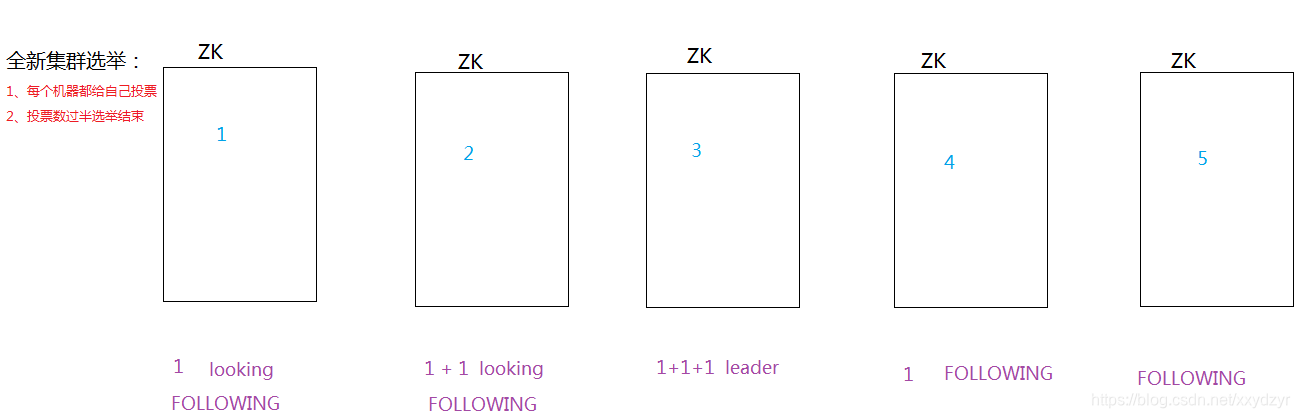
2. 全新集群选举
假设目前有 5 台服务器,每台服务器均没有数据,它们的编号分别是1,2,3,4,5,按编号依次启动,它们的选择举过程如下:
- 服务器 1 启动,给自己投票,然后发投票信息,由于其它机器还没有启动所以它收不到反馈信息,服务器 1 的状态一直属于 Looking。
- 服务器 2 启动,给自己投票,同时与之前启动的服务器 1 交换结果,由于服务器 2 的编号大所以服务器 2 胜出,但此时投票数没有大于半数,所以两个服务器的状态依然是 LOOKING。
- 服务器 3 启动,给自己投票,同时与之前启动的服务器 1,2 交换信息,由于服务器 3 的编号最大所以服务器 3 胜出,此时投票数正好大于半数,所以服务器 3 成为领导者,服务器 1,2 成为小弟。
- 服务器 4 启动,给自己投票,同时与之前启动的服务器 1,2,3 交换信息,尽管服务器 4 的编号大,但之前服务器 3 已经胜出,所以服务器 4 只能成为小弟。
- 服务器 5 启动,后面的逻辑同服务器 4 成为小弟。
![zk集群--全新集群选举流程]()
3. 非全新集群选举(大约耗时200毫秒)
对于运行正常的 zookeeper 集群,中途有机器 down 掉,需要重新选举时,选举过程就需要加入数据 ID、服务器 ID 和逻辑时钟。
**数据 ID:**数据新的 version 就大,数据每次更新都会更新 version。
**服务器 ID:**就是我们配置的 myid 中的值,每个机器一个。
**逻辑时钟:**这个值从 0 开始递增,每次选举对应一个值。 如果在同一次选举中,这个值是一致的。
这样选举的标准就变成:- 逻辑时钟小的选举结果被忽略,重新投票;
- 统一逻辑时钟后,数据 id 大的胜出;
- 数据 id 相同的情况下,服务器 id 大的胜出;
4. 原子广播
所有的写操作请求被传送给领导者,并通过广播将更新信息告诉跟随者。当大部分跟随者执行了修改之后,领导者就提交更新操作,客户端将得到更新成功的回应。未获得一致性的协议被设计为原子的,因此无论修改失败与否,他都分两阶段提交。
如果领导者出故障了,剩下存活的机器将会再次进行领导者选举,并在新领导被选出前继续执行任务。如果在不久后老的领导者恢复了,那么它将以跟随者的身份继续运行。领导者选举非常快,由发布的结果所知,大约是200毫秒,因此在选举是性能不会明显减慢。
所有在ensemble中的机器在更新它们内存中的Znode树之前会先将更新信息写入磁盘。读操作请求可由任何机器服务,同时,由于他们只涉及内存查找,因此非常快。
5. 疑惑
zookeeper是怎么知道集群大小的?
之前我们在搭建zookeeper集群时,有一个文件记录了zookeeper集群数量,忘记的可以看一下我之前的博客:Linux上搭建zookeeper集群,里面有一个步骤是添加了node-1,node-2,node-3,到配置文件中。
6. Zookeeper怎么实现它的特性的(浅显的理解)
1. 全局数据一致:数据一致性是靠Paxos算法保证的 假设有一个社团,其中有社长、社员(决议小组成员)两个角色, 每个社员都可以接受外来的消息,然后将消息递给社长处理。 然后社长向社员申请提案来修改社团制度 社员坐在一起,拿出自己收到的提案,对每个提案进行投票表决,超过半数通过即可生效 为了秩序,规定每个提案都有编号ID,按顺序自增 每个社员都有一个社团制度笔记本,上面记着所有社团制度,和最近处理的提案编号,初始为0 投票通过的规则: 新提案ID 是否大于社员本中的ID,是社员举手赞同 如果举手人数大于社员人数的半数,即让新提案生效 例如: 刚开始,每个社员本子上的ID都为0,现在有一个社员想社长提出:团费改为100元,社长收到后将这个提案的ID增加 1 每个社员都和自己ID对比,一看1>0,举手赞同,同时修改自己本中的ID为1 发出提案的社长一看超过半数同意,就宣布:1号提案生效 然后所有社员都修改自己笔记本中的团费为100元 以后任何一个社员咨询任何一个社员:"团费是多少?",社员可以直接打开笔记本查看,并回答:团费为100元 可能会有极端的情况,就是多个社员一起发出了提案,就是并发的情况 例如 刚开始,每个议员本子上的编号都为0,现在有两个议员(A和B)同时发出了提案,社长根据收到的先后顺序对编号进行赋值(队列), 那么根据自增规则,这两个提案的编号都为1,但只会有一个被先处理 假设A的提案在B的上面,议员们先处理A提案并通过了,这时,议员们的本子上的ID已经变为了1, 接下来处理B的提案,由于它的ID是1,不大于议员本子上的ID,B提案就被拒绝了,B议员需要重新发起提案 Paxos算法解决的什么问题呢,解决的就是保证每个节点执行相同的操作序列。好吧,这还不简单,master维护一个全局写队列,所有写操作都必须 放入这个队列编号,那么无论我们写多少个节点,只要写操作是按编号来的,就能保证一致性。没错,就是这样,可是如果master挂了呢。 Paxos算法通过投票来对写操作进行全局编号,同一时刻,只有一个写操作被批准,同时并发的写操作要去争取选票,只有获得过半数选票的 - zookeeper的特点:
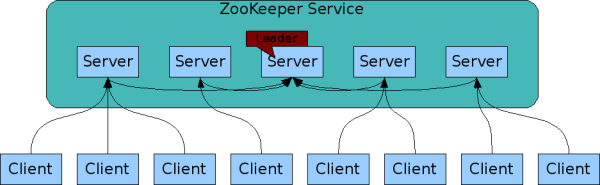
- 使用简单:ZooKeeper允许分布式程序通过一个类似于标准文件系统的共享的层次化名称空间来相互协调。名称空间由数据寄存器(称为znode)组成,在ZooKeeper中,它们类似于文件和目录。与为存储而设计的典型文件系统不同,ZooKeeper数据保存在内存中,这意味着ZooKeeper可以达到高吞吐量和低延迟数
- 同步与复制:组成ZooKeeper服务的服务器必须互相有感知。客户端连接到一个ZooKeeper服务器。客户端维护一个TCP连接,通过它发送请求、获取响应、获取观察事件和发送心跳。如果连接到服务器的TCP连接中断,客户端将连接到另一个服务器。
![]()
- 有序
- 在进行大量读操作时,运行速度奇快
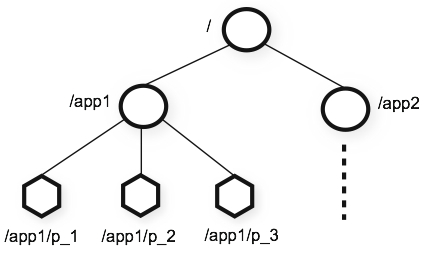
- ZooKeeper提供的名称空间非常类似于标准文件系统。名称是由斜杠(/)分隔的路径元素序列。在ZooKeeper的名称空间中,每一个节点都是通过一条路径来标识的。如图所示 :
![]()
- 当然zookeeper与标准文件系统不同的是,它的节点分为永久节点和临时节点(随着会话断开而消失)
注意以下几点:
a.不能删除已经存在子节点的节点
b.不能再临时节点上创建节点
- 客户端的节点都会被设置一个监控,当znode发生更改时,这个变化会通知所有客户端然后删除
zookeeper与eureka浅谈
一个分布式系统不可能同时满足C(一致性)、A(可用性)和P(分区容错性)
zookeeper优先保证CP,当服务发生故障会进行leader的选举,整个期间服务处在不可用状态,如果选举时间过长势必会大幅度降低性能,另外就用途来说zookeeper偏向于服务的协调,当然含有注册中心的作用
eureka优先保证AP, 即服务的节点各个都是平等的,没有leader不leader一说, 当服务发生故障时,其余的节点仍然可以提供服务,因此在出现故障时,性能表现优于zookeeper,但是可能会造成数据不一致的情况。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号