Python之旅4:酷狗音乐初次爬虫音乐播放连接,储存在MySQL数据库
导言:初次爬虫,若有不足之处,多多指正,内容借鉴一位大神爬虫经历,我这边锦上添花,添加获取音乐播放路径和连接mysql数据库等相关内容,
涉及软件: Navicat for MySQL破解版 以及 postman
爬虫数据有: 歌词,歌曲,歌手,播放路径,封面图显示,歌曲时长,歌词次数大小等等
爬虫涉及模块:



import time
import pymysql
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
import json爬虫思路以及问题:
1·hash以及mid加密问题
2·歌曲播放路径以及歌曲详情请求路径巧妙绕过方案
3·获到数据编码问题
4·歌曲页面获取localstorage以及cookie值问题
5·连接数据库储存mysql问题
解决问题过程以其中一条歌曲路径为例:
URL:https://wwwapi.kugou.com/yy/index.php?r=play/getdata&callback=jQuery19108013258872165683_1631704461109&hash=BC4E172CF13BB79303203A48246D84E1&dfid=2C8TCD3wtvFq3A2P4h4Slbtf&appid=1014&mid=ee9a0573ca7b9cda6b916c684b10b6da&platid=4&album_id=38915273&_=1631704461111
至于这条URL怎么来的,暂时不管,先分析这条get请求
·涉及参数:
1·hash:BC4E172CF13BB79303203A48246D84E1
2·dfid:2C8TCD3wtvFq3A2P4h4Slbtf
3·appid:1014
4·mid:ee9a0573ca7b9cda6b916c684b10b6da
5·platid:4
6·_:1631085855865
7·callback:jQuery19108013258872165683_1631704461109
然后再postman打开这请求:显示结果如下
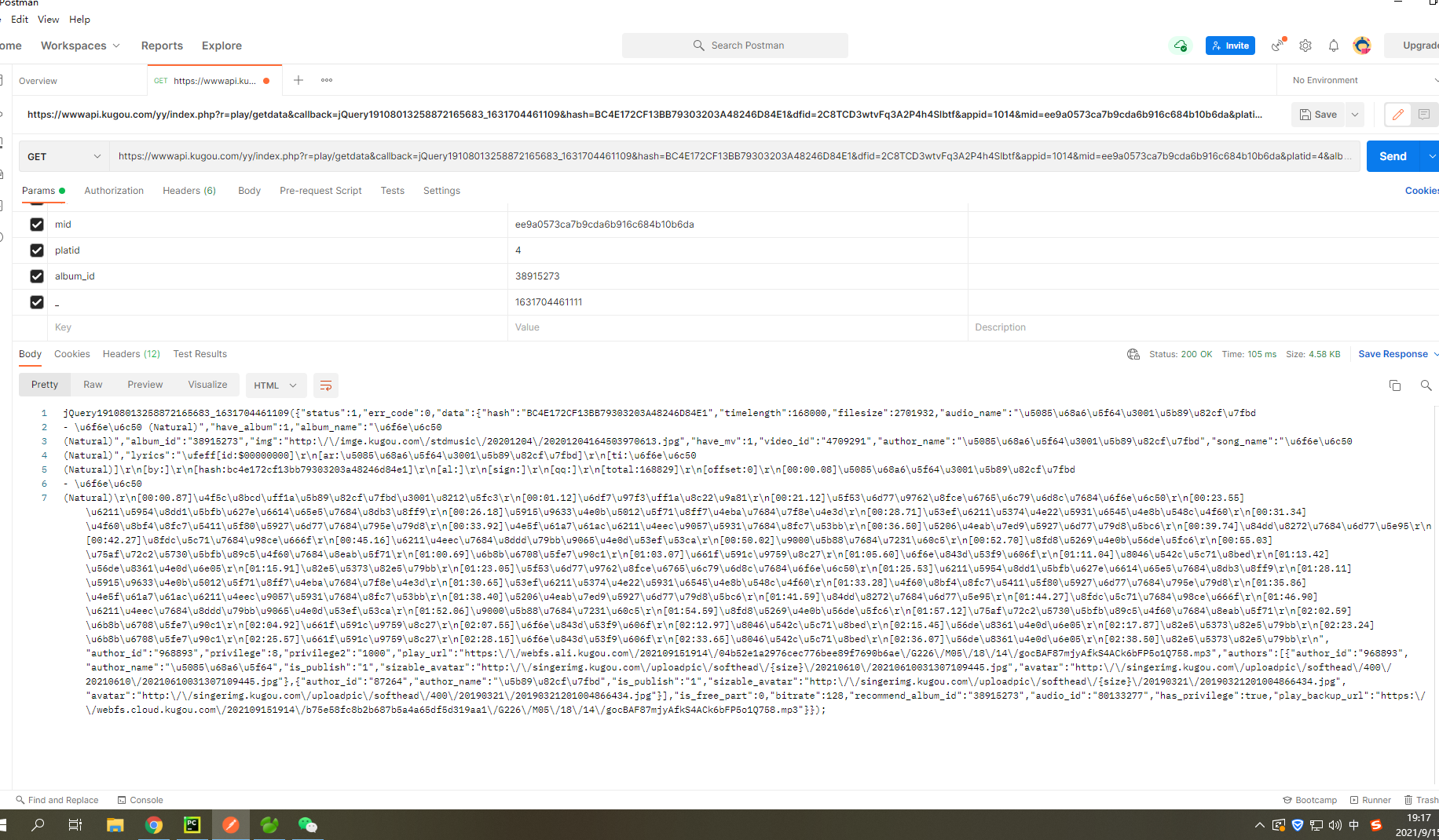
转码JSON:
jQuery19108013258872165683_1631704461109({
"status": 1,
"err_code": 0,
"data": {
"hash": "BC4E172CF13BB79303203A48246D84E1",
"timelength": 168000,
"filesize": 2701932,
"audio_name": "傅梦彤、安苏羽 - 潮汐 (Natural)",
"have_album": 1,
"album_name": "潮汐 (Natural)",
"album_id": "38915273",
"img": "http://imge.kugou.com/stdmusic/20201204/20201204164503970613.jpg",
"have_mv": 1,
"video_id": "4709291",
"author_name": "傅梦彤、安苏羽",
"song_name": "潮汐 (Natural)",
"lyrics": "[id:$00000000]\r\n[ar:傅梦彤、安苏羽]\r\n[ti:潮汐 (Natural)]\r\n[by:]\r\n[hash:bc4e172cf13bb79303203a48246d84e1]\r\n[al:]\r\n[sign:]\r\n[qq:]\r\n[total:168829]\r\n[offset:0]\r\n[00:00.08]傅梦彤、安苏羽 - 潮汐 (Natural)\r\n[00:00.87]作词:安苏羽、舒心\r\n[00:01.12]混音:谢骁\r\n[00:21.12]当海面迎来汹涌的潮汐\r\n[00:23.55]我奔跑寻找昔日的足迹\r\n[00:26.18]夕阳下倒影迷人的美丽\r\n[00:28.71]可我却丢失故事和你\r\n[00:31.34]你说过向往大海的神秘\r\n[00:33.92]也憧憬我们遗失的过去\r\n[00:36.50]分享给大海秘密\r\n[00:39.74]蓝色的海底\r\n[00:42.27]远山的风景\r\n[00:45.16]我们的距离遥不可及\r\n[00:50.02]退守的爱情\r\n[00:52.70]还剩下回忆\r\n[00:55.03]疯狂地寻觅你的身影\r\n[01:00.69]残月忧郁\r\n[01:03.07]星夜静谧\r\n[01:05.60]潮落叹息\r\n[01:11.04]聆听山语\r\n[01:13.42]回荡不清\r\n[01:15.91]若即若离\r\n[01:23.05]当海面迎来汹涌的潮汐\r\n[01:25.53]我奔跑寻找昔日的足迹\r\n[01:28.11]夕阳下倒影迷人的美丽\r\n[01:30.65]可我却丢失故事和你\r\n[01:33.28]你说过向往大海的神秘\r\n[01:35.86]也憧憬我们遗失的过去\r\n[01:38.40]分享给大海秘密\r\n[01:41.59]蓝色的海底\r\n[01:44.27]远山的风景\r\n[01:46.90]我们的距离遥不可及\r\n[01:52.06]退守的爱情\r\n[01:54.59]还剩下回忆\r\n[01:57.12]疯狂地寻觅你的身影\r\n[02:02.59]残月忧郁\r\n[02:04.92]星夜静谧\r\n[02:07.55]潮落叹息\r\n[02:12.97]聆听山语\r\n[02:15.45]回荡不清\r\n[02:17.87]若即若离\r\n[02:23.24]残月忧郁\r\n[02:25.57]星夜静谧\r\n[02:28.15]潮落叹息\r\n[02:33.65]聆听山语\r\n[02:36.07]回荡不清\r\n[02:38.50]若即若离\r\n",
"author_id": "968893",
"privilege": 8,
"privilege2": "1000",
"play_url": "https://webfs.ali.kugou.com/202109151914/04b52e1a2976cec776bee89f7690b6ae/G226/M05/18/14/gocBAF87mjyAfkS4ACk6bFP5o1Q758.mp3",
"authors": [
{
"author_id": "968893",
"author_name": "傅梦彤",
"is_publish": "1",
"sizable_avatar": "http://singerimg.kugou.com/uploadpic/softhead/{size}/20210610/20210610031307109445.jpg",
"avatar": "http://singerimg.kugou.com/uploadpic/softhead/400/20210610/20210610031307109445.jpg"
},
{
"author_id": "87264",
"author_name": "安苏羽",
"is_publish": "1",
"sizable_avatar": "http://singerimg.kugou.com/uploadpic/softhead/{size}/20190321/20190321201004866434.jpg",
"avatar": "http://singerimg.kugou.com/uploadpic/softhead/400/20190321/20190321201004866434.jpg"
}
],
"is_free_part": 0,
"bitrate": 128,
"recommend_album_id": "38915273",
"audio_id": "80133277",
"has_privilege": true,
"play_backup_url": "https://webfs.cloud.kugou.com/202109151914/b75e58fc8b2b687b5a4a65df5d319aa1/G226/M05/18/14/gocBAF87mjyAfkS4ACk6bFP5o1Q758.mp3"
}
}); 通过postman对上调URL删除某些参数结果:https://wwwapi.kugou.com/yy/index.php?r=play/getdata&hash=BC4E172CF13BB79303203A48246D84E1&appid=1014&mid=ee9a0573ca7b9cda6b916c684b10b6da&album_id=38915273
这条请求数据结果和上述结果是一样的,有意思了,经过排除,我们通过以下几个参数照样能够获取到我们想要的数据
4个必需参数:
1·r=play/getdata
2·hash=BC4E172CF13BB79303203A48246D84E1
3·mid=ee9a0573ca7b9cda6b916c684b10b6da
4·album_id=38915273
接下来就是推测这些参数的大致作用,方便从网页爬取,hash和mid,加密的意思!我们爬取的一条一条音乐数据,一个网页(我们爬取的是酷狗音乐排行榜播放详情页的数据)只有一条音乐数据,应该hash和mid对应的是单独一条音乐数据,参数r是固值
剩下的就是 album_id这一个参数啦
接下来就是怎么找参数啦
爬虫目标网址:https://www.kugou.com/yy/rank/home/
目标名称:酷狗音乐飙升榜全部音乐
随便点开一个音乐,我这边点开的是第一个:https://www.kugou.com/song/1lnk4m0b.html#hash=C2BF05871AC21B3928F63AB8EE3890EF&album_id=48707908
按F12刷新,点击media栏目会有一条音频数据:https://webfs.ali.kugou.com/202109161024/9fe5a6a564d487a4701d1454223ea008/KGTX/CLTX001/c2bf05871ac21b3928f63ab8ee3890ef.mp3
截图如下:
瞅到没,有个坏家伙cookie朝着你笑呢!kg_mid,我们再找找其他参数
想着cookie有数据,我顺便看看本地储存有木有,好家伙,让我直接发现了这个,赶紧上图:

这下好了,参数全到手了
接下来就是通过Python打开浏览器页面获取本地储存数据,然后请求获到数据保存到mysql,先获取20条试试!
tips:localStorage数据获取需要用到chromedriver.exe驱动谷歌浏览器,版本与自己的谷歌浏览器版本相近网上有下载,这里不赘述了
我就直接上源码了,涉及连接mysql数据库感兴趣的话点这里!
import time
import pymysql
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
import json
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:58.0) Gecko/20100101 Firefox/58.0'}
# 固值 callback 可选 _ 可选
# dfid = '2C8TCD3wtvFq3A2P4h4Slbtf'
appid = '1014'
# mid = 'ee9a0573ca7b9cda6b916c684b10b6da'
platid = '4'
r = 'play/getdata'
def top(conn, cursor,url):
html = requests.get(url, headers=headers)
soup = BeautifulSoup(html.text, 'lxml')
No = soup.select('.pc_temp_num')
titles = soup.select('.pc_temp_songname')
href = soup.select('.pc_temp_songname')
time = soup.select('.pc_temp_time')
for No, titles, time, href in zip(No, titles, time, href):
data = {
'NO': No.get_text().strip(),
'titles': titles.get_text(),
'time': time.get_text().strip(),
'href': href.get('href')}
print(data)
GetCurrentPageLocalStorage(conn, cursor, href.get('href'))
# 获取当前页面localStorage储存的 jStorage 和 kg_mid的值 cookie值 中的dfid值, mid值
def GetCurrentPageLocalStorage(conn, cursor, href):
browser = webdriver.Chrome(
executable_path='C:\\Users\Administrator\AppData\Local\Programs\Python\Python39\chromedriver.exe')
browser.get(href)
kg_mid = browser.execute_script("return localStorage.getItem('kg_mid')")
jStorage = browser.execute_script("return localStorage.getItem('jStorage')")
cookies = browser.get_cookies()
# print('kg_mid:', kg_mid, "jStorage:", jStorage)
OjectJson = json.loads(jStorage)["k_play_list"]
formatPlay = json.loads(OjectJson)
# print('formatPlay:', formatPlay)
mid = kg_mid
hash = formatPlay[0]["hash"]
# print('hash:', hash)
album_id = formatPlay[0]["album_id"]
html = requests.get(url='https://wwwapi.kugou.com/yy/index.php?r=play/getdata&hash=' + str(hash) + '&mid=' + str(mid) + '&platid=' + str(platid) + '&album_id=' + str(album_id))
# print('kg_mid:', kg_mid, "jStorage:", jStorage)
# print('cookies:', cookies)
# print('soup:', html.json())
Deposit(conn, cursor, html.json())
# 创建数据表单
def createTable(con, cs):
cs.execute("create table if not exists kugouMusic (audio_name varchar(1000), img varchar(1000), song_name varchar(100) primary key,\
timelength varchar(100), filesize varchar(100), language varchar(100), \
video_id varchar(100), \
author_name varchar(100), album_id varchar(100), play_backup_url varchar(500), lyrics varchar(2000),play_url varchar(1000))")
# 提交事务:
con.commit()
# 酷狗音乐存入数据库 audio_name img song_name timelength filesize language video_id author_name album_id play_backup_url lyrics play_url
def Deposit(con, cs, data):
music_data = data['data']
description = music_data
lyrics = description['lyrics']
img = description['img']
song_name = description['song_name']
timelength = description['timelength']
filesize = description['filesize']
language = description['privilege']
video_id = description['video_id']
album_id = description['album_id']
play_backup_url = description['play_backup_url']
play_url = description['play_url']
author_name = description['author_name']
audio_name = description['audio_name']
try:
cs.execute(
'insert into kugouMusic values (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)', \
(audio_name, img, song_name, timelength, filesize, language, video_id, author_name, album_id, play_backup_url, lyrics, play_url))
except:
pass
finally:
con.commit()
if __name__ == '__main__':
urls = {'http://www.kugou.com/yy/rank/home/{}-8888.html'.format(str(i)) for i in range(1, 2)}
# 连接MySQL数据库
conn = pymysql.connect(host='127.0.0.1', user='root', password='123', db='music', charset='utf8')
cursor = conn.cursor()
createTable(conn, cursor)
for url in urls:
time.sleep(5)
top(conn, cursor, url)
# 关闭数据库
cursor.close()
conn.close()
print('所有页面地址爬取完毕!')


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构