数组[切片]、字典、函数
目录:
1:数组【切片】
2:字典
3:new和make区别
3:函数
4:模块里的特殊函数 init
一、数组【切片】
数组和切片的区别就是一个是固定长度一个不固定。
- 不定长,可以跟Python一样append追加元素
- 定长你定义变量的时候前面写数字、不定长 前面不写数字呗!!
- 切片的底层也是数组
names := []string{"cfp","lixiao","haha"}
names = append(names,"大神")
//意思是:使用append函数 找到names 然后加一个元素,放到堆上,然后再赋值给names变量。记住append(names,"大神") 单单这样,names是不会改变的。
1.1:数组定义
//var 数组变量名 [元素数量]Type //默认数组中的值是类型的默认值 var arr [3]int
1.2:对数组赋值
1:初始化赋值
var arr [3]int = [3]int{1,2,3}
//如果第三个不赋值,就是默认值0
var arr [3]int = [3]int{1,2}
//可以使用简短声明
arr := [3]int{1,2,3}
//如果不写数据数量,而使用...,表示数组的长度是根据初始化值的个数来计算
arr := [...]int{1,2,3}
2:通过下标赋值
func main() {
var arr [3]int
arr[0] = 5
arr[1] = 6
arr[2] = 7
}
1.3:数组取值
1:通过索引下标取值,索引从0开始
func main() {
var arr [3]int
arr[0] = 5
arr[1] = 6
arr[2] = 7
fmt.Println(arr[0])
fmt.Println(arr[1])
fmt.Println(arr[2])
}
2:for range获取
for index,value := range arr{
fmt.Printf("索引:%d,值:%d \n",index,value)
}
1.4:数组比较
如果两个数组类型相同(包括数组的长度,数组中元素的类型)的情况下,我们可以直接通过较运算符(==和!=)来判断两个数组是否相等,
只有当两个数组的所有元素都是相等的时候数组才是相等的,不能比较两个类型不同的数组,否则程序将无法完成编译。
a := [2]int{1, 2}
b := [...]int{1, 2}
c := [2]int{1, 3}
fmt.Println(a == b, a == c, b == c) // "true false false"
d := [3]int{1, 2}
fmt.Println(a == d) // 编译错误:无法比较 [2]int == [3]int
1.5:
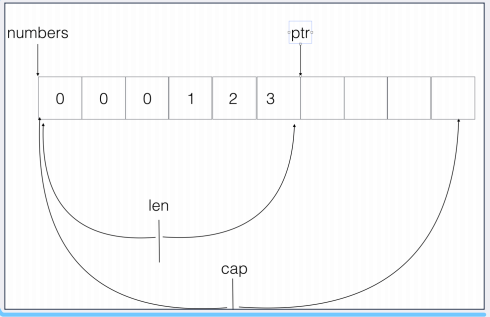
make( []Type, size, cap )
a := make([]int, 2) b := make([]int, 2, 10) fmt.Println(a, b) //容量不会影响当前的元素个数,因此 a 和 b 取 len 都是 2 //但如果我们给a 追加一个 a的长度就会变为3 fmt.Println(len(a), len(b))
使用 make() 函数生成的切片一定发生了内存分配操作,但给定开始与结束位置(包括切片复位)的切片只是将新的切片结构指向已经分配好的内存区域,
设定开始与结束位置,不会发生内存分配操作。
注意点:切片中的len() 和cap()的概念。切⽚的扩容机制,append的时候,如果⻓度增加后超过容量,则将容量增加2倍
1.6:切片复制
使用自由函数copy
Go语言的内置函数 copy() 可以将一个数组切片复制到另一个数组切片中,如果加入的两个数组切片不一样大,就会按照其中较小的那个数组切片的元素个数进行复制。
copy() 函数的使用格式如下:
copy( destSlice, srcSlice []T) int
其中 srcSlice为数据来源切片,destSlice为复制的目标(也就是将 srcSlice 复制到 destSlice),目标切片必须分配过空间且足够承载复制的元素个数,并且来源和目标的类型必须一致,copy() 函数的返回值表示实际发生复制的元素个数。
下面的代码展示了使用 copy() 函数将一个切片复制到另一个切片的过程:
slice1 := []int{1, 2, 3, 4, 5}
slice2 := []int{5, 4, 3}
copy(slice2, slice1) // 只会复制slice1的前3个元素到slice2中
copy(slice1, slice2) // 只会复制slice2的3个元素到slice1的前3个位置
二、字典(map)
字典和Python的字典一样的,也是key/value。存储的key是经过哈希运算的。
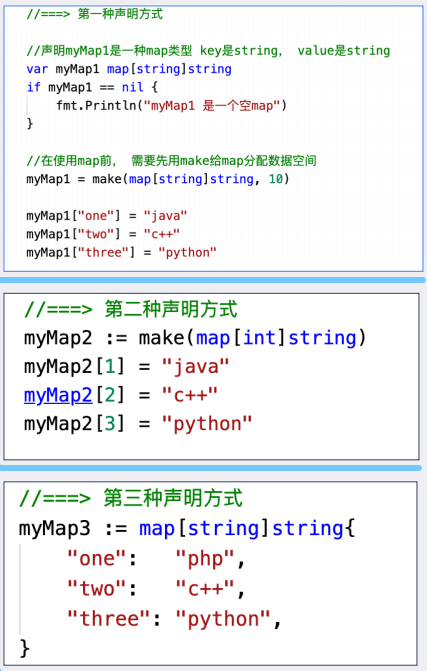
2.1:声明方式
2.2:注意点
注意点1!使用字典一定要先分配空间
注意点2!在map中不存在访问越界的问题,它认为所有的key都是有效的。不像Python如果你dict["不存在的key"]就会报错!,所以访问一个不存在的key不会崩溃,它会返回这个类型的零值。
所以无法通过获取value来判断一个key是否存在,因此我们需要一个能够校验key是否存在的方式!
以下方式:
value,ok := idnames[1]
如何id=1是存在的,value就是该key的值,此时的ok是true。反之如何id=1不存在,value就是零值,ok是false。
注意点3:并发任务处理的时候,需要对map进行上锁,要不然你有人读有人写,go程序会崩溃的。
使用自由函数删除
delete(指定那个map,指定要删除哪个key)
2.3:
并发情况下读写 map 时会出现问题,代码如下:
// 创建一个int到int的映射
m := make(map[int]int)
// 开启一段并发代码
go func() {
// 不停地对map进行写入
for {
m[1] = 1
}
}()
// 开启一段并发代码
go func() {
// 不停地对map进行读取
for {
_ = m[1]
}
}()
// 无限循环, 让并发程序在后台执行
for {
}
运行代码会报错,输出如下:
fatal error: concurrent map read and map write
错误信息显示,并发的 map 读和 map 写,也就是说使用了两个并发函数不断地对 map 进行读和写而发生了竞态问题,map 内部会对这种并发操作进行检查并提前发现。
需要并发读写时,一般的做法是加锁,但这样性能并不高,Go语言在 1.9 版本中提供了一种效率较高的并发安全的 sync.Map,sync.Map 和 map 不同,不是以语言原生形态提供,而是在 sync 包下的特殊结构。
sync.Map 有以下特性:
-
无须初始化,直接声明即可。
-
sync.Map 不能使用 map 的方式进行取值和设置等操作,而是使用 sync.Map 的方法进行调用,Store 表示存储,Load 表示获取,Delete 表示删除。
-
使用 Range 配合一个回调函数进行遍历操作,通过回调函数返回内部遍历出来的值,Range 参数中回调函数的返回值在需要继续迭代遍历时,返回 true,终止迭代遍历时,返回 false。
package main
import (
"fmt"
"sync"
)
func main() {
//sync.Map 不能使用 make 创建
var scene sync.Map
// 将键值对保存到sync.Map
//sync.Map 将键和值以 interface{} 类型进行保存。
scene.Store("greece", 97)
scene.Store("london", 100)
scene.Store("egypt", 200)
// 从sync.Map中根据键取值
fmt.Println(scene.Load("london"))
// 根据键删除对应的键值对
scene.Delete("london")
// 遍历所有sync.Map中的键值对
//遍历需要提供一个匿名函数,参数为 k、v,类型为 interface{},每次 Range() 在遍历一个元素时,都会调用这个匿名函数把结果返回。
scene.Range(func(k, v interface{}) bool {
fmt.Println("iterate:", k, v)
return true
})
}
make 关键字的主要作用是创建 slice、map 和 Channel 等内置的数据结构,而 new 的主要作用是为类型申请一片内存空间,并返回指向这片内存的指针。
-
make 分配空间后,会进行初始化,new分配的空间被清零
-
new 分配返回的是指针,即类型 *Type。make 返回引用,即 Type;
-
new 可以分配任意类型的数据;
四、函数
函数返回值可以一个或者多个。多个返回值一定要加括号
func test(a int ,b int ,c string) (int,string) {
return a+b,c
}
func test(a int, b int, c string) (res int, str string) {
res = a + b
str = c
return
}
使用函数
package main
import "fmt"
func test(a int, b int, c string) (res int, str string) {
res = a + b
str = c
return
}
func main() {
res, _ := test(12, 23, "s") //ctrl+shift+i 可以查看形参类型
fmt.Println(res)
}
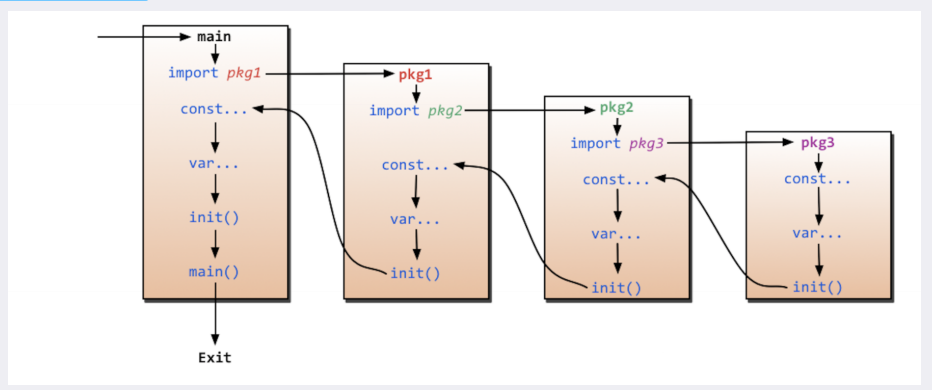
四、特殊函数
init函数,他是按深度来的一个个执行import模块里面的init方法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号