内存逃逸、枚举、字符串
目录
1:内存逃逸
2:枚举iota
3:字符串
4:类型转换
一、内存逃逸
理解堆、栈
1:堆(heap):堆是用于存放进程执行中被动态分配的内存段。它的大小并不固定,可动态扩张或缩减。当进程调用 malloc 等函数分配内存时,
新分配的内存就被动态加入到堆上(堆被扩张)。当利用 free 等函数释放内存时,被释放的内存从堆中被剔除(堆被缩减);
2:栈(stack):栈又称堆栈, 用来存放程序暂时创建的局部变量,也就是我们函数的大括号{ }中定义的局部变量。
栈是先进后出,往栈中放元素的过程,称为入栈,取元素的过程称为出栈。
栈可用于内存分配,栈的分配和回收速度非常快
在程序的编译阶段,编译器会根据实际情况自动选择在栈或者堆上分配局部变量的存储空间,不论使用 var 还是 new 关键字声明变量都不会影响编译器的选择。
var global *int
func f() {
var x int
x = 1
global = &x
}
func g() {
y := new(int)
*y = 1
}
用Go语言的术语说,这个局部变量 x 从函数 f 中逃逸了(原本在栈上面的,跑了堆上。就叫做内存逃逸)。
相反,当函数 g 返回时,变量 y 不再被使用,也就是说可以马上被回收的。因此,y 并没有从函数 g 中逃逸,
编译器可以选择在栈上分配 *y 的存储空间,也可以选择在堆上分配,然后由Go语言的 GC(垃圾回收机制)回收这个变量的内存空间。
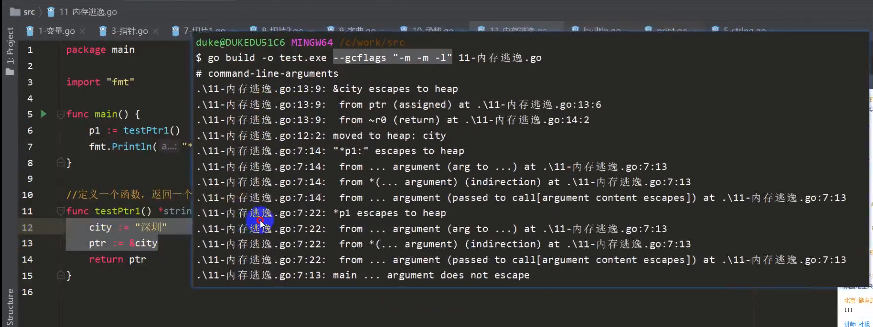
&city escapes to heap city逃逸到堆上面去了
所以我们知道是存在这个内存逃逸现象的,对程序员来说不用担心内存会不会泄露的问题。
二、枚举
这玩意还是比较有用的,比如我们一年12月:January 就表示 1 February表示2
package main
import "fmt"
const (
January = iota+1 //iota自增 从0开始
February
March
April
May
June
)
func main() {
fmt.Println(January) //1
fmt.Println(June) //6
}

三、字符串
3.1:字符串的定义
一个字符串的底层其实就是一个不可改变的字节序列。
var mystr string = "hello"
-
-
\r:回车符 -
\t:tab 键 -
\u 或 \U:Unicode 字符 -
\
func main() {
fmt.Println(`\t 码神之路Go大法好`) // \t 码神之路Go大法好
fmt.Println(`\t 码神之路
Go大法好`) //使用反引号 可以进行字符串换行
//反引号一般用在 需要将内容进行原样输出的时候 使用
}
字符串是字节的定长数组,byte 和 rune 都是字符类型,若多个字符放在一起,就组成了字符串
import (
"fmt"
)
func main() {
var mystr01 string = "hello"
var mystr02 [5]byte = [5]byte{104, 101, 108, 108, 111}
fmt.Printf("myStr01: %s\n", mystr01)
fmt.Printf("myStr02: %s", mystr02)
}
思考:hello,码神之路 占用几个字节
package main
import (
"fmt"
)
func main() {
//中文三字节,字母一个字节
var myStr01 string = "hello,码神之路"
fmt.Printf("mystr01: %d\n", len(myStr01))
}
3.2:字符串的应用
获取字符串的字节长度
func main() {
//中文三字节,字母一个字节
var myStr01 string = "hello,码神之路"
fmt.Printf("mystr01: %d\n", len(myStr01)) //18
}
获取字符串的字符长度
func main() {
//如何计算字符串的长度
str3 := "hello"
str4 := "你好"
fmt.Println(len(str3)) // 1个字母占1个字节
fmt.Println(len(str4)) // 1个中文占3个字节,go从底层支持utf8
fmt.Println(utf8.RuneCountInString(str4)) // 2
}
获取字符串指定位置内容(只能针对纯 ASCII 码,中括号代码取的第几个字节)
-
-
第 i 个字节:str[i - 1]
-
func main() {
//如何计算字符串的长度
str3 := "hello"
str4 := "你好"
fmt.Printf("%s\n",str3+str4) //第一种:使用+号 hello你好
//第二种使用WriteString()
var stringBuilder bytes.Buffer
//节省内存分配,提高处理效率
stringBuilder.WriteString(str3)
stringBuilder.WriteString(str4)
fmt.Println(stringBuilder.String()) //hello你好
}
思考:如果从字符串 hello 码神之路 中获取 码 该如何获取呢?
func main() {
var myStr01 string = "hello,码神之路"
a := []rune(myStr01)
fmt.Println(a) //[104 101 108 108 111 44 30721 31070 20043 36335]
fmt.Println(string(a)) //hello,码神之路
fmt.Println(string([]rune(myStr01)[6])) //码
}
//要知道字符串的底层是byte的字节数组,我们可以将字符串先变成 rune类型的数组数组。然后再进行取值
字符串遍历
func main() {
var str1 string = "hello"
var str2 string = "hello,码神之路"
// 遍历
for i :=0; i< len(str1); i++{
fmt.Printf("ascii: %c %d\n", str1[i], str1[i])
}
for _, s := range str1{
fmt.Printf("unicode: %c %d\n ", s, s)
}
// 中文只能用 for range
for _, s := range str2{
fmt.Printf("unicode: %c %d\n ", s, s)
}
}
字符串的格式化
-
print :结果写到标准输出 -
Sprint:
func main() {
str1 := "你好,"
str2 := "码神之路"
var stringBuilder bytes.Buffer
stringBuilder.WriteString(str1)
stringBuilder.WriteString(str2)
// Sprint 以字符串形式返回
result := fmt.Sprintf(stringBuilder.String())
fmt.Println(result)
}
- %c 单一字符
- %T 动态类型
- %v 本来值的输出
- %+v 字段名+值打印
- %d 十进制打印数字
- %p 指针,十六进制
- %f 浮点数
- %b 二进制
- %s string
字符串查找
如何获取字符串中的某一段字符?
-
strings.Index(): 正向搜索子字符串
-
strings.LastIndex():反向搜索子字符串
package main
import (
"fmt"
"strings"
)
func main() {
// 查找
tracer := "码神来了,码神bye bye"
// 正向搜索字符串
comma := strings.Index(tracer, ",")
fmt.Println(",所在的位置:",comma)
fmt.Println(tracer[comma+1:]) // 码神bye bye
add := strings.Index(tracer, "+")
fmt.Println("+所在的位置:",add) // +所在的位置: -1
pos := strings.Index(tracer[comma:], "码神")
fmt.Println("码神,所在的位置", pos) // 码神,所在的位置 1
fmt.Println(comma, pos, tracer[5+pos:]) // 12 1 码神bye bye
}
四、类型转换
//类型 B 的值 = 类型 B(类型 A 的值) valueOfTypeB = type B(valueOfTypeA)
示例:
a := 5.0 b := int(a)
整数 与 字符串转换
// 字符串与其他类型的转换
// str 转 int
newStr1 := "1"
intValue, _ := strconv.Atoi(newStr1)
fmt.Printf("%T,%d\n", intValue, intValue) // int,1
// int 转 str
intValue2 := 1
strValue := strconv.Itoa(intValue2)
fmt.Printf("%T, %s\n", strValue, strValue)
浮点数 与字符串
// str 转 float
string3 := "3.1415926"
f,_ := strconv.ParseFloat(string3, 32)
fmt.Printf("%T, %f\n", f, f) // float64, 3.141593
//float 转 string
floatValue := 3.1415926
//4个参数,1:要转换的浮点数 2. 格式标记(b、e、E、f、g、G)
//3. 精度 4. 指定浮点类型(32:float32、64:float64)
// 格式标记:
// ‘b’ (-ddddp±ddd,二进制指数)
// ‘e’ (-d.dddde±dd,十进制指数)
// ‘E’ (-d.ddddE±dd,十进制指数)
// ‘f’ (-ddd.dddd,没有指数)
// ‘g’ (‘e’:大指数,‘f’:其它情况)
// ‘G’ (‘E’:大指数,‘f’:其它情况)
//
// 如果格式标记为 ‘e’,‘E’和’f’,则 prec 表示小数点后的数字位数
// 如果格式标记为 ‘g’,‘G’,则 prec 表示总的数字位数(整数部分+小数部分)
formatFloat := strconv.FormatFloat(floatValue, 'f', 2, 64)
fmt.Printf("%T,%s",formatFloat,formatFloat)
注意:使用内置库strings是对字符串的一系列方法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号