

ID和Phone高压缩比存储和查询
ID和Phone高压缩比存储和查询的简单例子, 无多线程处理
运行环境JDK8+maven
0. 模块分割
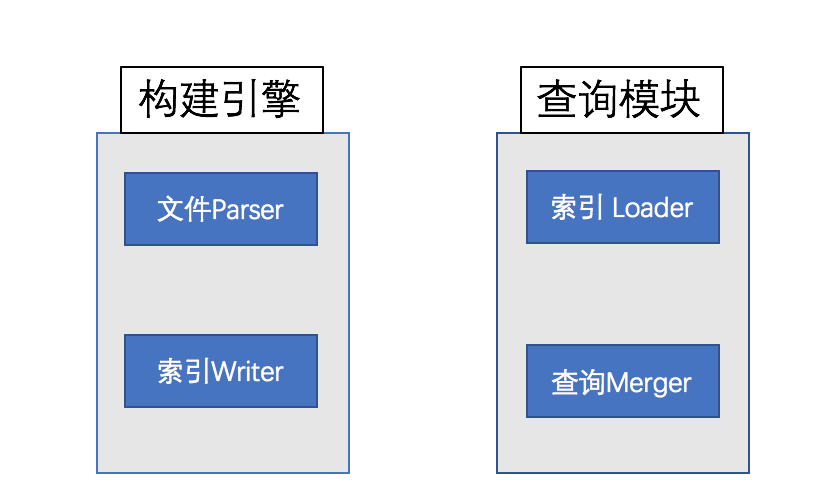
1. 基本思路
源文件BCP每一行都转为一个全局的RowID,可以直接映射到FileName+文件偏移+行字节数。
身份证,手机号都按照文件映射到 IDtoRowIds, PhonetoRowIds。
所有数据都写入磁盘的索引,通过LRU的堆缓存+操作系统的PageCache来进行快速读取使用。
查询的思路就是通过ID or Phone,通过Bloom过来处理那些索引是需要加载的;获取到对应的RowID列表后,
进行了Merge后,直接拉取源文件的偏移量快速定位的行上。
PS. 为什么不重新把原数据写成新的数据文件,主要是针对业务特点,可以按文件名淘汰旧文件,加入新的数据文件。而不需要全量更新索引和数据。
2. 基于数据的压缩
18身份证: 可以表达为 city + year + 序列号
其中city 可以用3000+的char来表示;year跟进业务特点根据人类不超过128岁的,可以压缩为1个char;后面的seq最多为999X,也可以压缩为一个char。最多三个char
手机号:直接转为Long略位浪费,由于运营商的可枚举,直接将其前三位转为char来表示。最多两个char
3. 巨人的奖杯
索引序列化采用Kryo,具有有高性能序列化,高压缩比。
大量未知数据最好选择bloom算法,但是Java的Bitset存储太浪费,故采用了RoaringBitmap
4. 未来优化方向
B+树来缓存, 或者采用倒排索引的引擎
通过生产消费模式,快速构建索引
