re模块
此篇文章比较详细,写了些(?P
python-re模块 .,[],\d,\w,\s,\S,\D,\W的用法及重复匹配 https://docs.python.org/zh-cn/3/library/re.html
re模块
. 匹配除了\n之外的任意1个字符,若指定flag DOTALL,则匹配任意字符,包括换行
[ ] 匹配[ ]中列举的字符
\d 匹配数字,即0-9
\D 匹配非数字,即不是数字
\s 匹配空白,即 空格,tab键
\S 匹配非空白
\w 匹配非特殊字符,即a-z、A-Z、0-9、_、汉字
\W 匹配特殊字符,即非字母、非数字、非汉字、非_
re.match 从头开始匹配
re.search 匹配包含
re.findall 把所有匹配到的字符放到以列表中的元素返回
re.split 以匹配到的字符当做列表分隔符
re.sub 匹配字符并替换
re.fullmatch 全部匹配
Flags标志符
re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)
M(MULTILINE): 多行模式,改变'^'和'$'的行为
S(DOTALL): 改变'.'的行为,make the '.' special character match any character at all, including a newline; without this flag, '.' will match anything except a newline.
X(re.VERBOSE) 可以给你的表达式写注释,使其更可读
phones = re.findall(r'^a','abc\naeee',flags=re.MULTILINE) # 输出 ['a', 'a']
phones1 = re.findall(r'^a','abc\naeee',re.MULTILINE) # 输出 ['a', 'a'] flags可以不写
phones2 = re.findall(r'^a','abc\naeee') # 输出 ['a']
In [11]: import re
In [12]: re.findall(r'^a','abc\naeee') # 如果不指定re.MULTILINE就只能匹配一个
Out[12]: ['a']
In [13]: re.findall(r'^a','\nabc\naeee') # 如果不指定re.MULTILINE就只能匹配一个
Out[13]: []
In [20]: re.findall(r'^a','\nabc\naeee',re.MULTILINE)
Out[20]: ['a', 'a']
# re.match从字符串的第一个字符开始匹配,匹配规则带不带^无所谓
In [14]: re.match(r'^a','abc\naeee')
Out[14]: <_sre.SRE_Match object; span=(0, 1), match='a'>
In [15]: re.match(r'^a','sadfdsafabc\naeee') # 返回None
In [16]: re.match(r'a','sadfdsafabc\naeee') # 返回None
In [17]: re.search(r'a','sadfdsafdsaf')
Out[17]: <_sre.SRE_Match object; span=(1, 2), match='a'>
In [18]: re.search(r'^a','sadfdsafdsaf') # 返回None
In [19]:
phones = re.findall(r"1[358][0-9]{9}",data) # 在一串文本中寻找手机号['13651054608', '13813234424',
phones3 = re.match(r'^1[3|4|5|7|8][0-9]{9}$', '15823423525') # 中间的|可以不用
phones4 = re.match(r'^1[34578][0-9]{9}$', '15823423525') # 匹配到返回<_sre.SRE_Match object; span=(0, 11), match='15823423525'>, 否则None
phones5 = re.match(r'^1[34578][0-9]{9}$', '15823423525').group() #慎用.group() 匹配到返回 15823423525 否则报错 AttributeError: 'NoneType' object has no attribute 'group'
groups用法
import re
line = "Cats are smarter than dogs"
matchObj = re.match( r'(.*) are (.*?) .*', line, re.M|re.I)
if matchObj:
print ("matchObj.group() : ", matchObj.group())
print ("matchObj.group(0) : ", matchObj.group(0))
print ("matchObj.group(1) : ", matchObj.group(1))
print ("matchObj.group(2) : ", matchObj.group(2))
# print ("matchObj.group(2) : ", matchObj.group(3)) #
else:
print("No match!!")
将匹配的数字乘以 2
import re
def double(matched):
value = int(matched.group('value'))
return str(value * 2)
s = 'A23G4HFD567'
print(re.sub('(?P<value>\d+)', double, s))
# '^' 匹配字符开头,若指定flags MULTILINE 这种也可以匹配上(r'^:a','\nabc\neee',flags=re.MULTILINE)
# '$' 匹配字符结尾,若指定flags MULTILINE, re.search('foo.$','foo1\nfoo2\n',re.MULTILINE).group()
# '*' 匹配*号前的字符0次或者多次,re.search('a','aaaaabac') 结果'aaaa'
# '+' 匹配前一个字符1次或多次, re.findall('ab+','ab+cd+add+bba') 结果['ab','abb']
# '?' 匹配前一个字符0次或者I次, re.search('b?','alex').group() 匹配b 0次
# '{m}' 匹配前一个字符m次,re.search('b{3}','alexbbbs').group() 匹配到bbb
# '{n,m}' 匹配前一个字符n到m次, re.findall('ab{1,3}','abb abc abbcbbb')结果'abb','ab','abb'
# '|' 匹配|左或|右的字符,re.search('abc|ABC','ABCabcCD').group() 结果'ABC
# '(...)' 分组匹配, re.search("(abc){2}a(123|45)", "abcabca456c").group() 结果为'abcabca45'
# '\A' 只从字符开头匹配,re.search("\Aabc","alexabc") 是匹配不到的,相当于re.match('abc',"alexabc") 或^
# '\Z' 匹配字符结尾,同$
# '\d' 匹配数字0-9
# '\D' 匹配非数字
# '\w' 匹配[A-Za-z0-9]
# '\W' 匹配非[A-Za-z0-9]
# 's' 匹配空白字符、\t、\n、\r , re.search("\s+","ab\tc1\n3").group() 结果 '\t'
# '(?P<name>...)' 分组匹配 re.search("(?P<province>[0-9]{4})(?P<city>[0-9]{2})(?P<birthday>[0-9]{4})","371481199306143242").groupdict("city")
# 结果{'province': '3714', 'city': '81', 'birthday': '1993'}
In [21]: re.search('abc|ABC','ABCabcCD').group()
Out[21]: 'ABC'
In [22]: re.search('abc|ABC','ABCabcCD')
Out[22]: <_sre.SRE_Match object; span=(0, 3), match='ABC'>
In [23]: re.search('abc|ABC','abcABCabcCD')
Out[23]: <_sre.SRE_Match object; span=(0, 3), match='abc'>
In [24]: re.search('abc|ABC','abABCcABCabcCD')
Out[24]: <_sre.SRE_Match object; span=(2, 5), match='ABC'>
通配符
一、常用正则表达式
1、字符组
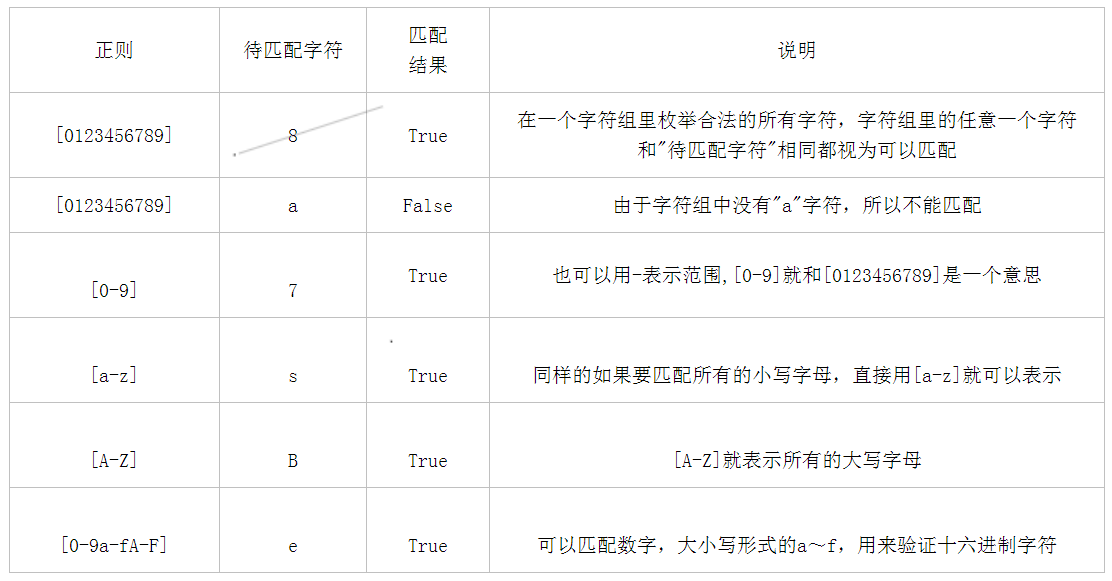
2、字符
| 元字符 | 匹配内容 | 元字符 | 匹配内容 | |
|---|---|---|---|---|
| . | 匹配除换行符以外的任意字符 | () | 匹配括号内的表达式,也表示一个组 | |
| \w | 匹配字母或数字或下划线 | \W | 匹配非字母或数字或下划线 | |
| \s | 匹配任意的空白符 | \S | 匹配非空白符 | |
| \d | 匹配数字 | \D | 匹配非数字 | |
| \n | 匹配一个换行符 | \t | 匹配一个制表符 | |
| \b | 匹配一个单词的结尾 | a | b | |
| ^ | 匹配字符串的开始 | $ | 匹配字符串的结尾 | |
| [...] | 匹配字符组中的字符 | [^...] | 匹配除了字符组中字符的所有字符 |
2、量词
| 量词 | 用法说明 | 量词 | 用法说明 | |
|---|---|---|---|---|
| * | 重复次数>=0 | + | 重复次数>=1 | |
| ? | 重复次数0或1 | 重复n到m次 | ||
| 重复n次 | 重复>=n次 |
写入自己的博客中才能记得长久

 浙公网安备 33010602011771号
浙公网安备 33010602011771号