会员
周边
新闻
博问
闪存
赞助商
YouClaw
所有博客
当前博客
我的博客
我的园子
账号设置
会员中心
简洁模式
...
退出登录
注册
登录
你是我黑夜中最亮晶晶的星(心)
功不是凭梦想和希望,而是凭努力和实践. 只愿你在诗和远方,我愿意远远看着你,守护你,祝福你.
博客园
首页
新随笔
联系
订阅
管理
2023年11月5日
pytesseract用法
摘要: import pytesseract from PIL import Image pytesseract.pytesseract.tesserac_cmd = r'D:\Tesseract-OCR\tesseract.exe' tessdat.dir.config = r'--tessdata-di
阅读全文
posted @ 2023-11-05 18:47 ty1539
阅读(45)
评论(0)
推荐(0)
2023年11月4日
python 进程池pool.map
摘要: from multiprocessing import Pool def double(x): print(x**2) return x**2 if __name__ == '__main__': pool = Pool() pool.map(double, list(range(11))) pri
阅读全文
posted @ 2023-11-04 21:55 ty1539
阅读(134)
评论(0)
推荐(0)
2023年10月29日
python eval,类似ast.literal_eval, 据说是速度快于eval,没有验证过
摘要: expr_str="[1,2,3]" my_list=eval(expr_str) print(repr(my_list),type(my_list)) # [1,2,3] print(repr(expr_str),type(expr_str)) #'[1,2,3]' import ast # 用i
阅读全文
posted @ 2023-10-29 17:18 ty1539
阅读(62)
评论(0)
推荐(0)
列表包裹元组,指定元组中数字大小排序字段operator用法
摘要: import operator somelist = [(1,5,8),(6,2,4),(9,7,5)] somelist.sort(key=operator.itemgetter(0)) print(somelist) # [(1, 5, 8), (6, 2, 4), (9, 7, 5)] som
阅读全文
posted @ 2023-10-29 17:02 ty1539
阅读(31)
评论(0)
推荐(0)
2023年8月14日
特别的二进制运算
摘要: ``` ## 快速求2的n次幂 print(10>>1) print(13>>1) print(131011 if (x & 1) == 0: print( 'x是偶数') else: print( 'x是奇数') ``` ``` ''' 交换两个元素''' a, b = 1, 2 a ^= b b
阅读全文
posted @ 2023-08-14 13:57 ty1539
阅读(35)
评论(0)
推荐(0)
2023年6月13日
golang 闭包,装饰器
摘要: ``` package main import ( "fmt" "strings" ) func makeSuffixFunc(suffix string) func(string) string { return func(name string) string { if !strings.Has
阅读全文
posted @ 2023-06-13 10:35 ty1539
阅读(37)
评论(0)
推荐(0)
2023年5月22日
python 小技巧, 如何为元祖中的每个元素命名,提升可读性
摘要: ## 如何为元祖中的每个元素命名,提升可读性  ## 方法1, index命名: 
评论(0)
推荐(0)
2023年5月9日
python 小技巧, 如何找到多个字典中的公共键(key)
摘要:  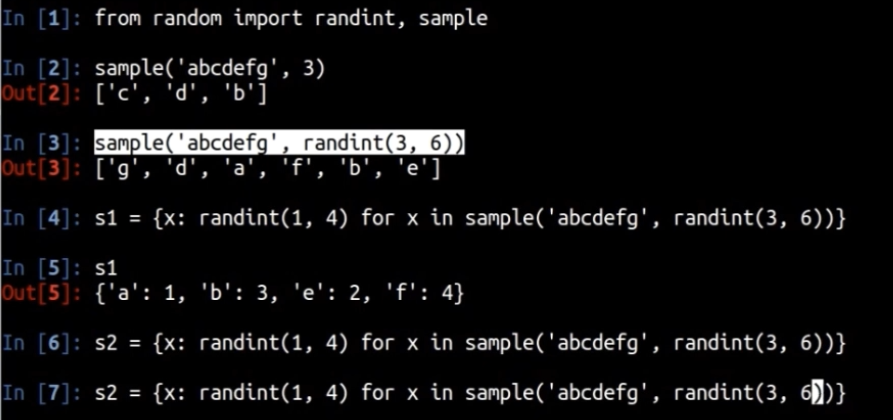 
评论(0)
推荐(0)
python 小技巧, 如何根据字典中的值的大小,对字典中的项排序
摘要: ## 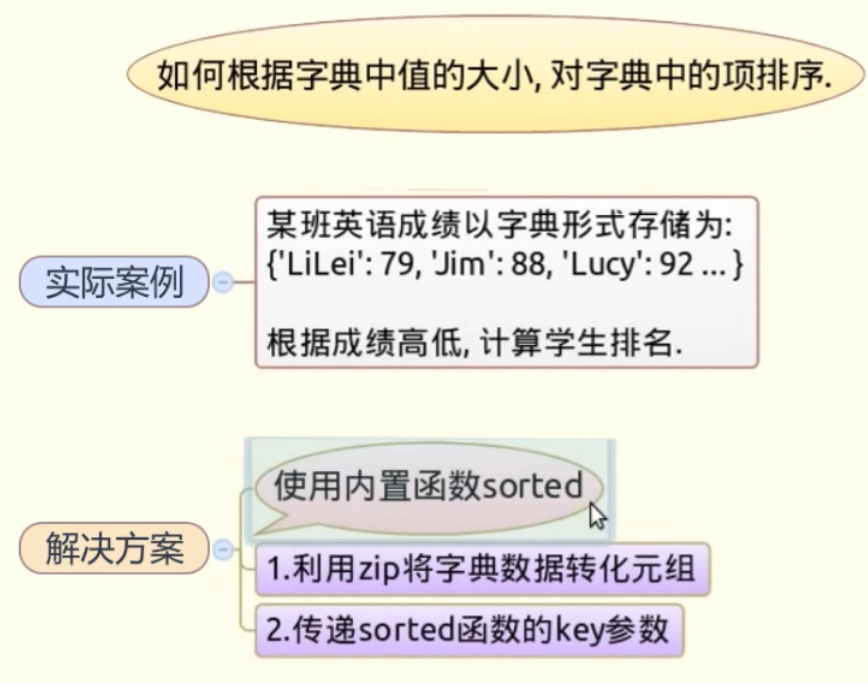 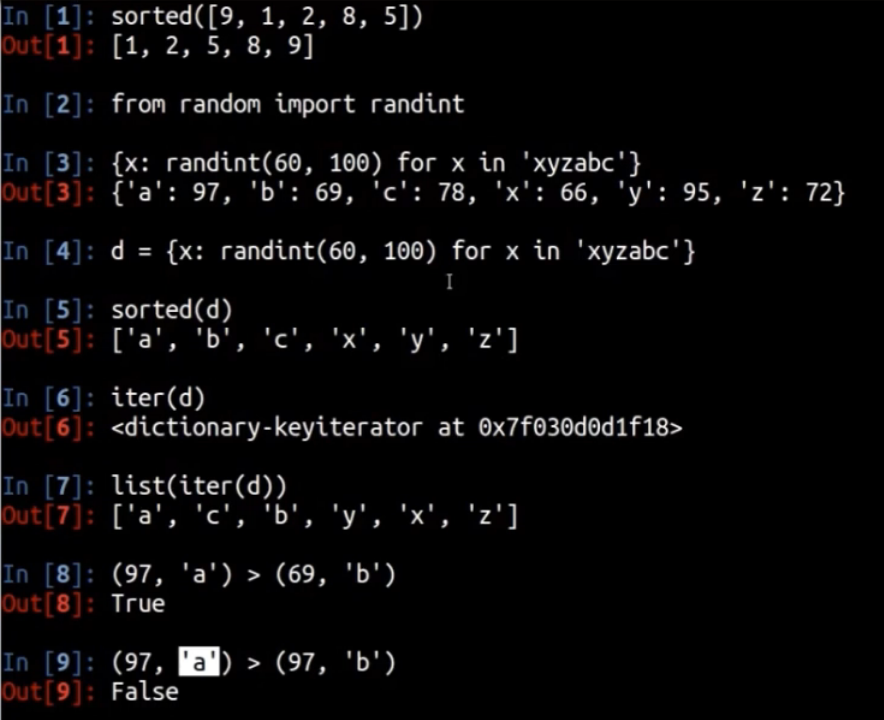 
评论(0)
推荐(0)
python 小技巧, 如何统计序列中元素出现的频度
摘要: dict.fromkeys(data,0) 默认字典,把data里面的值作为key,赋值给0 Counter对象的most_common(3)取出出现频率最高的3个 读取文件, 用re.split("\W+",txt)非字符进行分割,再用Counter进行处理
阅读全文
posted @ 2023-05-09 00:31 ty1539
阅读(47)
评论(0)
推荐(0)
下一页
公告
 浙公网安备 33010602011771号
浙公网安备 33010602011771号