selenium上手
功能自动化
前提
- 自动化的主要目的并不是为了找Bug,是为了证明功能可用
- 不只是所有的功能都可以自动化,如UI
- 并不是所有的项目都可以使用自动化,如selenium只能使用bs项目,小项目不适合使用自动化
- 自动化在手动测试后
- 在软件版本还没有稳定的情况下,千万不要开展自动化
自动化的局限性
- 定制性项目
- 周期很短的项目
- 人体感官与易用性测试
- 涉及物理交互
- 发现缺陷少
- 维护成本高
- 可能会制约软件开发
- 不能灵活处理意外
selenium
selenium: B/S软件功能自动化
IDE: 录制、回放【不会自动打开浏览器】
webdriver: 支持多语言的类库方法
Python 3.4 selenium:2.53.6 firefox: 46
IDE
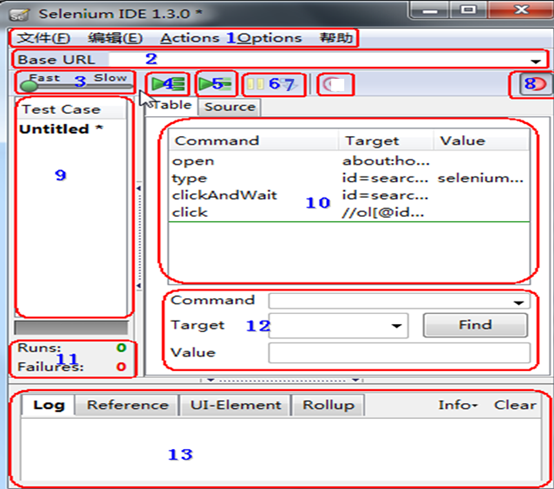
1、 文件:创建、打开和保存测试案例和测试案例集。
编辑:复制、粘贴、删除、撤销和选择测试案例中的所有命令。
Options :用于设置seleniunm IDE。
2、用来填写被测网站的地址。
3、速度控制:控制案例的运行速度。
4、运行所有:运行一个测试案例集中的所有案例。
5、运行:运行当前选定的测试案例。
6、暂停/恢复:暂停和恢复测试案例执行。
7、单步:可以运行一个案例中的一行命令。
8、录制:点击之后,开始记录你对浏览器的操作。
9、案例集列表。
10、测试脚本;table标签:用表格形式展现命令及参数。source标签:用原始方式展现,默认是HTML语言格式,也可以用其他语言展示。
11、查看脚本运行通过/失败的个数。
12、当选中前命令对应参数。
13、日志/参考/UI元素/Rollup
webdriver
定位方式
id:html标签的id属性值
name:html标签的name属性值
CSS:css样式选择器 # id选择器
xpath:通过标签在html页面源码路径
绝对路径:/html/body/table/tr/td[2]/input
相对路径:.//input[@aa="abc"]
.//标签名[@属性名="属性值"]
.//*[@aa="abc"]
.//*[@属性名="属性值"]
link:通过超链接标签内容
identifier:优先id的,如果没有再去找name的
js:dom=document.getElementById(“password”)
class:class=
dd=webdriver.Firefox() 打开浏览器
dd.get("url") :打开url对应页面
webdriver:
dd.find_element_by_id("html标签的id属性值")
dd.find_element_by_name("html标签的name属性值")
dd.find_element_by_css_selector("html标签的css样式选择器")
dd.find_element_by_xpath("html标签的xpath路径")
dd.find_element_by_link_text("超链接标签内容")
dd.find_element_by_tag_name("html标签名")
dd.find_element_by_class_name("html的class属性值")
操作:
文本框,密码框,文本域:
清空:dd.find_element_by_....(....).clear()
输入:dd.find_element_by_....(....).send_keys("输入内容")
单选按钮,复选框,超链接,按钮:
点击:dd.find_element_by_....(....).click()
下拉框:
选择:
Select(定位到的一个具体的下拉框).select_by_value("option的value属性值")
切焦点到frame/iframe:
dd.switch_to_frame("frame的id/name属性值")
dd.switch_to.frame("frame的id/name属性值")
当页面有刷新或者有跳转,需要加等待时间
time.sleep(数字秒)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号