
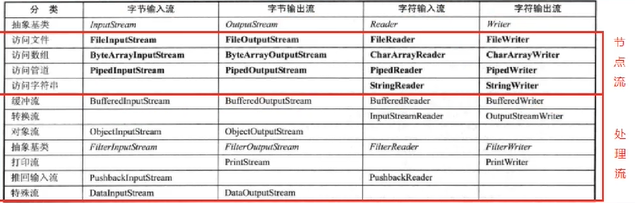
节点流和处理流(BufferedReader和BufferedWriter,BufferedInputStream和BufferedOutputStream,ObjectlnputStream和objectOutputStream)
一、基本介绍:
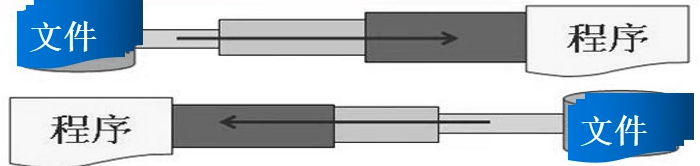
1、节点流可以从一个特定的数据源读写数据,如FileReader、 FileWriter
如图:字节流是直接对数据源(文件,数组之类存放数据的地方)进行操作

2.处理流(也叫包装流)是"连接"在已存在的流(节 点流或处理流)之上,为程序提供
更为强大的读写功能,也更加灵活,如BufferedReader、BufferedWriter
3、节点流和处理流的区别和联系:
1).节点流是底层流/低级流,直接跟数据源相接。
2).处理流(包装流)包装节点流,既可以消除不同节点流的实现差异,也可以提供更方便的方法
来完成输入输出。
3).处理流(也叫包装流)对节点流进行包装,使用了修饰器设计模式,不会直接与数据
源相连[模拟修饰器设计模式]
●处理流的功能主要体现在以下两个方面:
1.性能的提高:主要以增加缓冲的方式来提高输入输出的效率。
2.操作的便捷:处理流可能提供了-系列便捷的方法来一次输入输出大批量的数据, 使
用更加灵活方便
二、处理流-BufferedReader和BufferedWriter的使用
简介:BufferedReader和BufferedWriter属于字符流,是按照字符来读取数据的
关闭时,只需要关闭外层流即可[可以调试看源码:在底层会用close()关闭Reader]
注意:BufferedReader和BufferedWriter是安装字符操作,不能操作二进制文件
常见的二进制文件【声音,视频,doc,pdf,图片】
处理流的两个实例:
BufferedReader
import java.io.BufferedReader; import java.io.FileReader; import java.io.IOException; public class BufferReader_ { public static void main(String[] args) throws IOException { //创建一个文件对象 String filePath1 = "C:\\Users\\wenman\\Desktop\\test\\news3.txt"; String line = null; //创建一个 BufferedReader的对象,并包装一个FileReader在里面 BufferedReader bufferedReader = new BufferedReader(new FileReader(filePath1)); while ((line = bufferedReader.readLine()) != null) {//readline表示读取一行的字符串 System.out.println(line); } //关闭BufferedReader处理流,只需要关闭外层即可,内层的FileReader会在底层自动关闭 bufferedReader.close(); } }
BufferedWriter
import java.io.BufferedWriter; import java.io.FileWriter; import java.io.IOException; public class BufferWeriter_ { public static void main(String[] args) throws IOException { //定义文件路径 String filePath1 = "C:\\Users\\wenman\\Desktop\\test\\news1.txt"; //创建一个BufferWriter对象 // BufferedWriter bufferedWriter = new BufferedWriter(new FileWriter(filePath1));//直接覆盖原来内容 BufferedWriter bufferedWriter = new BufferedWriter(new FileWriter(filePath1,true));//在原来的内容上添加,添加到文章内容之后 bufferedWriter.write("这里水太深你把握不住2.0。"); bufferedWriter.newLine();//插入一个换行符 bufferedWriter.write("这里水太深你把握不住3.0。"); bufferedWriter.close(); } }
三、处理流:BufferedInputStream和BufferedOutputStream
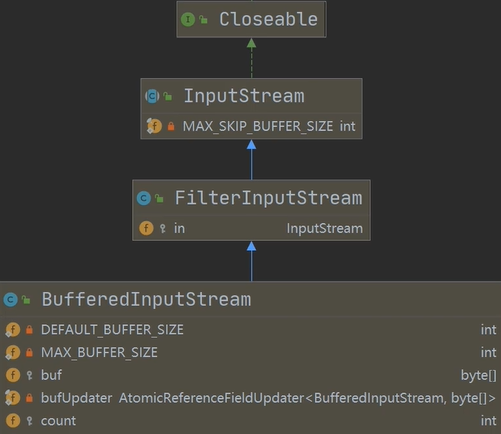
1、BufferedInputStream:BufferedInputStream是字节流在创建BufferedInputStream
时,会创建一个内部缓冲区数组.
继承实现图
2、BufferedOutputStream:BufferedOutputStream是字节流,实现缓冲的输出流,可以将多个字节写入底层输出流中,而不必对每次字节写入调用底层系统
继承实现图

使用BufferedInputStream和BufferedOutputStream2完成二进制文件的拷贝:
import java.io.*; public class BufferedCopy { public static void main(String[] args) throws IOException { //复制的源地址和目的地址 String srcPath = "C:\\Users\\wenman\\Desktop\\imageTest\\test33.jpg"; String destPath = "C:\\Users\\wenman\\Desktop\\imageTest\\test11.jpg"; //定义一个用于接收文件的byte[]数组和记录数据大小的整数 byte[] bytes = new byte[100]; int dataLine = 0; //创建Buffered BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream(srcPath)); BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(new FileOutputStream(destPath)); while ((dataLine=bufferedInputStream.read(bytes))!= -1){ bufferedOutputStream.write(bytes, 0, dataLine); } bufferedInputStream.close(); bufferedOutputStream.close(); } }
四。对象流-ObjectlnputStream和objectOutputStream
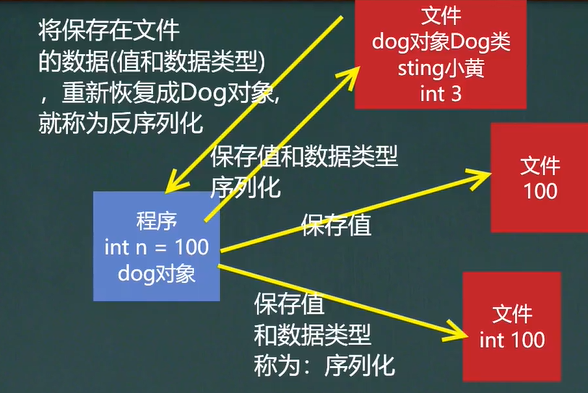
➢序列化和反序列化
1.序列化就是在保存数据时,保存数据的值和数据类型
2.反序列化就是在恢复数据时,恢复数据的值和数据类型
3.需要让某个对象支持序列化机制,则必须让其类是可序列化的,为了让某个类是可序列化的,该
类必须实现如下两个接口之- -:
➢Serializable//这是一个标记接口,没有方法
➢Externalizable //该接口有方法需要实现,因此我们一般实现上面的Serializable接口
序列化反序列化类比图如下:
1、ObjectlnputStream和objectOutputStream基本介绍:
1).功能:提供了对基本类型或对象类型的序列化和反序列化的方法
2). ObjectOutputStream 提供序列化功能
3). ObjectlnputStream 提供反序列化功能
ObjectlnputStream的实现继承图:

objectOutputStream的实现继承图:

代码实例:objectOutputStream
import java.io.FileOutputStream; import java.io.IOException; import java.io.ObjectOutputStream; public class ObjectOutput { public static void main(String[] args) throws IOException { //定义输出的文件地址 String filePath1 = "C:\\Users\\wenman\\Desktop\\test\\data.dat"; //定义一个ObjectOutputStream对象,并包装FileOutputStream的类 ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream(filePath1)); objectOutputStream.writeInt(100); objectOutputStream.writeDouble(12.5); objectOutputStream.writeChar('A'); objectOutputStream.writeObject(new Dog("zhangsan", 20)); objectOutputStream.close(); } }
代码实例:ObjectlnputStream
import java.io.FileInputStream; import java.io.IOException; import java.io.ObjectInputStream; public class ObjectInput { public static void main(String[] args) throws IOException, ClassNotFoundException { //文件路径 String filePath1 = "C:\\Users\\wenman\\Desktop\\test\\data.dat"; ObjectInputStream inputStream = new ObjectInputStream(new FileInputStream(filePath1)); //读取文件中存在的内容(内容读取时,应当按照存放时的顺序读取文件) System.out.println(inputStream.readInt()); System.out.println(inputStream.readDouble()); System.out.println(inputStream.readChar()); //其中,Object的类型,应该是在整个包中可以访问的,因为数据在存进文件时,类型所在的包也是保存进文件的 //所以在反序列化的时候,又会按照所记录的包的类型去加载,包找不到就会加载错误,反序列化失败 Object dog = inputStream.readObject(); System.out.println(dog); // Dog dog1 = (Dog) dog; // System.out.println(dog1.getName() + "----" + dog1.getAge()); inputStream.close(); } }
2、注意事项和细节说明
1)读写顺序要一致
2)要求序列化或反序列化对象,需要实现 Serializable
3)序列化的类中建议添加SerialVersionUID,为了提高版本的兼容性
4)序列化对象时,默认将里面所有属性都进行序列化,但除了static(静态)或transient(临时)修饰的成员5)序列化对象时,要求里面属性的类型也需要实现序列化接口
6)序列化具备可继承性,也就是如果某类已经实现了序列化,则它的所有子类也已经默认实现了序列化
标准输入和标准输出的编译类型和运行类型:
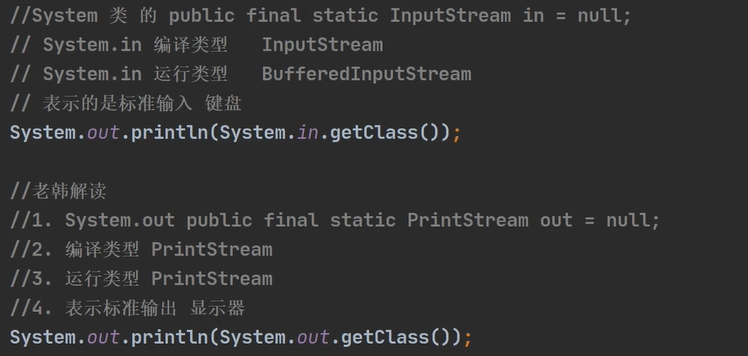
五、转换流-lnputStreamReader和 OutputStreamWriter
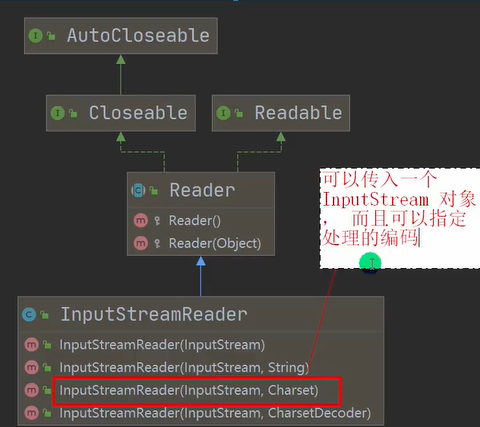
1. InputStreamReader:Reader的子类,可以将InputStream(字节流)包装成Reader(字符流)
指定文件读取时的编码:继承实现图
2.OutputStreamWriter:Writer的子类,实现将OutputStream(字节流)
指定文件读取时的编码:继承实现图
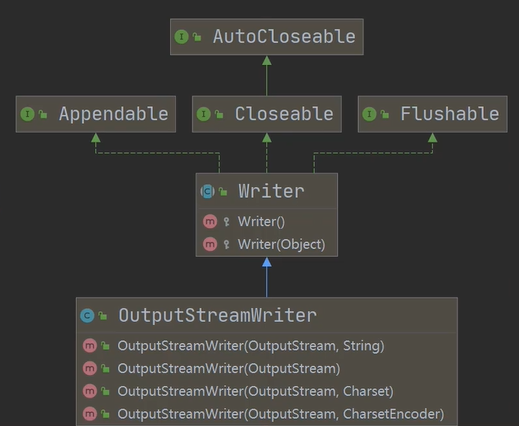
包装成Writer(字符流)
3.当处理纯文本数据时,如果使用字符流效率更高,并且可以有效解决中文
问题,所以建议将字节流转换成字符流
4.可以在使用时指定编码格式(比如utf-8, gbk , gb2312, ISO8859-1等)
引出问题:当文件中的编码和读取的编码时出现乱码问题:
@Test public void Read1() throws IOException { String filePath1 = "C:\\Users\\wenman\\Desktop\\test\\news1.txt"; byte[] bytes = new byte[100]; int dataLine = 0; FileInputStream fileInputStream = new FileInputStream(filePath1); while ((dataLine = fileInputStream.read(bytes)) != -1){ System.out.println(new String(bytes,0,dataLine)); } fileInputStream.close(); }
原文:这里水太深你把握不住。这里水太深你把握不住2.0。这里水太深你把握不住2.0。
这里水太深你把握不住3.0。
读取后的内容:

解决问题:
import org.junit.jupiter.api.Test; import java.io.*; public class BufferedReaderUtf { public static void main(String[] args) { String filePath1 = "C:\\Users\\wenman\\Desktop\\test\\news1.txt"; } @Test public void Read1() throws IOException { String filePath1 = "C:\\Users\\wenman\\Desktop\\test\\news1.txt"; byte[] bytes = new byte[100]; int dataLine = 0; FileInputStream fileInputStream = new FileInputStream(filePath1); while ((dataLine = fileInputStream.read(bytes)) != -1) { System.out.println(new String(bytes, 0, dataLine)); } fileInputStream.close(); } @Test public void Read2() throws IOException { //文件路径 String filePath1 = "C:\\Users\\wenman\\Desktop\\test\\news1.txt"; //给字节流设置一个读取的编码格式(在字节流中定义了一个新的流对象),指定编码gbk InputStreamReader streamReader = new InputStreamReader(new FileInputStream(filePath1), "gbk"); //用一个处理流包装字节流 BufferedReader bufferedReader = new BufferedReader(streamReader);
//可以将上述两行转换为一行减少冗余
// BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(new FileInputStream(filePath1)));
String data = null; //获取文件内容输出 while ((data = bufferedReader.readLine()) != null) { System.out.println(data); } bufferedReader.close();//关闭处理流,只需要关闭外层的,内层的会自动关闭 } }
结果:

OutputStreamWriter的使用:
import java.io.*; public class BufferedWriterUtf { public static void main(String[] args) throws IOException { //文件路径 String filePath1 = "C:\\Users\\wenman\\Desktop\\test\\news2.txt"; String test = "这个世界上有很多"; //将一个输出流转换为一个字节转换流,用一个处理流包装起来,设置编码方式为gbk,表示该文件内容为gbk BufferedWriter bufferedWriter = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(filePath1),"gbk")); //输出字符到指定文件 bufferedWriter.write(test); //输出一个换行符 bufferedWriter.newLine(); //关闭外层处理流,内层字节流会自己关闭 bufferedWriter.close(); } }
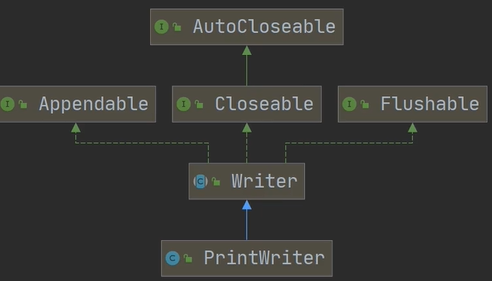
六、打印流:-PrintStream和PrintWriter:打印流只有输出流,没有输入流
PrintStream的继承实现图

PrintWriter的实现继承图
代码实例:
import org.junit.jupiter.api.Test; import java.io.FileWriter; import java.io.IOException; import java.io.PrintStream; import java.io.PrintWriter; public class Print { @Test public void printStream_() throws IOException { String filePath1 = "C:\\Users\\wenman\\Desktop\\test\\note.txt"; PrintStream out = System.out; //在默认情况下就输出到控制台 out.println("hello"); //因为println在底层使用的是write,所有可以直接使用Write输出 out.write("hello".getBytes()); System.setOut(new PrintStream(filePath1)); System.out.println("hello,little"); } @Test public void printWrite_() throws IOException { String filePath1 = "C:\\Users\\wenman\\Desktop\\test\\note.txt"; PrintWriter printWriter = new PrintWriter(new FileWriter(filePath1));//输出到文件 // PrintWriter printWriter = new PrintWriter(System.out);//输出到控制台 printWriter.print("ghellouhadkuah"); printWriter.close(); } }
七、Properties类
基本介绍:
1)专门用于读写配置文件的集合类
配置文件的格式:
键=值
键=值
2)注意:键值对不需要有空格,值不需要用引号一起来。默认类型是String
3) Properties的常见方法
ldad: 加载配置文件的键值对到Properties对象·
list:将数据显示到指定设备
getProperty(key):根据键获取值
setProperty(key,value):设置键值对到Properties对象
store:将Properties中的键值对存储到配置文件,在idea中,保存信息到配置文件,如果含有中文,会存储为unicode码
http://tool.chinaz.com/tools/unicode.aspx unicode码查询工具

 浙公网安备 33010602011771号
浙公网安备 33010602011771号