

SQL Server索引简介:SQL Server索引级别1
作者David Durant,2014/11/05(第一版:2011/02/17)
原文链接:
http://www.sqlservercentral.com/articles/Stairway+Series/72284/
该系列
本文是“Stairway系列:SQL Server索引的阶梯”的一部分
索引是数据库设计的基础,并告诉开发人员使用数据库关于设计者的意图。不幸的是,当性能问题出现时,索引往往被添加为事后考虑。这里最后是一个简单的系列文章,应该使他们快速地使任何数据库专业人员“快速”
第一级引入SQL Server索引:使SQL Server能够在最短的时间内找到和/或修改请求的数据的数据库对象,使用最少的系统资源来实现最高性能。良好的索引也将允许SQL Server实现最大的并发性,以便由一个用户运行的查询对其他人运行的查询影响不大。最后,通过在创建唯一索引时保证键值的唯一性,索引提供了强制执行数据完整性的有效方式。这个级别是一个介绍;它涵盖了概念和用法,但将物理细节留在较晚的级别。
对于数据库开发人员来说,深入理解索引是非常重要的:出于某种原因,数据库开发人员最重要的是:当SQL Server的请求从客户端到达时,SQL Server只有两种可能的方式来访问请求的行:
l ·它可以扫描包含数据的表中的每一行,从第一行开始并继续到最后一行,检查每一行,看它是否符合请求标准。
l ·或者,如果有有用的索引可用,则可以使用索引来查找所请求的数据。
第一个选项总是可用于SQL Server。第二个选项仅在您指示SQL Server创建有益的索引时才可用,但可以显着提高性能,我们将在后面的层次中进行说明。
由于索引具有与它们相关的开销(它们占用空间并且必须与表保持同步),因此SQL Server不需要它们。可以有一个没有索引的数据库。它可能执行得很差,肯定会有数据完整性问题,但SQL Server将允许它。
但是,这不是我们想要的。我们都希望数据库性能良好,具有数据完整性,同时将索引开销降到最低。这个水平将使我们朝着这个目标前进。
示例数据库
在整个StairWay中,我们将用例子来说明关键的概念。这些示例基于Microsoft AdventureWorks示例数据库。我们专注于销售订单功能。五张表将给我们交易和非交易数据的良好组合; Customer,SalesPerson,Product,SalesOrderHeader和SalesOrderDetail。为了保持重点,我们使用列的一个子集。
AdventureWorks已经正常化了,所以销售人员信息被分成三个表格。营业员,员工及联系方式。对于一些例子,我们将把它们当作一个表格。图1.1显示了我们将要使用的一整套表格以及它们之间的关系。
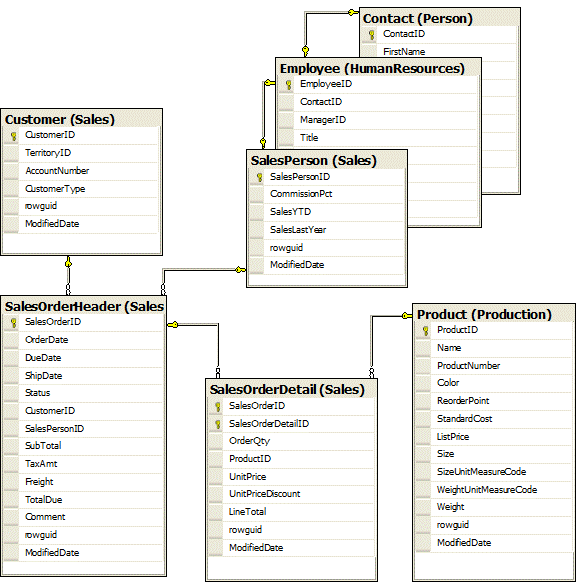
图1.1:将在此阶梯中使用的AdventureWorks表
注意:
该楼梯级别显示的所有TSQL代码可以与文章一起下载(请参阅本文底部的链接)
什么是索引?
我们以一个简短的故事开始我们的索引研究,这个故事使用了一个陈旧的,但已经证实的技术,在我们介绍索引的基本概念时,我们将在本文中引用这个故事。
你离开你的房子跑几个差事。当你回来的时候,你会发现女儿的垒球教练正在等你的消息。特蕾西,丽贝卡和艾米中的三个女孩已经失去了球队的帽子。你可以请运动产品商店摆动,并为女孩买帽子。他们的父母将在下一场比赛中报销你。 你知道女孩,你知道他们的父母。但你不知道他们的帽子大小。你们镇的某个地方有三个住宅,每个住宅都有你需要的信息。没问题,你只需打电话给父母,并获得帽子大小。您接触到您的电话,然后到达索引 - 电话号码簿的白页。 你需要的第一个住所是海伦·迈耶(Helen Meyer)。估计“迈尔”将位于人口中间附近,你跳到白页的中间,只是发现你在标题为“Kline-Koerber”的页面上。你向前跳一小步,到达“Nagle-Nyeong”页面。一个更小的跳跃,让你在“马尔多纳多 - 纳格尔”页面。意识到你现在在正确的页面,你扫描页面,直到你到达“迈尔,海伦”线,并获得电话号码。使用电话号码,您可以到达Meyer住宅并获取所需的信息。 你再重复这个过程两次,到另外两个住所,再获得两个帽子尺寸。
您刚刚使用了一个索引,并且已经以与SQL Server使用索引相同的方式使用它;因为白页和SQL Server索引之间有很大的相似之处和一些区别。
实际上,刚刚使用的索引代表SQL Server支持的两种SQL Server索引中的一种:聚簇和非聚簇。白页最能代表非聚集索引的概念。因此,在这个层面上,我们引入非聚集索引。随后的级别将引入聚集索引并深入钻取这两种类型。
非聚集索引
白页类似于非聚集索引,因为它们不是数据本身的组织;而是一种机制或地图来帮助您访问这些数据。数据本身就是我们需要联系的实际人员。电话公司没有按照有意义的顺序安排小镇的住宅,把房子从一个地方搬到另一个地方,这样同一个垒球队的所有女孩就住在一起,房子也没有居民的姓氏。相反,它会给你一本书,每个住所都有一个入口。这些条目按照白页的搜索键进行排序;姓氏,名字,中间首字母和街道地址。每个条目都包含搜索关键字和数据,使您能够进入住所;电话号码。
像白名单中的条目一样,SQL Server非聚簇索引中的每个条目都由两部分组成:
l ·搜索关键字,例如姓氏 - 名字 - 中间首字母。 。在SQL Server术语中,这是索引键。
l ·书签与电话号码具有相同的用途,允许SQL Server直接导航到与此索引条目对应的表中的行。
另外,SQL Server非聚集索引条目具有一些仅供内部使用的头信息,并可能包含一些可选信息。这两个都将在后面的层面进行讨论。在这个时候,对于非集群索引的理解也不重要。
像白页一样,在搜索关键字序列中维护一个SQL Server索引,这样任何特定的条目都可以通过一组小的“跳转”来访问。给定搜索键,SQL Server可以快速到达该键的索引条目。与白页不同,SQL Server索引是动态的。也就是说,每次添加,删除行或者修改了搜索关键字列值时,SQL Server都会更新索引。
正如白页中的条目顺序与镇内住宅的地理顺序不一样,非聚集索引中的条目顺序与表中的行顺序不同。索引中的第一个条目可能是表中最后一行的索引,索引中的第二个条目可能是表中第一行的第二个条目。如果事实与索引不同,其索引总是有意义的;一个表的行可以完全不确定。
在创建索引时,SQL Server会在基础表中为每行生成并维护索引中的一个条目(当我们覆盖已过滤的索引时,将在稍后的级别中遇到此常规规则的一个例外)。您可以在表上创建多个非聚集索引,但是不能有包含来自多个表的数据的索引。
而最大的区别是:SQL Server不能使用电话。它必须使用索引条目的书签部分中的信息导航到表的相应行。当SQL Server需要任何在数据行中但没有在相应索引条目中的信息时,这是必要的,例如Tracy Meyer的垒球帽大小。因此,为了更好的比喻,白页的条目包含一组GPS坐标而不是电话号码。然后,您使用GPS坐标导航到由白页条目表示的住宅。
创建并受益于非聚集索引
我们通过两次查询我们的示例数据库来结束这个级别。确保使用SQL Server 2005专用的AdventureWorks版本,SQL Server 2008可以使用该版本。AdventureWorks2008数据库具有不同的表结构,下面的查询将失败。我们将每次运行相同的查询;但是第一次执行会在我们创建索引之前发生,第二次执行会在创建索引之后发生。每一次,SQL Server都会告诉我们在检索请求的信息方面已经做了多少工作。我们将在我们的Contact表中找到“Helen Meyer”行(她的行位于表格中间附近)。最初,该表在“名字”列或“姓氏”列中将不具有索引。为确保您可以多次运行该示例,请确保我们将在第三批生成的索引不存在,方法是运行以下代码:
IF EXISTS (SELECT * FROM sys.indexesWHERE OBJECT_ID = OBJECT_ID('Person.Contact')
AND name = 'FullName')DROP INDEX Person.Contact.FullName;
Listing 1.1 - Ensuring the index does not exist
Our task will require four SQL command batches.
The first command batch:
SET STATISTICS io ON
SET STATISTICS time ONGO
清单1.2 - 打开统计信息
上面的批处理通知SQL Server我们希望我们的查询作为输出的一部分返回性能信息。
第二批命令:
SELECT *
FROM Person.Contact
WHERE FirstName = 'Helen'
AND LastName = 'Meyer';GO
清单1.3 - 检索一些数据
这第二批检索“海伦迈耶”行:
584 Helen Meyer helen2@adventure-works.com 0-519-555-0112
另外还有以下性能信息:
Table 'Contact'. Scan count 1, logical reads 569. SQL Server Execution Times: CPU time = 3 ms.
这个输出告诉我们,我们的请求执行了569个逻辑IO,并且需要大约3毫秒的处理器时间来完成。 处理器时间的值可能不同。
第三批命令:
CREATE NONCLUSTERED INDEX FullName
ON Person.Contact
( LastName, FirstName );GO
清单1.4 - 创建一个非聚集索引
此批处理在联系人表的名字和姓氏列上创建一个非聚集索引。 一个复合索引是一个索引,它有多个列确定索引行序列。
第四批命令:
SELECT *
FROM Person.Contact
WHERE FirstName = 'Helen'
AND LastName = 'Meyer';GO
清单1.3(再次)
这最后一批是我们原来的SELECT语句的重新执行。 我们得到和以前一样的返回行; 但是这次的表现统计是不一样的
Table 'Contact'. Scan count 1, logical reads 4. SQL Server Execution Times: CPU time = 0 ms.
这个输出告诉我们,我们的请求只需要4个逻辑IO;并且需要非常少量的处理器时间来检索“海伦迈耶”行。
结论
创建精心挑选的索引可以大大提高数据库性能。在下一个层面,我们将开始考察索引的物理结构。我们将研究为什么这个非聚集索引对这个查询是如此有利,为什么这可能不总是如此。未来的水平将涵盖其他类型的指数,指数的额外收益,与指数相关的成本,监测和维护您的指数,以及最佳做法;所有的目标都是为您提供必要的知识,为您自己的数据库中的表创建最佳的索引方案。
可下载的代码
l Level1 - IntroToIndexes_Durant_Code.sql
l LevelLevel 1 - MillionRowContactTable.sql
资源:
Level 1 - IntroToIndexes_Durant_Code.sql | 1级 - MillionRowContactTable.sql
本文是SQL Server索引阶梯的一部分
