docker compose和docker swarm 和 docker stack
docker compose:单机部署,使用docker compose编排多个服务
docker swarm:多机部署,实现对单个服务的简单部署(通过dockerfile)
docker stack :实现集群环境下多服务编排。(通过compose.yml)
狂神说docker(最全笔记)_狂神说docker笔记-CSDN博客













docker-compose教程(安装,使用, 快速入门)-CSDN博客
docker-compose文件结构
docker-compose.yml:
version: "3" services: redis: image: redis:alpine ports: - "6379" networks: - frontend deploy: replicas: 2 update_config: parallelism: 2 delay: 10s restart_policy: condition: on-failure db: image: postgres:9.4 volumes: - db-data:/var/lib/postgresql/data networks: - backend deploy: placement: constraints: [node.role == manager] vote: image: dockersamples/examplevotingapp_vote:before ports: - 5000:80 networks: - frontend depends_on: - redis deploy: replicas: 2 update_config: parallelism: 2 restart_policy: condition: on-failure result: image: dockersamples/examplevotingapp_result:before ports: - 5001:80 networks: - backend depends_on: - db deploy: replicas: 1 update_config: parallelism: 2 delay: 10s restart_policy: condition: on-failure worker: image: dockersamples/examplevotingapp_worker networks: - frontend - backend deploy: mode: replicated replicas: 1 labels: [APP=VOTING] restart_policy: condition: on-failure delay: 10s max_attempts: 3 window: 120s placement: constraints: [node.role == manager] visualizer: image: dockersamples/visualizer:stable ports: - "8080:8080" stop_grace_period: 1m30s volumes: - "/var/run/docker.sock:/var/run/docker.sock" deploy: placement: constraints: [node.role == manager] networks: frontend: backend: volumes: db-data:







Docker三剑客之docker-swarm
Docker三剑客之docker-swarm - 会飞的猪的文章 - 知乎 https://zhuanlan.zhihu.com/p/93459309
简介
Swarm是Docker官方提供的一款集群管理工具,其主要作用是把若干台Docker主机抽象为一个整体,并且通过一个入口统一管理这些Docker主机上的各种Docker资源。Swarm和Kubernetes比较类似,但是更加轻,具有的功能也较kubernetes更少一些。
swarm集群提供给用户管理集群内所有容器的操作接口与使用一台Docker主机基本相同。
Swarm一些概念说明
1、节点
运行 Docker 的主机可以主动初始化一个 Swarm 集群或者加入一个已存在的 Swarm 集群,这样这个运行 Docker 的主机就成为一个 Swarm 集群的节点 (node) 。
节点分为管理 (manager) 节点和工作 (worker) 节点。
管理节点用于 Swarm 集群的管理,docker swarm 命令基本只能在管理节点执行(节点退出集群命令 docker swarm leave 可以在工作节点执行)。一个 Swarm 集群可以有多个管理节点,但只有一个管理节点可以成为 leader,leader 通过 raft 协议实现。
工作节点是任务执行节点,管理节点将服务 (service) 下发至工作节点执行。管理节点默认也作为工作节点。你也可以通过配置让服务只运行在管理节点。
来自 Docker 官网的这张图片形象的展示了集群中管理节点与工作节点的关系。
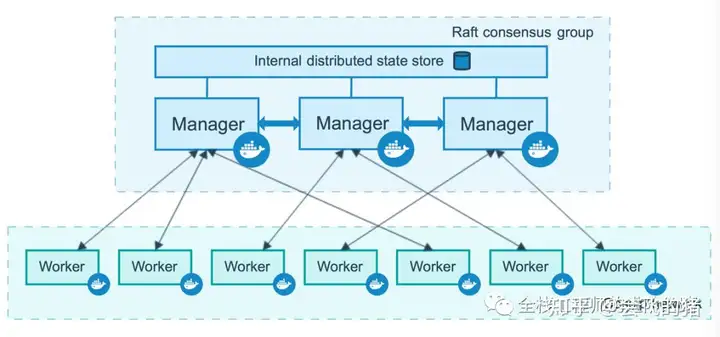
2、服务和任务
任务 (Task)是 Swarm 中的最小的调度单位,目前来说就是一个单一的容器。
服务 (Services) 是指一组任务的集合,服务定义了任务的属性。服务有两种模式:
replicated services 按照一定规则在各个工作节点上运行指定个数的任务。
global services 每个工作节点上运行一个任务
两种模式通过 docker service create 的 --mode 参数指定。
来自 Docker 官网的这张图片形象的展示了容器、任务、服务的关系。
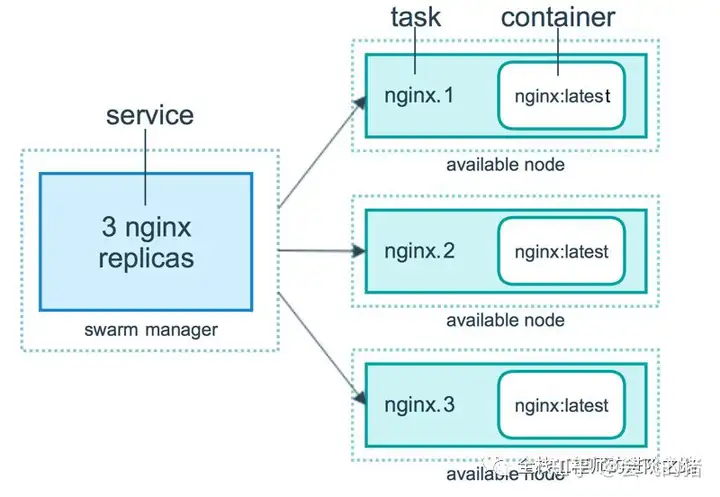
Swarm 调度策略
Swarm在scheduler节点(leader 节点)运行容器的时候,会根据指定的策略来计算最适合运行容器的节点,目前支持的策略有:spread, binpack, random.
1)Random
顾名思义,就是随机选择一个 Node 来运行容器,一般用作调试用,spread 和 binpack 策略会根据各个节点的可用的 CPU, RAM 以及正在运行的容器的数量来计算应该运行容器的节点。
2)Spread
在同等条件下,Spread 策略会选择运行容器最少的那台节点来运行新的容器,binpack 策略会选择运行容器最集中的那台机器来运行新的节点。使用 Spread 策略会使得容器会均衡的分布在集群中的各个节点上运行,一旦一个节点挂掉了只会损失少部分的容器。
3)Binpack
Binpack 策略最大化的避免容器碎片化,就是说 binpack 策略尽可能的把还未使用的节点留给需要更大空间的容器运行,尽可能的把容器运行在一个节点上面。
Swarm命令行说明
docker swarm:集群管理init #初始化集群join #将节点加入集群join-token #管理加入令牌leave #从集群中删除某个节点,强制删除加参数--forceupdate #更新集群unlock #解锁集群docker node:节点管理,demote #将集群中一个或多个节点降级inspect #显示一个或多个节点的详细信息ls #列出集群中的节点promote #将一个或多个节点提升为管理节点rm #从集群中删除停止的节点,--force强制删除参数ps #列出一个或多个节点上运行的任务update #更新节点docker service:服务管理,create #创建一个新的服务inspect #列出一个或多个服务的详细信息ps #列出一个或多个服务中的任务信息ls #列出服务rm #删除一个或多个服务scale #扩展一个或多个服务update #更新服务
安装布署swarm集群服务
manager:192.168.124.129
node:192.168.124.132
1、修改主机名,配置hosts文件
[root@manager ~]# cat >>/etc/hosts<<EOF192.168.124.129 manager192.168.124.132 node1EOF[root@manager ~]# tail -3/etc/hosts192.168.124.129 manager192.168.124.132 node1#node1 node2配置同上一致即可
2、配置docker
编辑docker文件:/usr/lib/systemd/system/docker.service
vim /usr/lib/systemd/system/docker.service
修改ExecStart行为下面内容
ExecStart=/usr/bin/dockerd -H tcp://0.0.0.0:2375 -H unix://var/run/docker.sock \
重新加载docker配置
systemctl daemon-reload // 1,加载docker守护线程systemctl restart docker // 2,重启docker
所有节点加上上面标记的部分,开启2375端口
3、所有节点下载swarm镜像文件
$ docker pull swarm
4、创建swarm并初始化
$ docker swarm init --advertise-addr 192.168.124.129Swarm initialized: current node (4c70fdpk3ip083rg7nnuk5stw)is now a manager.To add a worker to this swarm, run the following command:docker swarm join --token SWMTKN-1-5jubbodkfxlp96pg2w9sihqdvtruhkdje3bls1nb9ujiig0t3n-1d9l7t4bssnglbuemx9v06r3x192.168.124.129:2377To add a manager to this swarm, run 'docker swarm join-token manager'and follow the instructions.#执行上面的命令后,当前的服务器就加入到swarm集群中,同时会产生一个唯一的token值,其它节点加入集群时需要用到这个token。#--advertise-addr 表示swarm集群中其它节点使用后面的IP地址与管理节点通讯,上面也提示了其它节点如何加入集群的命令。
5、将node1加入到集群中
在node1下执行
$ docker swarm join --token SWMTKN-1-5jubbodkfxlp96pg2w9sihqdvtruhkdje3bls1nb9ujiig0t3n-1d9l7t4bssnglbuemx9v06r3x192.168.124.129:2377This node joined a swarm as a worker.
6、管理节点查看集群节点状态
$ docker node lsID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION4c70fdpk3ip083rg7nnuk5stw* manager ReadyActiveLeader18.09.05viloj6u950gkilsl689aonyn node1 ReadyActiveReachable18.09.0#swarm集群中node的AVAILABILITY状态有两种:Active、drain。其中actice状态的节点可以接受管理节点的任务指派;drain状态的节点会结束任务,也不会接受管理节点的任务指派,节点处于下线状态。
7、Swarm 的Web管理
$ docker run -d -p 9000:9000-v /var/run/docker.sock:/var/run/docker.sock portainer/portainer
浏览器访问
docker-swarm布署服务
1、布署服务前创建于个用于集群内不同主机之间容器通信的网络
$ docker network create -d overlay dockernet5lhuzjkx36j40na59gmu400op
2、创建服务(nginx为例)
$docker service create --replicas 1--network dockernet --name nginx-cluster -p 80:80 nginxklpwtncehp0vkh0d1gqqvicf6#--replicas 指定副本数量$docker service lsID NAME MODE REPLICAS IMAGE PORTSklpwtncehp0v nginx-cluster replicated 1/1 nginx:latest *:80->80/tcp$ docker service ps nginx-clusterID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTSj1y2blg3pa7j nginx-cluster.1 nginx:latest manager RunningRunning53 seconds ago$ docker psCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES9a2e361f535b nginx:latest "nginx -g 'daemon of…"About a minute ago UpAbout a minute 80/tcp nginx-cluster.1.j1y2blg3pa7j9mtg54e2csr7f
3、在线动态扩容服务
docker service scale nginx-cluster=5nginx-cluster scaled to 5$ docker service lsID NAME MODE REPLICAS IMAGE PORTSklpwtncehp0v nginx-cluster replicated 5/5 nginx:latest *:80->80/tcp$ docker service ps nginx-clusterID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTSj1y2blg3pa7j nginx-cluster.1 nginx:latest manager RunningRunning3 minutes agoy5ib98y3rr5i nginx-cluster.2 nginx:latest node1 RunningRunning35 seconds agowpiydfv0j2w5 nginx-cluster.3 nginx:latest node1 RunningRunning35 seconds agoibl73haatpvc nginx-cluster.4 nginx:latest manager RunningRunning about a minute agoa6oa1h83ba3c nginx-cluster.5 nginx:latest node1 RunningRunning35 seconds ago#从输出结果可以看出已经将服务动态扩容至5个,也就是5个容器运行着相同的服务
4、节点故障
$ docker service ps nginx-clusterID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTSj1y2blg3pa7j nginx-cluster.1 nginx:latest manager RunningRunning45 minutes agougx002mtbfmp nginx-cluster.2 nginx:latest manager RunningRunning7 seconds agoy5ib98y3rr5i \_ nginx-cluster.2 nginx:latest node1 ShutdownShutdown11 seconds agoq1f5jhhx7kcy nginx-cluster.3 nginx:latest manager RunningRunning7 seconds agowpiydfv0j2w5 \_ nginx-cluster.3 nginx:latest node1 ShutdownShutdown11 seconds agoibl73haatpvc nginx-cluster.4 nginx:latest manager RunningRunning43 minutes agoa6f7zpclrpm4 nginx-cluster.5 nginx:latest manager RunningRunning7 seconds agoa6oa1h83ba3c \_ nginx-cluster.5 nginx:latest node1 ShutdownShutdown11 seconds ago#如果集群中节点发生故障,会从swarm集群中被T除,然后利用自身的负载均衡及调度功能,将服务调度到其它节点上
5、其它常用命令介绍
$ docker service lsID NAME MODE REPLICAS IMAGE PORTSklpwtncehp0v nginx-cluster replicated 5/5 nginx:latest *:80->80/tcp$ docker service update --replicas 2 nginx-clusternginx-cluster#将服务缩减到2个$ docker service lsID NAME MODE REPLICAS IMAGE PORTSklpwtncehp0v nginx-cluster replicated 2/2 nginx:latest *:80->80/tcp$ docker service update --image nginx:new nginx-cluster#更新服务的镜像版本$ docker rm nginx-cluster#将所有节点上的所有容器全部删除,任务也将全部删除
docker swarm 集群服务编排部署指南(docker stack) - DPDK原理的文章 - 知乎 https://zhuanlan.zhihu.com/p/620868766
Docker Swarm 集群管理
概述
Docker Swarm 是 Docker 的集群管理工具。它将 Docker 主机池转变为单个虚拟 Docker 主机,使得容器可以组成跨主机的子网网络。Docker Swarm 提供了标准的 Docker API,所有任何已经与 Docker 守护程序通信的工具都可以使用 Swarm 轻松地扩展到多个主机。
集群的管理和编排是使用嵌入到 docker 引擎的 SwarmKit,可以在 docker 初始化时启动 swarm 模式或者加入已存在的 swarm。
支持的工具包括但不限于以下各项:
- Dokku
- Docker Compose
- Docker Machine
- Jenkins
Docker Swarm 优点
- 任何规模都有高性能表现
对于企业级的 Docker Engine 集群和容器调度而言,可拓展性是关键。任何规模的公司——不论是拥有五个还是上千个服务器——都能在其环境下有效使用 Swarm。
经过测试,Swarm 可拓展性的极限是在 1000 个节点上运行 50000 个部署容器,每个容器的启动时间为亚秒级,同时性能无减损。
- 灵活的容器调度
Swarm 帮助 IT 运维团队在有限条件下将性能表现和资源利用最优化。Swarm 的内置调度器(scheduler)支持多种过滤器,包括:节点标签,亲和性和多种容器部策略如 binpack、spread、random 等等。
- 服务的持续可用性
Docker Swarm 由 Swarm Manager 提供高可用性,通过创建多个 Swarm master 节点和制定主 master 节点宕机时的备选策略。如果一个 master 节点宕机,那么一个 slave 节点就会被升格为 master 节点,直到原来的 master 节点恢复正常。
此外,如果某个节点无法加入集群,Swarm 会继续尝试加入,并提供错误警报和日志。在节点出错时,Swarm 现在可以尝试把容器重新调度到正常的节点上去。
- 和 Docker API 及整合支持的兼容性
Swarm 对 Docker API 完全支持,这意味着它能为使用不同 Docker 工具(如 Docker CLI,Compose,Trusted Registry,Hub 和 UCP)的用户提供无缝衔接的使用体验。
- Docker Swarm 为 Docker 化应用的核心功能(诸如多主机网络和存储卷管理)提供原生支持
开发的 Compose 文件能(通过 docker-compose up )轻易地部署到测试服务器或 Swarm 集群上。Docker Swarm 还可以从 Docker Trusted Registry 或 Hub 里 pull 并 run 镜像。
- 集群模式,当修改了服务的配置后无需手动重启服务。并且只有集群中的manager才能管理集群中的一切(包括服务、容器都归它管,在一个woker节点上无法操作容器)
节点
swarm 集群由管理节点(manager)和工作节点(work node)构成。
- swarm mananger:负责整个集群的管理工作包括集群配置、服务管理等所有跟集群有关的工作。一个 Swarm 集群可以有多个管理节点,但只有一个管理节点可以成为 leader,leader 通过 raft 协议实现。
为了利用swarm模式的容错功能,Docker建议根据组织的高可用性要求实现奇数个节点。当您拥有多个管理器时,您可以从管理器节点的故障中恢复而无需停机。
N个管理节点的集群容忍最多损失 (N-1)/2 个管理节点。
Docker建议一个集群最多7个管理器节点。
- work node:即图中的 available node,主要负责运行相应的服务来执行任务(task)。工作节点是任务执行节点,管理节点将服务 (service) 下发至工作节点执行。管理节点默认也作为工作节点。也可以通过配置让服务只运行在管理节点。
服务和任务
任务 (Task)是 Swarm 中的最小的调度单位,目前来说就是一个单一的容器。
服务 (Services) 是指一组任务的集合,服务定义了任务的属性。服务有两种模式:
replicated services (复制服务)按照一定规则在各个工作节点上运行指定个数的任务。
global services (全局服务)每个工作节点上运行一个此任务。
两种模式通过 docker service create 的 --mode 参数指定。下图展示了容器、任务、服务的关系。
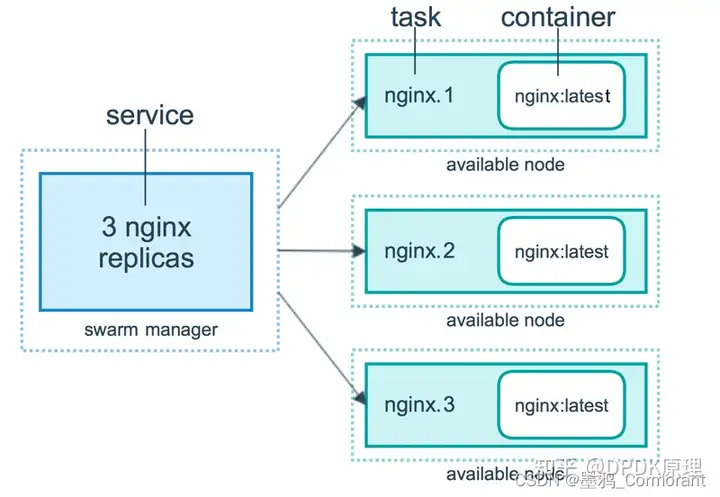
路由网格
service 通过 ingress load balancing 来发布服务,且 swarm 集群中所有 node 都参与到 ingress 路由网格(ingress routing mesh) 中,访问任意一个 node+PublishedPort 即可访问到服务。
当访问任何节点上的端口8080时,Docker将请求路由到活动容器。在群节点本身,端口8080可能并不实际绑定,但路由网格知道如何路由流量,并防止任何端口冲突的发生。
路由网格在发布的端口上监听分配给节点的任何IP地址。对于外部可路由的IP地址,该端口可从主机外部获得。对于所有其他IP地址,只能从主机内部访问。
Swarm 集群的搭建
准备工作
二个或二个以上可以通过网络进行通信的Linux主机或虚拟机,并安装了Docker(加入开机自启),或者使用docker-machine 创建三台虚拟机。swarm 不需要单独安装,安装了 docker 就自带了该软件
已安装Docker Engine 1.12或更高版本
关闭所有主机上的防火墙或者开放以下端口:
TCP协议端口 2377 :集群管理端口
TCP协议端口 7946 :节点之间通讯端口(不开放则会负载均衡失效)
UDP协议端口 4789 :overlay网络通讯端口
防火墙相关命令:
# 查看firewalld防火墙状态
systemctl status firewalld
# 查看所有打开的端口
firewall-cmd --zone=public --list-ports
# 防火墙开放端口(更新firewalld防火墙规则后生效)
firewall-cmd --zone=public --add-port=要开放的端口/tcp --permanent
# 选项:
–zone # 作用域
–add-port=80/tcp # 添加端口,格式为:端口/通讯协议
–permanent #永久生效,没有此参数重启后失效
# 示例:
firewall-cmd --zone=public --add-port=3306/tcp --permanent
# firewalld防火墙关闭接口(更新firewalld防火墙规则后生效)
firewall-cmd --zone=public --remove-port=要关闭的端口/tcp --permanent
# 更新firewalld防火墙规则(并不中断用户连接,即不丢失状态信息)
firewall-cmd --reload
# 启动firewalld防火墙
systemctl start firewalld
# 关闭firewalld防火墙:
systemctl stop firewalld
# 开机禁用firewalld防火墙
systemctl disable firewalld
# 开机启用firewalld防火墙:
systemctl enable firewalld
- 分别修改机器的主机名,更改成 swarm01,swarm02 …
hostnamectl set-hostname swarm01
创建docker swarm集群
1.master主机上初始化swarm。执行 docker swarm init 命令的节点自动成为管理节点。
docker swarm init
# 注:如果主机有多个网卡,拥有多个IP,必须使用 --advertise-addr 指定 IP。
# 示例:
docker swarm init --advertise-addr 192.168.99.100
# 执行命令后会给出加入这个swarm的命令
Swarm initialized: current node (4a8mo8cekpe0vpk0ze963avw9) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join --token SWMTKN-1-4lzr2216s61ecbyayyqynjwybmxy5y5th5ru8aal2a0d1t2vn3-ekdgf4swlz8fiq4nnzgnbhr5u 192.168.99.100:2377
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
2.在node主机上执行命令加入swarm
docker swarm join --token SWMTKN-1-4lzr2216s61ecbyayyqynjwybmxy5y5th5ru8aal2a0d1t2vn3-ekdgf4swlz8fiq4nnzgnbhr5u 192.168.99.100:23773.查看集群信息。集群的大部分命令需要在管理节点中才能运行
# 查看 swarm 集群状态
docker info
# 查看集群节点信息
docker node lsSwarm 集群管理常用命令
docker swarm:管理集群
# 初始化一个swarm
docker swarm init [OPTIONS]
# 选项:
--advertise-addr string # 发布的地址(格式:<ip|interface>[:port])
--force-new-cluster # 强制从当前状态创建一个新的集群(去除本地之外的所有管理器身份)
--cert-expiry duration # 节点证书有效期(ns|us|ms|s|m|h)(默认为2160h0m0s)
--data-path-addr string # 用于数据路径通信的地址或接口(格式: <ip|interface>)
--data-path-port uint32 # 用于数据路径流量的端口号(1024 - 49151)。如果没有值,则默认端口号4789
--dispatcher-heartbeat duration # 调度程序的心跳周期(ns|us|ms|s|m|h)(默认为5s)
--listen-addr node-addr # 监听地址(格式: <ip|interface>[:port]) (默认 0.0.0.0:2377)
# 查看加入节点到集群的命令及令牌(token)
docker swarm join-token [OPTIONS] (worker|manager)
# 选项:
-q, --quiet # 只显示令牌
--rotate # 使旧令牌无效并生成新令牌
# 查看加入工作节点到集群的命令及令牌
docker swarm join-token worker
# 查看加入管理节点到集群的命令及令牌
docker swarm join-token manager
# 将节点加入swarm集群,作为一个manager或worker
docker swarm join [OPTIONS] HOST:PORT
# 选项:
--advertise-addr string # 发布的地址 (格式: <ip|interface>[:port])
--availability string # 节点的可用性 ("active"|"pause"|"drain") (default "active")
--data-path-addr string # 用于数据路径通信的地址或接口 (格式: <ip|interface>)
--listen-addr node-addr # 监听地址 (格式: <ip|interface>[:port]) (default 0.0.0.0:2377)
--token string # 进入的swarm集群的令牌
# 主动退出集群,让节点处于down状态(在需要退出Swarm集群的节点主机上执行命令)
docker swarm leave [OPTIONS]
# 选项:
-f, --force # 强制。Manager若要退出 Swarm 集群,需要加上强制选项
## 移除一个work-node节点主机的完整步骤:
# 1.在管理节点上操作,清空work-node节点的容器。id 可以使用命令 docker node ls 查看
docker node update --availability drain [id]
# 2.在work-node节点主机上操作,退出集群
docker swarm leave
# 3,在管理节点上操作,删除work-node节点
docker node rm [id]
# 若想解散整个集群,则需先移除所有work-node节点主机,然后所有管理节点也退出集群
# 更新 swarm 集群的配置
docker swarm update [OPTIONS]
# 选项:
--autolock # 更改管理器自动锁定设置(true|false)
--cert-expiry duration # 节点证书有效期(ns|us|ms|s|m|h)(默认为2160h0m0s)
--dispatcher-heartbeat duration # 调度程序心跳周期(ns|us|ms|s|m|h)(默认为5s)
docker node:管理swarm集群节点
# 查看集群中的节点
docker node ls
#选项:
-f, --filter filter # 根据所提供的条件过滤输出。(格式:key=value)
# 目前支持的过滤器是:id, label, name, membership[=accepted|pending]
# , role[manager|worker]
-q, --quiet # 只显示id
# 查看运行的一个或多个及节点任务数,默认当前节点
docker node ps [OPTIONS] [NODE...]
#选项:
-f, --filter filter # 根据所提供的条件过滤输出
-q, --quiet # 只显示id
# 将worker角色升级为manager
docker node promote NODE [NODE...]
# 将manager角色降级为worker
docker node demote NODE [NODE...]
# 查看节点的详细信息,默认json格式
docker node inspect 主机名
# 查看节点信息平铺格式
docker node inspect --pretty 主机名
# 从swarm中删除一个节点
docker node rm 主机名
# 从swarm中强制删除一个节点
docker node rm -f 主机名
# 更新一个节点
docker node update [options] 主机名
# 选项
--label-add list # 添加节点标签(key=value)
--label-rm list # 删除节点标签
--role string # 更改节点角色 ("worker"|"manager")
--availability active/pause/drain # 设置节点的状态
# active 正常
# pause 暂停。调度程序不向节点分配新任务,但是现有任务仍然保持运行
# drain 排除自身work任务。调度程序不向节点分配新任务,且会关闭任何现有任务并在可用节点上安排它们
docker service:服务管理
# 列出服务列表
docker service ls
# 列出服务任务信息
docker service ps [OPTIONS] SERVICE [SERVICE...]
# 选项:
--no-trunc # 显示完整的信息
-f, --filter filter # 根据所提供的条件过滤输出。过滤只运行的任务信息:"desired-state=running"
-q, --quiet # 只显示任务id
# 查看服务内输出
docker service logs [OPTIONS] SERVICE|TASK
# 选项:
--details # 显示提供给日志的额外细节
-f, --follow # 跟踪日志输出
--since string # 显示自时间戳 (2013-01-02T13:23:37Z) 或相对时间戳 (42m for 42 minutes) 以来的日志
-n, --tail string # 从日志末尾显示的行数(默认为“all”)
-t, --timestamps # 显示时间戳
# 更新服务的相关配置
docker service update [options] 服务名
# 选项
--args "指令" # 容器加入指令
--image IMAGE # 更新服务容器镜像
--rollback # 回滚服务容器版本
--network-add 网络名 # 添加容器网络
--network-rm 网络名 # 删除容器网络
--reserve-cpu int # 更新分配的cpu
--reserve-memory bytes # 更新分配的内存(示例:512m)
--publish-add 暴露端口:容器端口 # 映射容器端口到主机
--publish-rm 暴露端口:容器端口 # 移除暴露端口
--endpoint-mode dnsrr # 修改负载均衡模式为dnsrr
--force # 强制重启服务
--config-rm 配置文件名称 # 删除配置文件
--constraint-add list # 新增一个约束
--constraint-rm list # 移除一个约束
--placement-pref-add pref # 新增一个偏好
--placement-pref-rm pref # 移除一个偏好
--config-add 配置文件名,target=/../容器内配置文件名 # 添加新的配置文件到容器内
# 查看服务详细信息,默认json格式
docker service inspect [OPTIONS] 服务名 [SERVICE...]
# 查看服务信息平铺形式
docker service inspect --pretty 服务名
# 删除服务
docker service rm [OPTIONS] 服务名 [SERVICE...]
# 缩容扩容服务容器副本数量
docker service scale 服务名=副本数 [SERVICE=REPLICAS...]
# 创建一个服务。一般搭建好 Swarm 集群后,使用 docker stack 部署应用,此处仅作了解
docker service create [OPTIONS] IMAGE [COMMAND] [ARG...]
# 选项:
--name string # 指定容器名称
--replicas int # 指定副本数
--network 网络名 # 添加网络组
--mode string # 服务模式(复制或全局)(replicated | global)
--reserve-cpu int # 预留的cpu
--reserve-memory bytes # 预留的内存(512m)
--limit-cpu int # 限制CPU
--limit-memory bytes # 限制内存(512m)
-l, --label list # 服务的标签(key=value)
--container-label list # 容器标签(key=value)
-p, --publish 暴露端口:容器端口 # 映射容器端口到主机
-e, --env MYVAR=myvalue # 配置环境变量
-w, --workdir string # 指定工作目录(示例:/tmp)
-restart-condition string # 满足条件时重新启动(no | always | on-failure | unless-stopped)
--restart-delay duration # 重新启动尝试之间的延迟 (ns/us/ms/s/m/h)
--restart-max-attempts int # 放弃前的最大重启次数
--restart-window duration # 用于评估重启策略的窗口 (ns/us/ms/s/m/h)
--stop-grace-period duration # 强制杀死容器前的等待时间 (ns/us/ms/s/m/h)
--update-delay duration # 更新之间的延迟(ns/us/ms/s/m/h)(默认 0s)
--update-failure-action string # 更新失败的操作("pause"停止|"continue"继续)(默认pause)
--update-max-failure-ratio float # 更新期间容忍的失败率
--update-monitor duration # 每次任务更新后监控失败的持续时间(ns/us/ms/s/m/h)(默认 0s)
--update-parallelism int # 同时更新的最大任务数(0表示一次更新全部任务)(默认为1)
--endpoint-mode string # 负载均衡模式(vip or dnsrr) (默认 "vip")
--rollback-monitor 20s # 每次容器与容器之间的回滚时间间隔
--rollback-max-failure-ratio .数值 # 回滚故障率如果小于百分比允许运行(“.2”为%20)
--mount type=volume,src=volume名称,dst=容器目录 # 创建volume类型数据卷
--mount type=bind,src=宿主目录,dst=容器目录 # 创建bind读写目录挂载
--mount type=bind,src=宿主目录,dst=容器目录,readonly # 创建bind只读目录挂载
--config source=docker配置文件,target=配置文件路径 # 创建docker配置文件到容器本地目录
docker config:管理配置文件
# 查看已创建配置文件
docker config ls [OPTIONS]
# 选项:
-f, --filter filter # 根据所提供的条件过滤输出
-q, --quiet # 只显示id
# 查看配置详细信息
docker config inspect 配置文件名
# 删除配置
docker config rm CONFIG [CONFIG...]
# 创建配置文件
docker config create 配置文件名 本地配置文件
# 示例:新建配置文件并添加新配置文件到服务
# 1.创建配置文件
docker config create nginx2_config nginx2.conf
# 2.删除旧配置文件
docker service update --config-rm ce_nginx_config 服务名
# 3.添加新配置文件到服务
ocker service update --config-add src=nginx2_config,target=/etc/nginx/nginx.conf ce_nginx
docker network:管理网络
# 查看集群网络列表
docker network ls
# 将容器连接到集群网络中
$ docker network connect [OPTIONS] NETWORK CONTAINER
# 选项
--alias strings # 为容器添加网络范围的别名
--driver-opt string · # 指定网络驱动程序
--ip string # 指定IPv4地址(如172.30.100.104)
--ip6 string # 指定IPv6地址(例如,2001:db8::33)
--link list # 添加到另一个容器的链接
--link-local-ip string # 为容器添加一个链接本地地址
# 示例
docker network connect mynet nginx
# 断开一个容器与集群网络的连接
$ docker network disconnect [OPTIONS] NETWORK CONTAINER
# 选项
-f, --force # 强制容器从网络断开连接
# 显示一个或多个集群网络的详细信息
$ docker network inspect [OPTIONS] NETWORK [NETWORK...]
# 选项
-f, --format string # 使用给定的Go模板格式化输出
-v, --verbose # 输出详细的诊断信息
# 创建一个集群网络
$ docker network create [OPTIONS] NETWORK
# 选项
--attachable # 准许手动容器连接
--aux-address map # 网络驱动使用的辅助IPv4或IPv6地址(默认映射[])
--config-from string # 要从其中复制配置的网络
--config-only # 创建仅配置网络
-d, --driver string # 管理网络的驱动程序(默认为“"bridge”)。选项:bridge、overlay、macvlan
--gateway strings # 指定IPv4或IPv6主子网网关。示例:172.20.0.1
--ingress # 创建群路由-网格网络
--internal # 限制外部访问网络
--ip-range strings # 从子范围分配容器ip
--ipam-driver string # IP管理驱动(默认为“default”)
--ipam-opt map # 设置IPAM驱动程序的特定选项(默认map[])
--ipv6 # 启用IPv6网络
--label list # 在网络中设置元数据
-o, --opt map # 设置驱动程序特定选项(默认map[])
--scope string # 控制网络的范围
--subnet strings # 指定一个CIDR格式的网段。示例:172.20.0.0/24
# 示例:
docker network create -d overlay --attachable apps_net
# 移除所有未使用的集群网络
$ docker network prune [OPTIONS]
# 选项
--filter filter # 提供过滤值(e.g. 'until=<timestamp>')
-f, --force # 强制,没有提示确认
# 删除一个或多个集群网络
$ docker network rm NETWORK [NETWORK...]
# 别名:rm, remove
docker secret:管理敏感数据存储
# 查看敏感数据卷列表
$ docker secret ls
# 显示一个或多个敏感数据卷的详细信息
$ docker secret inspect [OPTIONS] SECRET [SECRET...]
# 选项
--pretty # 易读的格式打印信息
# 从文件或标准输入创建一个敏感数据卷作为内容
$ docker secret create [OPTIONS] SECRET [file|-]
# 选项
-d, --driver string # 指定驱动
-l, --label list # 指定标签
--template-driver string # 指定模板驱动程序
# 移除一个或多个敏感数据卷
$ docker secret rm SECRET [SECRET...]
# 别名:rm, removedocker网络管理
参考:
docker的3种自定义网络(bridge、overlay、macvlan)
Docker Swarm - 网络管理
Docker的网络模式bridge、host、container 、overlay
概述
Docker 提供三种 user-defined 网络驱动:bridge,overlay 和 macvlan
overlay 和 macvlan 用于创建跨主机的网络
Swarm 集群产生两种不同类型的流量:
- 控制和管理层面:包括 Swarm 消息管理等,例如请求加入或离开Swarm,这种类型的流量总是被加密的。(涉及到集群内部的hostname、ip-address、subnet、gateway等)
- 应用数据层面:包括容器与客户端的通信等。(涉及到防火墙、端口映射、网口映射、VIP等)
在 Swarm Service 中有三个重要的网络概念:
- Overlay networks :管理 Swarm 中 Docker 守护进程间的通信。可以将服务附加到一个或多个已存在的 overlay 网络上,使得服务与服务之间能够通信。
- ingress network :是一个特殊的 overlay 网络,用于服务节点间的负载均衡,处理与群集服务相关的控制和数据流量。当任何 Swarm 节点在发布的端口上接收到请求时,它将该请求交给一个名为 IPVS 的模块。IPVS 跟踪参与该服务的所有IP地址,选择其中的一个,并通过 ingress 网络将请求路由到它。
- 初始化或加入 Swarm 集群时会自动创建 ingress 网络,大多数情况下,用户不需要自定义配置,但是 docker 17.05 和更高版本允许你自定义。
- docker_gwbridge :是一种桥接网络,将 overlay 网络(包括 ingress 网络)连接到一个单独的 Docker 守护进程的物理网络。默认情况下,服务正在运行的每个容器都连接到本地 Docker 守护进程主机的 docker_gwbridge 网络。
- docker_gwbridge 网络在初始化或加入 Swarm 时自动创建。大多数情况下,用户不需要自定义配置,但是 Docker 允许自定义。
在管理节点上查看网络
$ docker network ls
NETWORK ID NAME DRIVER SCOPE
cb0ccb89a988 bridge bridge local
0174fb113496 docker_gwbridge bridge local
541b62778c0e host host local
8n7xppn5z4j2 ingress overlay swarm
369d459f340d none null localoverlay网络驱动程序会创建多个Docker守护主机之间的分布式网络。该网络位于(覆盖)特定于主机的网络之上,允许连接到它的容器(包括群集服务容器)安全地进行通信。Docker透明地处理每个数据包与正确的Docker守护程序主机和正确的目标容器的路由。
自定义overlay 网络
创建用于swarm服务的自定义的overlay网络 命令:
docker network create -d overlay --attachable my-overlay
# 注:overlay 网络创建可以在 Swarm 集群下的任意节点执行,并同步更新到所有节点。
集群中部署了两个服务 nginx、alpine,现在我们进入alpine,去访问nginx。
$ docker exec -it test1.1.oonwl8c5g4u3p17x8anifeubi bash
$ ping nginx
ping: bad address 'nginx'
$ wget 192.168.99.100:8080
Connecting to 192.168.99.100:8080 (192.168.99.100:8080)
index.html 100% |**********************************************************************************************************| 612 0:00:00 ETA
发现集群中的各个服务不能用名称访问的,只能用集群服务发现的路由网络访问,若需要集群中的服务能通过名称进行访问,这就需要用到上面自定义的 overlay 网络。
删除启动的服务,重新创建指定使用自定义网络的服务。
docker service rm nginx alpine
docker service create --name nginx -p 8080:80 --network my-overlay --replicas 3 nginx
docker service create --name alpine --network my-overlay alpine ping www.baidu.com
进入alpine容器中,重新测试下:
$ ping nginx
PING nginx (10.0.0.2): 56 data bytes
64 bytes from 10.0.0.2: seq=0 ttl=64 time=0.120 ms
64 bytes from 10.0.0.2: seq=1 ttl=64 time=0.094 ms
64 bytes from 10.0.0.2: seq=2 ttl=64 time=0.108 ms
$ wget nginx
Connecting to nginx (10.0.0.2:80)
index.html 100% |**********************************************************************************************************| 612 0:00:00 ETA
发现可以通过名称进行集群中的容器间的访问了。
Docker Stack 部署应用
概述
单机模式下,可以使用 Docker Compose 来编排多个服务。Docker Swarm 只能实现对单个服务的简单部署。而Docker Stack 只需对已有的 docker-compose.yml 配置文件稍加改造就可以完成 Docker 集群环境下的多服务编排。
stack是一组共享依赖,可以被编排并具备扩展能力的关联service。
Docker Stack和Docker Compose区别
- Docker stack 会忽略了“构建”指令,无法使用 stack 命令构建新镜像,它是需要镜像是预先已经构建好的。 所以 docker-compose 更适合于开发场景;
- Docker Compose 是一个 Python 项目,在内部,它使用 Docker API 规范来操作容器。所以需要安装 Docker -compose,以便与 Docker 一起在计算机上使用;Docker Stack 功能包含在 Docker 引擎中。你不需要安装额外的包来使用它,docker stacks 只是 swarm mode 的一部分。
- Docker stack 不支持基于第2版写的 docker-compose.yml ,也就是 version 版本至少为3。然而 Docker Compose 对版本为2和 3 的文件仍然可以处理;
- docker stack 把 docker compose 的所有工作都做完了,因此 docker stack 将占主导地位。同时,对于大多数用户来说,切换到使用
- 单机模式(Docker Compose)是一台主机上运行多个容器,每个容器单独提供服务;集群模式(swarm + stack)是多台机器组成一个集群,多个容器一起提供同一个服务;
compose.yml deploy 配置说明
docker-compose.yaml 文件中 deploy 参数下的各种配置主要对应了 swarm 中的运维需求。
docker stack deploy 不支持的参数:
(这些参数,就算yaml中包含,在stack的时候也会被忽略,当然也可以为了 docker-compose up 留着这些配置)
build
cgroup_parent
container_name
devices
tmpfs
external_links
links
network_mode
restart
security_opt
userns_mode
deploy:指定与服务的部署和运行有关的配置。注:只在 swarm 模式和 stack 部署下才会有用。且仅支持 V3.4 及更高版本。
可以选参数:
endpoint_mode:访问集群服务的方式。3.2版本开始引入的配置。用于指定服务发现,以方便外部的客户端连接到swarm
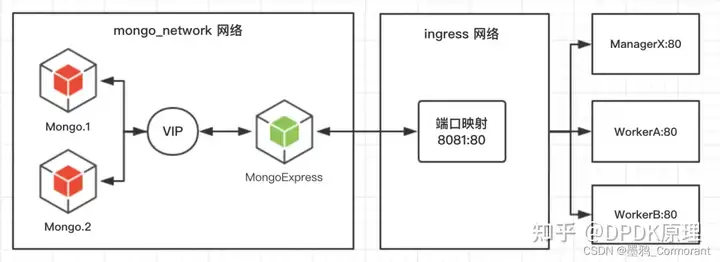
vip:默认的方案。即通过 Docker 集群服务一个对外的虚拟 ip对外暴露服务,所有的请求都会通过这个虚拟 ip 到达集群服务内部的机器,客户端无法察觉有多少个节点提供服务,也不知道实际提供服务的IP和端口。
dnsrr:DNS的轮询调度。所有的请求会自动轮询获取到集群 ip 列表中的一个 ip 地址。客户端访问的时候,Docker集群会通过DNS列表返回对应的服务一系列IP地址,客户连接其中的一个。这种方式通常用于使用自己的负载均衡器,或者window和linux的混合应用。
labels:在服务上设置标签,并非附加在service中的容器上。如果在容器上设置标签,则在deploy之外定义labels。可以用容器上的 labels(跟 deploy 同级的配置) 覆盖 deploy 下的 labels。
mode:用于指定是以副本模式(默认)启动还是全局模式
- replicated:副本模式,复制指定服务到集群的机器上。默认。
- global:全局模式,服务将部署至集群的每个节点。类似于k8s中的DaemonSet,会在每个节点上启动且只启动一个服务。
replicas:用于指定副本数,只有mode为副本模式的时候生效。
placement:主要用于指定约束和偏好。这个参数在运维的时候尤为关键
- constraints(约束):表示服务可以部署在符合约束条件的节点上,包含了:
node attribute matches example
Home | NODE.ID 节点id Home | NODE.ID == 2ivku8v2gvtg4
node.hostname 节点主机名 node.hostname != node-2
node.role 节点角色 (manager/worker node.role == manager
node.platform.os 节点操作系统 node.platform.os == windows
node.platform.arch 节点架构 node.platform.arch == x86_64
node.labels 用户定义的labels node.labels.security == high
engine.labels Docker 引擎的 labels engine.labels.operatingsystem == ubuntu-14.04
preferences(偏好):表示服务可以均匀分布在指定的标签下。
preferences 只有一个参数,就是spread,其参数值为节点的属性,即约束表中的内容
例如:node.labels.zone这个标签在集群中有三个值,分别为west、east、north,那么服务中的副本将会等分为三份,分布到带有三个标签的节点上。
max_replicas_per_node:3.8版本中开始引入的配置。控制每个节点上最多的副本数。
注意:当 最大副本数*集群中可部署服务的节点数<副本数,会报错
resources:用于限制服务的资源,这个参数在运维的时候尤为关键。
示例:配置 redis 集群运行需要的 cpu 的百分比 和 内存的占用。避免占用资源过高出现异常。
- limit:用于限制最大的资源使用数量
cpus:cpu占比,值的格式为百分比的小数格式
memory:内存的大小。示例:512M
- reservation:为最低的资源占用量。
cpus
memory
- restart_policy:容器的重启策略
condition:重启的条件。可选 none,on-failure 或者 any。默认值:any
delay:尝试重启的时间间隔(默认值:5s)。
max_attempts:最大尝试重启容器的次数,超出次数,则不再尝试(默认值:一直重试)。
window:判断重启是否成功之前的等待时间(一个总的时间,如果超过这个时间还没有成功,则不再重启)。
- rollback_config:更新失败时的回滚服务的策略。3.7版本加入。和升级策略相关参数基本一致。
- update_config:配置应如何更新服务,对于配置滚动更新很有用。
parallelism:同时升级[回滚]的容器数
delay:升级[回滚]一组容器的时间间隔
failure_action:若更新[回滚]失败之后的策略:continue、 pause、rollback(仅在update_config中有) 。默认 pause
monitor:容器升级[回滚]之后,检测失败的时间检测 (支持的单位:ns|us|ms|s|m|h)。默认为 5s
max_failure_ratio:最大失败率
order:升级[回滚]期间的操作顺序。可选:stop-first(串行回滚,先停止旧的)、start-first(并行回滚,先启动新的)。默认 stop-first 。注意:只支持v3.4及更高版本
compose.yml 文件示例
version: "3" # 版本号,deploy功能是3版本及以上才有的
services: # 服务,每个服务对应配置相同的一个或者多个docker容器
redis: # 服务名,自取
image: redis:alpine # 创建该服务所基于的镜像。使用stack部署,只能基于镜像
ports: # 容器内外的端口映射情况
- "1883:1883"
- "9001:9001"
networks: # 替代了命令行模式的--link选项
- fiware
volumes: # 容器内外数据传输的对应地址
- "/srv/mqtt/config:/mqtt/config:ro"
- "/srv/mqtt/log:/mqtt/log"
- "/srv/mqtt/data/:/mqtt/data/"
command: -dbhost stack_mongo # 命令行模式中跟在最后的参数,此条没有固定的格式,建议参照所部署的docker镜像的说明文档来确定是否需要该项、需要写什么
deploy:
mode: replicated
replicas: 6 # replicas模式, 副本数目为1
endpoint_mode: vip
labels:
description: "This redis service label"
resources:
limits:
cpus: '0.50'
memory: 50M
reservations:
cpus: '0.25'
memory: 20M
restart_policy:
condition: on-failure
delay: 5s
max_attempts: 3
window: 120s
placement:
constraints:
- "node.role==worker" # 部署位置,只在工作节点部署
- "engine.labels.operatingsystem==ubuntu 18.04"
preferences:
- spread: node.labels.zone
update_config:
parallelism: 2
delay: 10s
order: stop-first
networks: # 定义部署该项目所需要的网络
fiware:
stack 常用命令
docker stack:编排部署应用
# 部署一个新的stack(堆栈)或更新现有的stack。别名:deploy, up
docker stack deploy [OPTIONS] 自定义STACK名称
# 选项:
-c, --compose-file strings # Compose文件的路径,或从标准输入中读取的“-”
--prune # 表示削减不再引用的服务。可以把一些down掉的service进行自动清理。
--orchestrator string # 指定编排模式 (swarm|kubernetes|all)
--resolve-image string # 请求仓库来重新解析镜像的摘要和支持的平台。("always"|"changed"|"never") (默认 "always")
--with-registry-auth # 发送仓库的授权详情到Swarm代理
--orchestrator # 使用的容器编排服务
# 通过compose.yml文件指令部署
docker stack deploy -c 文件名.yml 自定义STACK名称
# 列出现有堆栈。别名:ls, list
docker stack ls [OPTIONS]
# 列出堆栈中的任务
docker stack ps [OPTIONS] STACK
# 选项:
--no-trunc # 输出完整信息
# 删除一个或多个堆栈。别名:rm, remove, down
docker stack rm [OPTIONS] STACK [STACK...]
# 选项
--orchestrator string # 指定适配器 (swarm|kubernetes|all)
# 列出堆栈中的服务
docker stack services [OPTIONS] STACK
 浙公网安备 33010602011771号
浙公网安备 33010602011771号