聚集索引和非聚集索引的理解
首先理解一下什么是聚集索引什么是非聚集索引?
我们先看看百度百科对聚集索引的定义:

天呐,这是什么??
新技术人被英语差、技术又菜的前辈的可怕翻译迫害,想想都是一件可怕的事。
我们看个正常的定义:
A clustered index is a special type of index that reorders the way records in the table are physically stored. Therefore table can have only one clustered index. The leaf nodes of a clustered index contain the data pages.
A nonclustered index is a special type of index in which the logical order of the index does not match the physical stored order of the rows on disk. The leaf node of a nonclustered index does not consist of the data pages. Instead, the leaf nodes contain index rows.
其实很简单,我们的sql数据库是行数据库,数据是一行一行存储的,而聚集索引是个特殊的索引,相当于这一行行记录的物理编号,描述这一行行数据的物理存储顺序。所以,一张表只会有一个聚集索引。
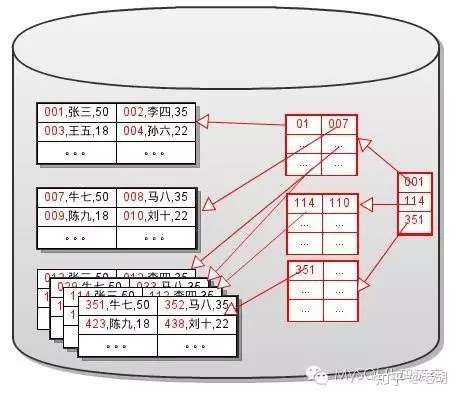
如图,聚集索引的叶子节点指向的就是实际数据页,两个相邻的聚集索引1和2,它们指向数据块上的位置——张三和李四,也得给我住两隔壁。
拿mysql来说,聚集索引通常是表的主键,若无主键则为表中第一个非空的唯一索引,还是没有就采用innodb存储引擎为每行数据内置的ROWID作为聚集索引(隐藏索引)。
再来,不是聚集索引的就是非聚集索引,两个相邻排排站的非聚集索引,它们实际指向的数据可能隔了十万八千里。天呐,其实它就是二级索引啊。
举个例子吧:
create table people (
`id` INT UNSIGNED AUTO_INCREMENT,
`name` VARCHAR(20),
PRIMARY KEY(`id`),
KEY(`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;该表主键id就是该表的聚集索引,name就是非聚集索引;表中每行数据都是按id排序存储的;
比如要查找名字是'Aa'和'Ab'这两个人,他们在name索引表中的位置可能是相邻的,但实际的存储位置则不然。
通过name索引最终只能查出数据的主键,然后再按主键捞出来。
聚集索引只能有一个,非聚集索引可以有多个。
那么为什么重复率高的字段不适合作为索引
理论文章会告诉你值重复率高的字段不适合建索引。不要说性别字段只有两个值,网友亲测,一个字段使用拼音首字母做值,共有26种可能,加上索引后,百万加的数据量,使用索引的速度比不使用索引要慢!
一个表可能会涉及两个数据结构(文件),一个是表本身,存放表中的数据,另一个是索引。索引是什么?它就是把一个或几个字段(组合索引)按规律排列起来,再附上该字段所在行数据的物理地址(位于表中)。比如我们有个字段是年龄,如果要选取某个年龄段的所有行,那么一般情况下可能需要进行一次全表扫描。但如果以这个年龄段建个索引,那么索引中会按年龄值建一个排列,这样在索引中就能迅速定位,不需要进行全表扫描。
为什么性别不适合建索引呢?因为你访问索引需要付出额外的IO开销,你从索引中拿到的只是地址,要想真正访问到数据还是要对表进行一次IO。假如你要从表的100万行数据中取几个数据,那么利用索引迅速定位,访问索引的这IO开销就非常值了。但如果你是从100万行数据中取50万行数据,就比如性别字段,那你相对需要访问50万次索引,再访问50万次表(非聚集索引会先找主键,也就是回表),加起来的开销并不会比直接对表进行一次完整扫描小。同时,虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行 INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据还要更新索引。建立索引会占用磁盘空间。一般情 况这个问题不太严重,但如果你在一个大表上创建了多种组合索引,索引文件的会膨胀很快。
当然凡事不是绝对,如果把性别字段设为表的聚集索引,那么就肯定能加快大约一半该字段的查询速度了。聚集索引指的是表本身中数据按哪个字段的值来进行排序。因此,聚集索引只能有一个,而且使用聚集索引不会付出额外IO开销(一级索引,非聚集索引是二级索引,额外一次io)。当然你得能舍得把聚集索引这么宝贵资源用到性别字段上。
由于重复率高,那么一个重复值就会根据索引去表中进行多次查询,每次查询就是一次io,而遍历表就需要一次io,所以重复率高带来的额外io开销是很大的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号