lr_bn_batchsize_deformable convolution_Hard negative mining
LR
学习率的调整方法:
1、从自己和其他人一般的经验来看,学习率可以设置为3、1、0.5、0.1、0.05、0.01、0.005,0.005、0.0001、0.00001具体需结合实际情况对比判断,小的学习率收敛慢,但能将loss值降到更低。
2、根据数据集的大小来选择合适的学习率,当使用平方和误差作为成本函数时,随着数据量的增多,学习率应该被设置为相应更小的值(从梯度下降算法的原理可以分析得出)。另一种方法就是,选择不受数据集大小影响的成本函数-均值平方差函数。
3、训练全过程并不是使用一个固定值的学习速度,而是随着时间的推移让学习率动态变化,比如刚开始训练,离下山地点的最优值还很远,那么可以使用较大的学习率下的快一点,当快接近最优值时为避免跨过最优值,下山速度要放缓,即应使用较小学习率训练,具体情况下因为我们也不知道训练时的最优值,所以具体的解决办法是:在每次迭代后,使用估计的模型的参数来查看误差函数的值,如果相对于上一次迭代,错误率减少了,就可以增大学习率如果相对于上一次迭代,错误率增大了,那么应该重新设置上一轮迭代的值,并且减少学习率到之前的50%。因此,这是一种学习率自适应调节的方法。在Caffe、Tensorflow等深度学习框架中都有很简单直接的学习率动态变化设置方法。
Batch size
batchsize太小,在一定的epoch下很难达到低谷,学习很慢,太大,一是内存不够,二是loss降不下去泛化性能差,所以在常见的setting(~100 epochs),batch size一般不会低于16。.
BN
一般网络深度增加会出现梯度消失和梯度爆炸,SIGMOD激活函数会导致梯度消失,一般采用rule激活函数或者leaky rule.当网络初始化权重很大会导致梯度爆炸,一般采样削峰剪枝处理。
聊聊Batch Normalization在网络结构中的位置 - 知乎 (zhihu.com)
1. 什么是Batch Normalization?
谷歌在2015年就提出了Batch Normalization(BN),该方法对每个mini-batch都进行normalize,下图是BN的计算方式,会把mini-batch中的数据正规化到均值为0,标准差为1,同时还引入了两个可以学的参数,分别为scale和shift,让模型学习其适合的分布。

那么为什么在做过正规化后,又要scale和shift呢?当通过正规化后,把尺度缩放到0均值,再scale和shift,不是有可能把数据变回"原样"?因为scale和shift是模型自动学习的,神经网络可以自己琢磨前面的正规化有没有起到优化作用,没有的话就"反"正规化,抵消之前的正规化操作带来的影响。
2. 为什么要用Batch Normalization?
(1) 解决梯度消失问题
拿sigmoid激活函数距离,从图中,我们很容易知道,数据值越靠近0梯度越大,越远离0梯度越接近0,我们通过BN改变数据分布到0附近,从而解决梯度消失问题。
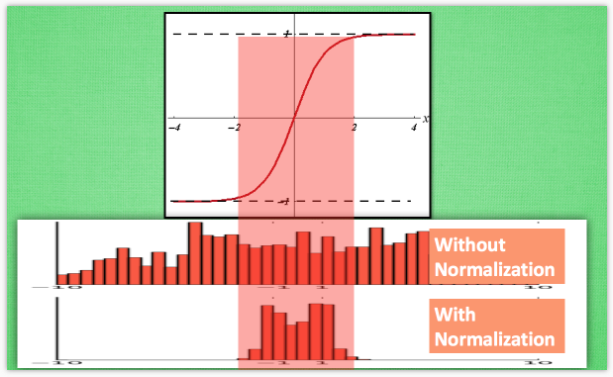
(2) 解决了Internal Covariate Shift(ICS)问题
先看看paper里对ICS的定义:

由于训练过程中参数的变化,导致各层数据分布变化较大,神经网络就要学习新的分布,随着层数的加深,学习过程就变的愈加困难,要解决这个问题需要使用较低的学习率,由此又产生收敛速度慢,因此引入BN可以很有效的解决这个问题。
(3)加速了模型的收敛
和对原始特征做归一化类似,BN使得每一维数据对结果的影响是相同的,由此就能加速模型的收敛速度。
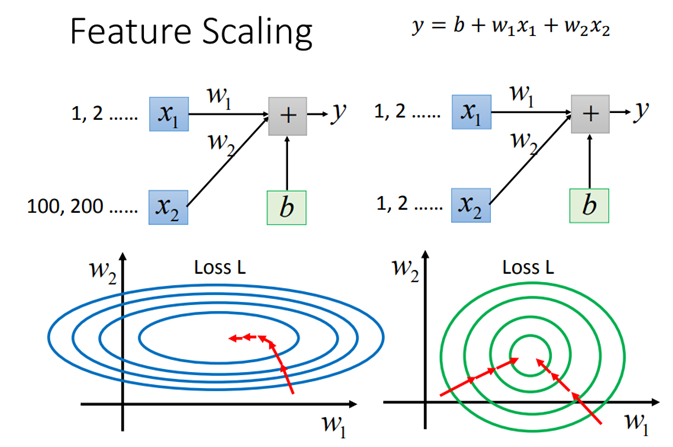
(4)具有正则化效果
BN层和正规化/归一化不同,BN层是在mini-batch中计算均值方差,因此会带来一些较小的噪声,在神经网络中添加随机噪声可以带来正则化的效果。
3. Batch Normalization添加在哪?
所以实际使用上,BatchNorm层应该放在哪呢?层与层直接都要加吗?加在激活函数前还是激活函数后?卷积层和pooling层要不要加?有人说这个应该加在非线性层后,如下顺序。
Linear->Relu->BatchNorm->Dropout
论文里有提到,BN层常常被加到Relu之前,但是没有明确的标准,需要尝试不同配置,通过实验得出结论(很多实验结果偏向于Relu在BN之前)。
那BN层和dropout层的顺序呢?
我们可以看到这样的代码,BN在dropout之后。

也可以看到这样的代码,BN在dropout之前。

实际上,BN消除了对dropout的依赖,因为BN也有和dropout本质一样的正则化的效果,像是ResNet, DenseNet等等并没有使用dropout,如果要用并用BN和dropout,还是建议BN放在dropout之前。
注:对BN和dropout感兴趣的可以看下这篇论文《Understanding the Disharmony between Dropout and Batch Normalization by Variance Shif》https://arxiv.org/pdf/1801.05134.pdf

deformable convolution
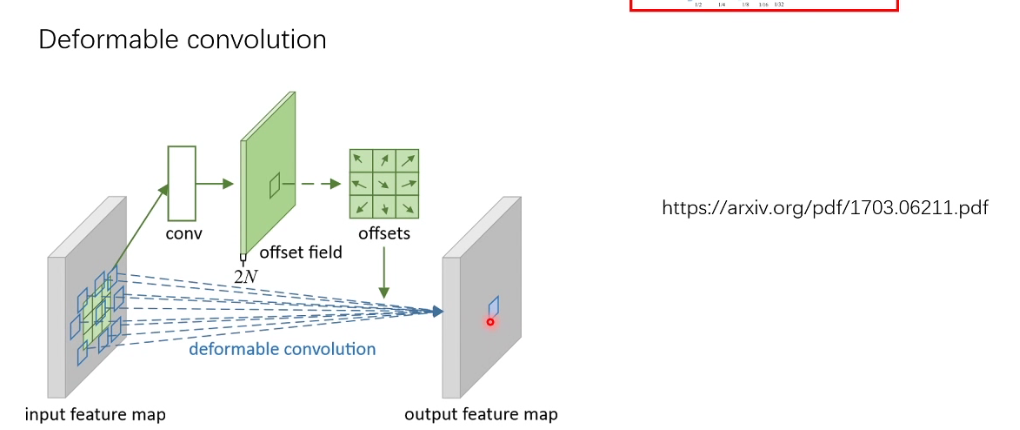
这种卷积方法可以扩大感受野
现在原始位置做卷积,然后计算偏移,之后在偏移的地方再次进行计算卷积

cv2.minAreaReact(),计算出包括区域的最小矩形

 浙公网安备 33010602011771号
浙公网安备 33010602011771号