mysql的事务以及隔离级别
MySQL 事务
本文所说的 MySQL 事务都是指在 InnoDB 引擎下,MyISAM 引擎是不支持事务的。
数据库事务指的是一组数据操作,事务内的操作要么就是全部成功,要么就是全部失败,什么都不做,其实不是没做,是可能做了一部分但是只要有一步失败,就要回滚所有操作,有点一不做二不休的意思。
假设一个网购付款的操作,用户付款后要涉及到订单状态更新、扣库存以及其他一系列动作,这就是一个事务,如果一切正常那就相安无事,一旦中间有某个环节异常,那整个事务就要回滚,总不能更新了订单状态但是不扣库存吧,这问题就大了。
事务具有原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)四个特性,简称 ACID,缺一不可。今天要说的就是隔离性。
原子性Atomicity
指事务必须是一个原子的操作序列单元。事务中包含的各项操作在一次执行过程中,只允许出现以下两种状态之一
.全部成功执行。
· 全部不执行。
任何一项操作失败都将导致整个事务失败,同时其他已经被执行的操作都将被撤销并回滚,只有所有的操作全部成功,整个事务才算是成功完成。
一致性Consistency
一个事务在执行之前和执行之后,数据库都必须处于一致性状态。
事务都完成成功,数据库处于一致性状态。
如果数据库系统在运行过程中发生故障,有些事务尚未完成就被迫中断,这些所做的修改有一部分已写入物理数据库,这时数据库就处于一种不正确的状态,或者说是不一致的状态。
隔离性Isolation
事务的隔离性是指在并发环境中,并发的事务是相互隔离的,一个事务的执行不能被其他事务干扰。不同的事务并发操纵相同的数据时,每个事务都有各自完整的数据空间,并发执行的各个事务之间不能互相干扰。
持久性Durability
指一个事务一旦提交,它对数据库中对应数据的状态变更就应该是永久性的。即使发生系统崩溃或机器宕机等故障,只要数据库能够重新启动,那么一定能够将其恢复到事务成功结束时的状态。
隔离性设计的概念说明
以下几个概念是事务隔离级别要实际解决的问题,所以需要搞清楚都是什么意思。
脏读
脏读指的是读到了其他事务未提交的数据,未提交意味着这些数据可能会回滚,也就是可能最终不会存到数据库中,也就是不存在的数据。读到了并一定最终存在的数据,这就是脏读。
可重复读
可重复读指的是在一个事务内,最开始读到的数据和事务结束前的任意时刻读到的同一批数据都是一致的。通常针对数据更新(UPDATE)操作。
不可重复读
对比可重复读,不可重复读指的是在同一事务内,不同的时刻读到的同一批数据可能是不一样的,可能会受到其他事务的影响,比如其他事务改了这批数据并提交了。通常针对数据更新(UPDATE)操作。
幻读
幻读是针对数据插入(INSERT)操作来说的。假设事务A对某些行的内容作了更改,但是还未提交,此时事务B插入了与事务A更改前的记录相同的记录行,并且在事务A提交之前先提交了,而这时,在事务A中查询,会发现好像刚刚的更改对于某些数据未起作用,但其实是事务B刚插入进来的,让用户感觉很魔幻,感觉出现了幻觉,这就叫幻读。
事务隔离级别
SQL 标准定义了四种隔离级别,MySQL 全都支持。这四种隔离级别分别是:
- 读未提交(READ UNCOMMITTED)
- 读提交 (READ COMMITTED)
- 可重复读 (REPEATABLE READ)
- 串行化 (SERIALIZABLE)
从上往下,隔离强度逐渐增强,性能逐渐变差。采用哪种隔离级别要根据系统需求权衡决定,其中,可重复读是 MySQL 的默认级别。
事务隔离其实就是为了解决上面提到的脏读、不可重复读、幻读这几个问题,下面展示了 4 种隔离级别对这三个问题的解决程度。
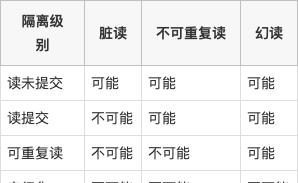
只有串行化的隔离级别解决了全部这 3 个问题,其他的 3 个隔离级别都有缺陷。mysql中可重复读解决了幻读问题
一探究竟
下面,我们来一一分析这 4 种隔离级别到底是怎么个意思。
如何设置隔离级别
我们可以通过以下语句查看当前数据库的隔离级别,通过下面语句可以看出我使用的 MySQL 的隔离级别是 REPEATABLE-READ,也就是可重复读,这也是 MySQL 的默认级别。

稍后,我们要修改数据库的隔离级别,所以先了解一下具体的修改方式。
修改隔离级别的语句是:set [作用域] transaction isolation level [事务隔离级别],
SET [SESSION | GLOBAL] TRANSACTION ISOLATION LEVEL {READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ | SERIALIZABLE}。
其中作用于可以是 SESSION 或者 GLOBAL,GLOBAL 是全局的,而 SESSION 只针对当前回话窗口。隔离级别是 {READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ | SERIALIZABLE} 这四种,不区分大小写。
比如下面这个语句的意思是设置全局隔离级别为读提交级别。
mysql> set global transaction isolation level read committed;
MySQL 中执行事务
事务的执行过程如下,以 begin 或者 start transaction 开始,然后执行一系列操作,最后要执行 commit 操作,事务才算结束。当然,如果进行回滚操作(rollback),事务也会结束。
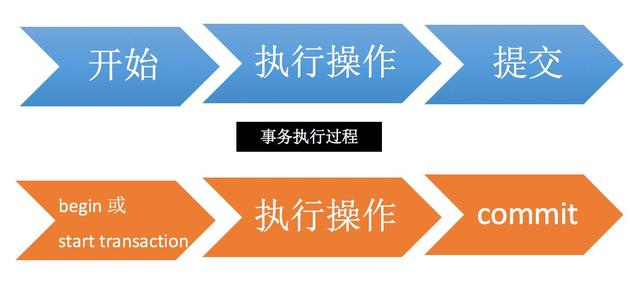
需要注意的是,begin 命令并不代表事务的开始,事务开始于 begin 命令之后的第一条语句执行的时候。例如下面示例中,select * from xxx 才是事务的开始,

另外,通过以下语句可以查询当前有多少事务正在运行。
select * from information_schema.innodb_trx;
好了,重点来了,开始分析这几个隔离级别了。
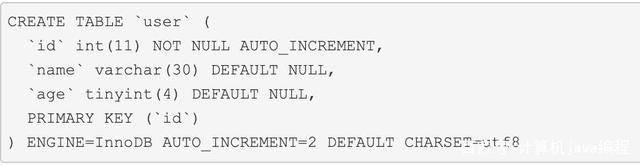
接下来我会用一张表来做一下验证,表结构简单如下:
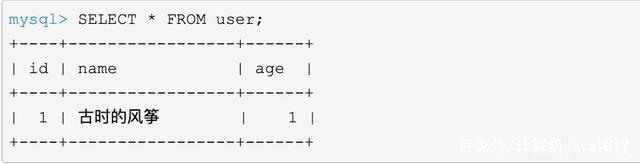
初始只有一条记录:
读未提交
MySQL 事务隔离其实是依靠锁来实现的,加锁自然会带来性能的损失。而读未提交隔离级别是不加锁的,所以它的性能是最好的,没有加锁、解锁带来的性能开销。但有利就有弊,这基本上就相当于裸奔啊,所以它连脏读的问题都没办法解决。
任何事务对数据的修改都会第一时间暴露给其他事务,即使事务还没有提交。
下面来做个简单实验验证一下,首先设置全局隔离级别为读未提交。
set global transaction isolation level read uncommitted;
设置完成后,只对之后新起的 session 才起作用,对已经启动 session 无效。如果用 shell 客户端那就要重新连接 MySQL,如果用 Navicat 那就要创建新的查询窗口。
启动两个事务,分别为事务A和事务B,在事务A中使用 update 语句,修改 age 的值为10,初始是1 ,在执行完 update 语句之后,在事务B中查询 user 表,会看到 age 的值已经是 10 了,这时候事务A还没有提交,而此时事务B有可能拿着已经修改过的 age=10 去进行其他操作了。在事务B进行操作的过程中,很有可能事务A由于某些原因,进行了事务回滚操作,那其实事务B得到的就是脏数据了,拿着脏数据去进行其他的计算,那结果肯定也是有问题的。
顺着时间轴往表示两事务中操作的执行顺序,重点看图中 age 字段的值。
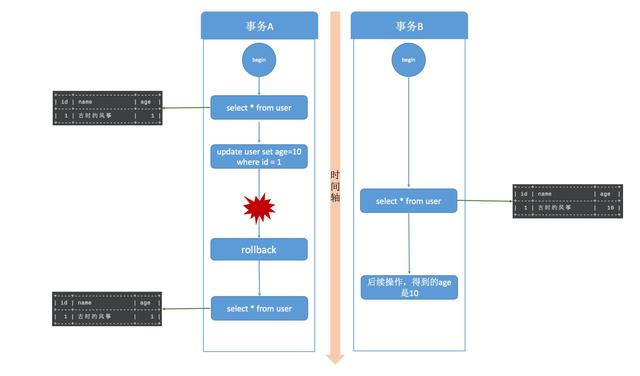
读未提交,其实就是可以读到其他事务未提交的数据,但没有办法保证你读到的数据最终一定是提交后的数据,如果中间发生回滚,那就会出现脏数据问题,读未提交没办法解决脏数据问题。更别提可重复读和幻读了,想都不要想。
读提交
既然读未提交没办法解决脏数据问题,那么就有了读提交。读提交就是一个事务只能读到其他事务已经提交过的数据,也就是其他事务调用 commit 命令之后的数据。那脏数据问题迎刃而解了。
读提交事务隔离级别是大多数流行数据库的默认事务隔离界别,比如 Oracle,但是不是 MySQL 的默认隔离界别。
我们继续来做一下验证,首先把事务隔离级别改为读提交级别。
set global transaction isolation level read committed;
之后需要重新打开新的 session 窗口,也就是新的 shell 窗口才可以。
同样开启事务A和事务B两个事务,在事务A中使用 update 语句将 id=1 的记录行 age 字段改为 10。此时,在事务B中使用 select 语句进行查询,我们发现在事务A提交之前,事务B中查询到的记录 age 一直是1,直到事务A提交,此时在事务B中 select 查询,发现 age 的值已经是 10 了。
这就出现了一个问题,在同一事务中(本例中的事务B),事务的不同时刻同样的查询条件,查询出来的记录内容是不一样的,事务A的提交影响了事务B的查询结果,这就是不可重复读,也就是读提交隔离级别。
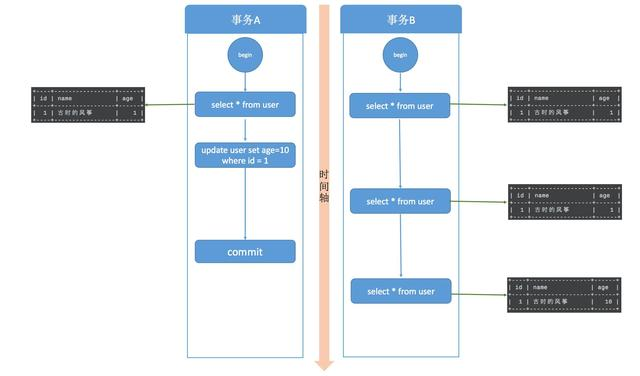
每个 select 语句都有自己的一份快照,而不是一个事务一份,所以在不同的时刻,查询出来的数据可能是不一致的。
读提交解决了脏读的问题,但是无法做到可重复读,也没办法解决幻读。
可重复读
可重复是对比不可重复而言的,上面说不可重复读是指同一事物不同时刻读到的数据值可能不一致。而可重复读是指,事务不会读到其他事务对已有数据的修改,及时其他事务已提交,也就是说,事务开始时读到的已有数据是什么,在事务提交前的任意时刻,这些数据的值都是一样的。但是,对于其他事务新插入的数据是可以读到的,这也就引发了幻读问题。
同样的,需改全局隔离级别为可重复读级别。
set global transaction isolation level repeatable read;
在这个隔离级别下,启动两个事务,两个事务同时开启。
首先看一下可重复读的效果,事务A启动后修改了数据,并且在事务B之前提交,事务B在事务开始和事务A提交之后两个时间节点都读取的数据相同,已经可以看出可重复读的效果。
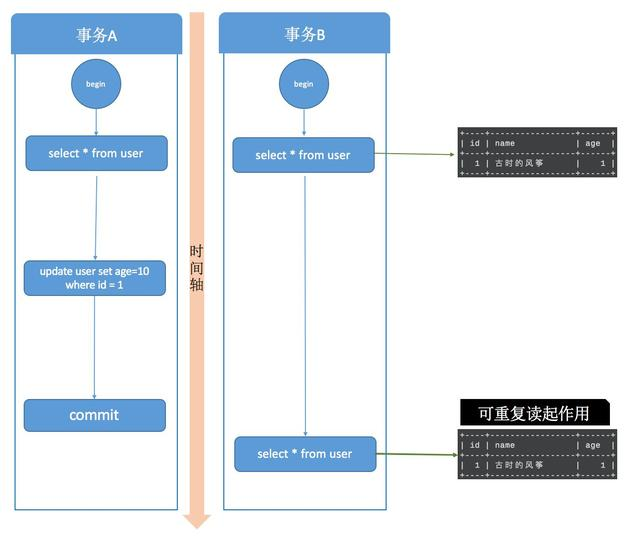
可重复读做到了,这只是针对已有行的更改操作有效,但是对于新插入的行记录,就没这么幸运了,幻读就这么产生了。我们看一下这个过程:
事务A开始后,执行 update 操作,将 age = 1 的记录的 name 改为“风筝2号”;
事务B开始后,在事务执行完 update 后,执行 insert 操作,插入记录 age =1,name = 古时的风筝,这和事务A修改的那条记录值相同,然后提交。
事务B提交后,事务A中执行 select,查询 age=1 的数据,这时,会发现多了一行,并且发现还有一条 name = 古时的风筝,age = 1 的记录,这其实就是事务B刚刚插入的,这就是幻读。
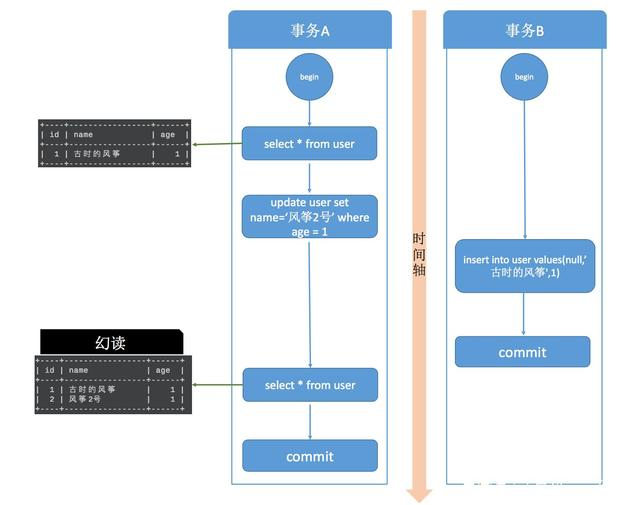
要说明的是,当你在 MySQL 中测试幻读的时候,并不会出现上图的结果,幻读并没有发生,MySQL 的可重复读隔离级别其实解决了幻读问题,这会在后面的内容说明
串行化
串行化是4种事务隔离级别中隔离效果最好的,解决了脏读、可重复读、幻读的问题,但是效果最差,它将事务的执行变为顺序执行,与其他三个隔离级别相比,它就相当于单线程,后一个事务的执行必须等待前一个事务结束。
MySQL 中是如何实现事务隔离的
首先说读未提交,它是性能最好,也可以说它是最野蛮的方式,因为它压根儿就不加锁,所以根本谈不上什么隔离效果,可以理解为没有隔离。
再来说串行化。读的时候加共享锁,也就是其他事务可以并发读,但是不能写。写的时候加排它锁,其他事务不能并发写也不能并发读。
最后说读提交和可重复读。这两种隔离级别是比较复杂的,既要允许一定的并发,又想要兼顾的解决问题。
实现可重复读
1、原理
MySQL默认的隔离级别是可重复读,即:事务A在读到一条数据之后,此时事务B对该数据进行了修改并提交,那么事务A再读该数据,读到的还是原来的内容。 那么MySQL可重复读是如何实现的呢?
使用的的一种叫MVCC的控制方式 ,即Mutil-Version Concurrency Control,多版本并发控制,类似于乐观锁的一种实现方式
实现方式:
InnoDB在每行记录后面保存两个隐藏的列来,分别保存了这个行的创建时间和行的删除时间。这里存储的并不是实际的时间值,而是系统版本号,当数据被修改时,版本号加1
在读取事务开始时,系统会给当前读事务一个版本号,事务会读取版本号<=当前版本号的数据
此时如果其他写事务修改了这条数据,那么这条数据的版本号就会加1,从而比当前读事务的版本号高,读事务自然而然的就读不到更新后的数据了
2、增删改查
假设初始版本号为1:
INSERT
insert into user (id,name) values (1,'Tom');
下面模拟一下文章开头的场景:
SELECT (事务A)
select * from user where id = 1;
此时读到的版本号为1
UPDATE(事务B)
update user set name = 'Jerry' where id = 1;
在更新操作的时候,该事务的版本号在原来的基础上加1,所以版本号为2。
先将要更新的这条数据标记为已删除,并且删除的版本号是当前事务的版本号,然后插入一行新的记录

SELECT (事务A)
此时事务A再重新读数据:
select * from user where id = 1;
由于事务A一直没提交,所以此时读到的版本号还是为1,所以读到的还是Tom这条数据,也就是可重复读
DELETE
delete from user where id = 1;在删除操作的时候,该事务的版本号在原来的基础上加1,所以版本号为3删除时,将当前版本号作为删除版本号
MVCC逻辑流程-查询
此时,数据查询规则如下:
查找数据行版本号早于当前事务版本号的数据行记录
也就是说,数据行的版本号要小于或等于当前是事务的系统版本号,这样也就确保了读取到的数据是当前事务开始前已经存在的数据,或者是自身事务改变过的数据
查找删除版本号要么为NULL,要么大于当前事务版本号的记录
这样确保查询出来的数据行记录在事务开启之前没有被删除
如何解决幻读
很明显可重复读的隔离级别没有办法彻底的解决幻读的问题,如果我们的项目中需要解决幻读的话也有两个办法:
使用串行化读的隔离级别
MVCC+next-key locks:next-key locks由record locks(索引加锁/行锁) 和 gap locks(间隙锁,每次锁住的不光是需要使用的数据,还会锁住这些数据附近的数据)的结合,next-key lock 会锁定范围和自身行,比如select…where id<6,锁定的是小于6的行和等于6的行
Next-Key Lock即在事务中select时使用如下方法加锁,这样在另一个事务对范围内的数据进行修改时就会阻塞:
select * from table where id<6 lock in share mode;--共享锁select * from table where id<6 for update;--排他锁实际上很多的项目中是不会使用到上面的两种方法的,串行化读的性能太差,而且其实幻读很多时候是我们完全可以接受的。
总结
MySQL 的 InnoDB 引擎才支持事务,其中可重复读是默认的隔离级别。
读未提交和串行化基本上是不需要考虑的隔离级别,前者不加锁限制,后者相当于单线程执行,效率太差。
读提交解决了脏读问题,行锁解决了并发更新的问题。并且 MySQL 在可重复读级别解决了幻读问题,是通过行锁和间隙锁的组合 Next-Key 锁实现的。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!
· 零经验选手,Compose 一天开发一款小游戏!
2018-08-28 MATLAB实现回归分析
2018-08-28 MATLAB进行假设检验
2018-08-28 用MATLAB进行数据分析