图神经网络学习
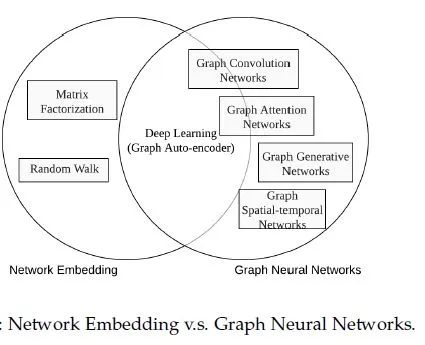
图神经网络划分为五大类别,分别是:图卷积网络(Graph Convolution Networks,GCN)、 图注意力网络(Graph Attention Networks)、图自编码器( Graph Autoencoders)、图生成网络( Graph Generative Networks) 和图时空网络(Graph Spatial-temporal Networks)。
GNN综述:
图神经网络(Graph Neural Networks,GNN)综述
万字长文带你入门 GCN(十分推荐先看这个入门)
图信号理论以及谱域图卷积
从图(Graph)到图卷积(Graph Convolution): 漫谈图神经网络 (一)
GNN的理论基础是不动点(the fixed point)理论,这里的不动点理论专指巴拿赫不动点定理(Banach's Fixed Point Theorem)。首先我们用
表示若干个
堆叠得到的一个函数,也称为全局更新函数,那么图上所有结点的状态更新公式可以写成:
不动点定理指的就是,不论
是什么,只要
经过不断迭代都会收敛到某一个固定的点,我们称之为不动点。
本文也介绍了基于循环图神经网络的两种重要模型。
GCN:
从图(Graph)到图卷积(Graph Convolution): 漫谈图神经网络 (二)
在本篇中,我们将着大量笔墨介绍图卷积神经网络中的卷积操作。接下来,我们将首先介绍一下图卷积神经网络的大概框架,借此说明它与基于循环的图神经网络的区别。接着,我们将从头开始为读者介绍卷积的基本概念,以及其在物理模型中的涵义。最后,我们将详细地介绍两种不同的卷积操作,分别为空域卷积和时域卷积,与其对应的经典模型。
从图(Graph)到图卷积(Graph Convolution): 漫谈图神经网络 (三)
前面两篇分别介绍了基于循环的图神经网络和基于卷积的图神经网络,那么在本篇中,我们则主要关注在得到了各个结点的表示后,如何生成整个图的表示。其实之前我们也举了一些例子,比如最朴素的方法,例如图上所有结点的表示取个均值,即可得到图的表示。那有没有更好的方法呢,它们各自的优点和缺点又是什么呢,本篇主要对上面这两个问题做一点探讨。篇幅不多,理论也不艰深,请读者放心地看。
GAT:
GRAPH ATTENTION NETWORKS
《Graph Attention Networks》阅读笔记
图注意力网络(GAT) ICLR2018, Graph Attention Network论文详解
GraphSage
[论文笔记]:GraphSAGE:Inductive Representation Learning on Large Graphs 论文详解 NIPS 2017
现存的方法需要图中所有的顶点在训练embedding的时候都出现;这些前人的方法本质上是transductive,不能自然地泛化到未见过的顶点。
文中提出了GraphSAGE,是一个inductive的框架,可以利用顶点特征信息(比如文本属性)来高效地为没有见过的顶点生成embedding。
GraphSAGE是为了学习一种节点表示方法,即如何通过从一个顶点的局部邻居采样并聚合顶点特征,而不是为每个顶点训练单独的embedding。
这个算法在三个inductive顶点分类benchmark上超越了那些很强的baseline。文中基于citation和Reddit帖子数据的信息图中对未见过的顶点分类,实验表明使用一个PPI(protein-protein interactions)多图数据集,算法可以泛化到完全未见过的图上。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号