java集合总结
一:Java集合产生的原因
一方面,面向对 象语言对事物的体现 都是以对象的形式,为了方便对多 个对象的操作,就要对对象进行存储。 另-方面,使用Array存储对 象方面具有一些弊端,大小不能动态改变,而Java 集合就像一 种容器,可以动态地把多 个对象的引用放入容器中。所以,Java集合类可以用于存储数量不等的多个对象,还可用于保存具有映射关系的关联数组。
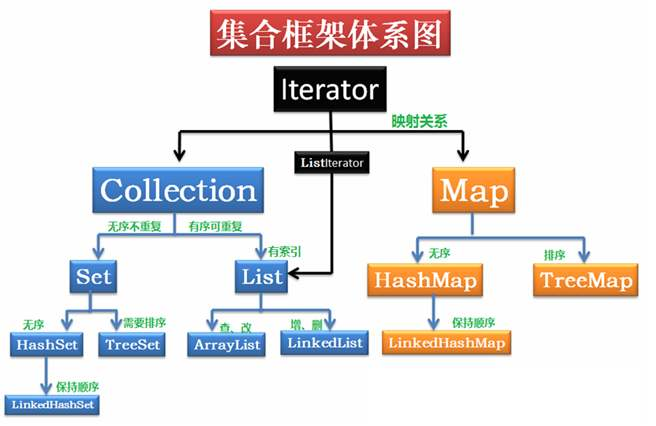
二:集合架构体系图
●Java集合可分为Collection和Map两种体系
➢Collection接口:
➢Set:元素无序、不可重复的集合--类似高中的"集合”
➢List:元素有序,可重复的集合--”动态”数组
➢Map接口:具有映射关系“key-value对” 的集合--类似于高中的“函数”y=f(x) (x1,y1) (x2,y2)
三:Collection接口
●Collection接口是List、Set 和Queue接口的父接口,该接口里定义的方法既可用于操作Set集合,也可用于操作List和Queue集合。
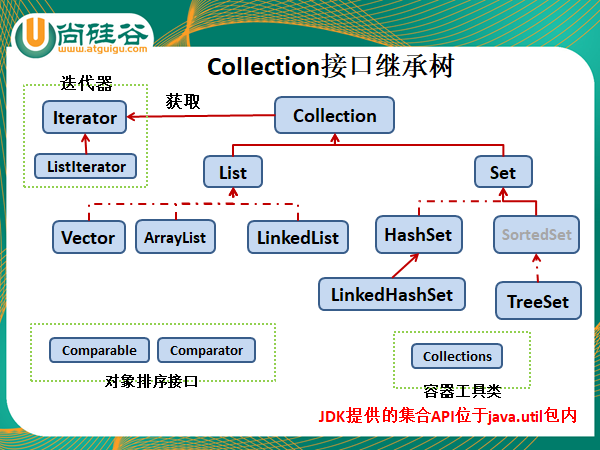
3.1:List接口
Java中数组用来存储数据的局限性,List集合类中元素有序、且可重复,集合中的每个元素都有其对应的顺序索引。List容器中的元素都对应一个整数型的序号记载其在容器中的位置,
可以根据序号存取容器中的元素。JDK API中List接口的实现类常用的有: ArrayList、 LinkedList和Vector。

list集合中的元素或对象(主要是自己的实现类)要重写equals方法,因为equals方法是判断两个对象相等的条件,不重写可能导致相等的对象无法判断相等。
1 package Set; 2 import org.junit.Test; 3 4 import java.util.*; 5 6 /* 7 * 1.存储对象可以考虑:①数组 ②集合 8 * 2.数组存储对象的特点:Student[] stu = new Student[20]; stu[0] = new Student();.... 9 * >弊端:①一旦创建,其长度不可变。②真实的数组存放的对象的个数是不可知。 10 * 3.集合 11 * Collection接口 12 * |------List接口:存储有序的,可以重复的元素 13 * |------ArrayList(主要的实现类)、LinkedList(对于频繁的插入、删除操作)、Vector(古老的实现类、线程安全的) 14 * |------Set接口:存储无序的,不可重复的元素 15 * |------HashSet、LinkedHashSet、TreeSet 16 * Map接口:存储“键-值”对的数据 17 * |-----HashMap、LinkedHashMap、TreeMap、Hashtable(子类:Properties) 18 */ 19 public class CollectionTest { 20 @Test 21 public void testCollection1() { 22 //size()方法判断集合的大小,add(Object obj)用来向集合添加元素,addAll(Collection coll),将一个集合中的所有元素添加到另一个集合里面 23 // isEmpty()用来判断集合是否为空,clear()用来清空集合里的元素,contains用来判断集合是否包含指定的obj元素,对于自定义类对象要重写equals作为判断的依据 24 //containsAll(Collection coll):判断当前集合中是否包含coll中所有的元素,retainAll(Collection coll):求当前集合与coll的共有的元素,返回给当前集合 25 //equals判断两个集合中元素是否相同,toArray()变成数组,Arrays.toList()数组变成集合,集合可以通过.iterator()来进行遍历元素,包含next和hasnext方法,也可以增强for循环 26 Collection coll = new ArrayList(); 27 coll.add(1); 28 coll.add("hello"); 29 coll.add(new Person("nihao",12));//添加元素 30 System.out.println(coll.size());//判断大小, 31 coll.add(1); 32 System.out.println(coll.size());//重复的元素可以添加 33 ArrayList arrayList = new ArrayList(); 34 arrayList.add(10); 35 coll.addAll(arrayList);//添加一个集合 36 System.out.println(coll.isEmpty());//判断是否为空 37 boolean b = (boolean) arrayList.remove(Integer.valueOf(10));//删除元素10,注意数字是表示按照下标进行删除,包装类则是安装元素进行删除 38 System.out.println(b); 39 System.out.println(arrayList.isEmpty());//现在为空 40 //coll.clear();//清空元素, 41 //System.out.println(coll); 42 System.out.println(coll.contains(Integer.valueOf(1)));//包含一个元素 43 arrayList.add(1); 44 System.out.println(coll.containsAll(arrayList));//包含一个集合 45 System.out.println(coll.retainAll(arrayList));//求交集 46 System.out.println(coll.equals(arrayList));//判断两个集合是否相同 47 System.out.println(arrayList.hashCode());//集合的hashcode值 48 arrayList.add(2); 49 System.out.println(arrayList.hashCode());//hashcode是对所有元素计算的到的。 50 Object []obj = coll.toArray();//集合变成数组 51 for (int i = 0; i < obj.length; i++) { 52 System.out.println(obj[i]); 53 } 54 int[] a = {1,2,3}; 55 List<int[]> ints = Arrays.asList(a);//数组变成集合 56 Iterator iterator = ints.iterator(); 57 while (iterator.hasNext()){ 58 System.out.println(iterator.next()); 59 } 60 for (Object ob:coll){ 61 System.out.println(ob); 62 } 63 } 64 //ArrayList:List的主要实现类 65 /* 66 * List中相对于Collection,新增加的方法 67 * void add(int index, Object ele):在指定的索引位置index添加元素ele 68 boolean addAll(int index, Collection eles) 69 Object get(int index):获取指定索引的元素 70 Object remove(int index):删除指定索引位置的元素 71 Object set(int index, Object ele):设置指定索引位置的元素为ele 72 int indexOf(Object obj):返回obj在集合中首次出现的位置。没有的话,返回-1 73 int lastIndexOf(Object obj):返回obj在集合中最后一次出现的位置.没有的话,返回-1 74 List subList(int fromIndex, int toIndex):返回从fromIndex到toIndex结束的左闭右开一个子list 75 76 List常用的方法:增(add(Object obj)) 删(remove) 改(set(int index,Object obj)) 77 查(get(int index)) 插(add(int index, Object ele)) 长度(size()) 78 */ 79 @Test 80 public void testArrayList(){ 81 ArrayList ints = new ArrayList(); 82 ints.add(1); 83 ints.add("a"); 84 Collection arrayList = new ArrayList(); 85 arrayList.add("a"); 86 arrayList.add(1); 87 System.out.println(arrayList.equals(ints));//判断相等不仅看元素,还要看顺序, 88 System.out.println(arrayList.hashCode());//一般hashcode除了要看内容,还要看顺序,因此若hashcode不相等,equals一般也不想等,互等价 89 System.out.println(ints.hashCode()); 90 ints.addAll(0,arrayList); 91 System.out.println(ints); 92 System.out.println(ints.get(0)); 93 System.out.println(ints.remove(0));//删除指定位置的元素 94 System.out.println(ints.indexOf("a"));//首次出现的位置, 95 System.out.println(ints.lastIndexOf("a"));//最后一次出现的位置 96 System.out.println(ints.subList(0,2));//返回左闭右开的区间的内容 97 System.out.println(ints.set(0,"b"));//指定位置修改 98 System.out.println(ints); 99 100 } 101 102 }
3.2 set接口

set集合中的元素或对象(主要是自己的实现类)要重写equals方法,因为equals方法是判断两个对象相等的条件,不重写可能导致相等的对象无法判断相等,
还要重写hashcode方法,否则会导致所有的对象的hashcode的值都相等,且只能输出一个对象的值。


linkedhashset要维护指针,所以插入的效率要低一些,但是频繁遍历的效果要好于hashset

要求是同一个类的才能添加到同一个treeset,才能按照统一的标准进行遍历。
1 package Set; 2 3 import org.junit.Test; 4 5 import java.util.*; 6 7 public class Set { 8 @Test 9 public void test(){//测试hashset 10 HashSet hashSet = new HashSet(); 11 hashSet.add(123); 12 hashSet.add(222); 13 hashSet.add("BB"); 14 System.out.println(hashSet);//存储无顺序,输出也无顺序。 15 work work1 = new work("ll",10); 16 work work2 = new work("ll",10); 17 hashSet.add(work1); 18 hashSet.add(work2); 19 System.out.println(work1.hashCode()); 20 System.out.println(work2.hashCode()); 21 System.out.println(hashSet);//对类对象,只有重写hashCode方法和equals方法后,生成的对象的hash值才可以相同,才能保证set集合的无重复性 22 } 23 /* 24 * LinkedHashSet:使用链表维护了一个添加进集合中的顺序。导致当我们遍历LinkedHashSet集合 25 * 元素时,是按照添加进去的顺序遍历的! 26 * 27 * LinkedHashSet插入性能略低于 HashSet,但在迭代访问 Set 里的全部元素时有很好的性能。 28 */ 29 @Test 30 public void test2(){//测试LinkedHashSet() 31 LinkedHashSet linkedHashSet = new LinkedHashSet(); 32 linkedHashSet.add(1); 33 linkedHashSet.add(2); 34 linkedHashSet.add(null); 35 Iterator iterator1 = linkedHashSet.iterator(); 36 while (iterator1.hasNext())//因为测试LinkedHashSet在hashset的基础上添加了链表,因此所有添加的元素连接起来,遍历有序,这是主要的不同 37 { 38 System.out.println(iterator1.next()); 39 } 40 41 } 42 @Test//自然排序 43 public void test3(){//在people类里面重写 44 TreeSet set = new TreeSet(); 45 set.add(new work("liulei",16)); 46 set.add(new work("ww",12)); 47 set.add(new work("cc",13)); 48 for (Object str1:set){ 49 System.out.println(str1); 50 } 51 52 } 53 @Test 54 public void test4(){//因为只有相同类的两个实例才会比较大小,所以向 TreeSet 中添加的应该是同一个类的对象 55 56 Comparator com = new Comparator() {//定制排序 57 @Override 58 public int compare(Object o1, Object o2) { 59 if(o1 instanceof work && o2 instanceof work){ 60 work c1 = (work) o1; 61 work c2 = (work) o2; 62 int i = c1.getAge().compareTo(c2.getAge());//小于负值大于正值 63 if(i==0){//相等,继续比较 64 return c1.getName().compareTo(c2.getName()); 65 } 66 return i; 67 } 68 return 0; 69 } 70 }; 71 TreeSet set = new TreeSet(); 72 set.add(new work("liulei",16)); 73 set.add(new work("ww",12)); 74 set.add(new work("cc",13)); 75 for (Object str1:set){ 76 System.out.println(str1); 77 } 78 79 } 80 81 }
对于自然排序,people里面实验Comparable,重写compareTo方法


package Set; public class Person implements Comparable{ private String name; private Integer age; public String getName() { return name; } public void setName(String name) { this.name = name; } public Integer getAge() { return age; } public void setAge(Integer age) { this.age = age; } public Person() { super(); } public Person(String name, Integer age) { super(); this.name = name; this.age = age; } @Override public String toString() { return "Person [name=" + name + ", age=" + age + "]"; } //static int init = 1000; @Override public int hashCode() {//return age.hashCode() + name.hashCode();û�����Ľ�׳�Ժá� final int prime = 31; int result = 1; result = prime * result + ((age == null) ? 0 : age.hashCode()); result = prime * result + ((name == null) ? 0 : name.hashCode()); return result; //return init++;//���������� } @Override public boolean equals(Object obj) { if (this == obj) return true; if (obj == null) return false; if (getClass() != obj.getClass()) return false; Person other = (Person) obj; if (age == null) { if (other.age != null) return false; } else if (!age.equals(other.age)) return false; if (name == null) { if (other.name != null) return false; } else if (!name.equals(other.name)) return false; return true; } //����TreeSet�����Person��Ķ���ʱ�����ݴ˷�����ȷ�������ĸ��������С� @Override public int compareTo(Object o) { if(o instanceof Person){ Person p = (Person)o; //return this.name.compareTo(p.name); //return -this.age.compareTo(p.age); int i = this.age.compareTo(p.age); if(i == 0){ return this.name.compareTo(p.name); }else{ return i; } } return 0; } }
自然排序
1 @Override 2 public int compareTo(Object o) { 3 if(o instanceof Person){ 4 Person p = (Person)o; 5 //return this.name.compareTo(p.name); 6 //return -this.age.compareTo(p.age); 7 int i = this.age.compareTo(p.age); 8 if(i == 0){ 9 return this.name.compareTo(p.name); 10 }else{ 11 return i; 12 } 13 } 14 return 0; 15 }
定制排序
Comparator com = new Comparator() {//定制排序 @Override public int compare(Object o1, Object o2) { if(o1 instanceof work && o2 instanceof work){ work c1 = (work) o1; work c2 = (work) o2; int i = c1.getAge().compareTo(c2.getAge());//小于负值大于正值 if(i==0){//相等,继续比较 return c1.getName().compareTo(c2.getName()); } return i; } return 0; } };
3.3.Queue
Queue接口与List、Set同一级别,都是继承了Collection接口。LinkedList实现了Queue接 口。Queue接口窄化了对LinkedList的方法的访问权限(即在方法中的参数类型如果是Queue时,就完全只能访问Queue接口所定义的方法 了,而不能直接访问 LinkedList的非Queue的方法),以使得只有恰当的方法才可以使用。BlockingQueue 继承了Queue接口。队列是一种先进先出的数据结构,元素在队列末尾添加,在队列头部删除。Queue接口扩展自Collection,并提供插入、提取、检验等操作。上图中,方法offer表示向队列添加一个元素,poll()与remove()方法都是移除队列头部的元素,两者的区别在于如果队列为空,那么poll()返回的是null,而remove()会抛出一个异常。方法element()与peek()主要是获取头部元素,不删除。接口Deque,是一个扩展自Queue的双端队列,它支持在两端插入和删除元素,因为LinkedList类实现了Deque接口,所以通常我们可以使用LinkedList来创建一个队列。PriorityQueue类实现了一个优先队列,优先队列中元素被赋予优先级,拥有高优先级的先被删除。





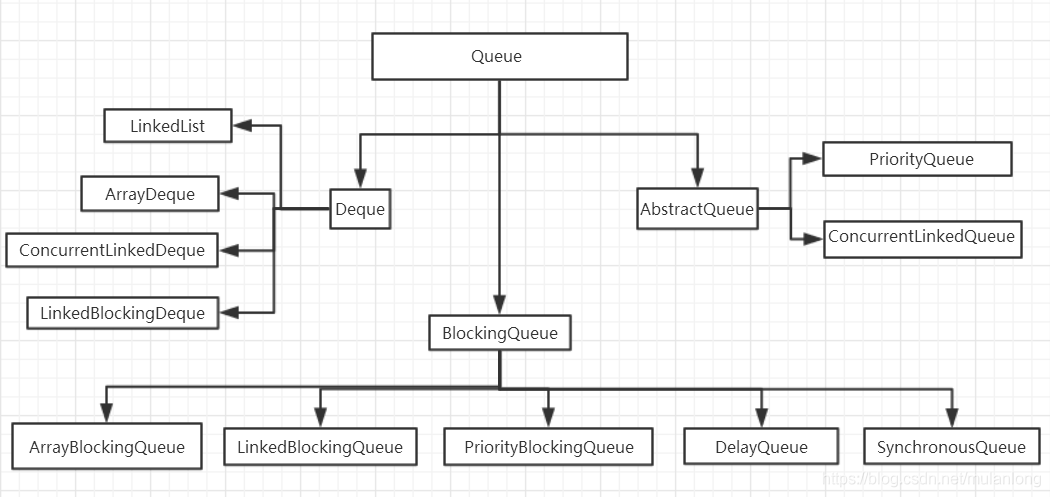
如图所示,在并发队列上,JDK提供了2套实现,一个是以ConcurrentLinkedQueue为代表的高性能非阻塞队列,一个是以BlockingQueue接口为代表的阻塞队列,无论哪种都继承自Queue。使用阻塞算法的队列可以用一个锁(入队和出队用同一把锁)或两个锁(入队和出队用不同的锁)等方式来实现,而非阻塞的实现方式则可以使用循环CAS的方式来实现,下面我们来一一分析。
ConcurrentLinkedQueue
一个适用于高并发场景下的队列,通过无锁的方式(CAS+volatile),实现了高并发下的高性能,通常ConcurrentLinkedQueue的性能好于BlockingQueue。
它是一个基于链接节点的×××线程安全队列,遵循先进先出的原则,头是最先加入的,尾是最近加入的,不允许加入null元素。
注意add()/offer()都是加入元素的方法,这里没有区别;poll()/peek()是取出头元素的方法,区别点在于poll会删除元素,而peek不会。
要特别注意到由于它的非阻塞性,并不像其他普通集合那样,获取队列的SIZE的方法并不是常量时间的花费,而是O(N)的,因此我们应该尽可能避免使用size()方法,可以考虑使用isEmpty()代替。
虽然使用到了CAS+VOLATILE的机制避免了锁,但是我们要明白的是,这只是保证单个操作,如peek()的安全,但是多个操作如果想保证的话,需要使用锁机制来达到同步的效果。
BlockingQueue API
入队:
offer(E e):如果队列没满,立即返回true; 如果队列满了,立即返回false-->不阻塞
put(E e):如果队列满了,一直阻塞,直到数组不满了或者线程被中断-->阻塞
offer(E e, long timeout, TimeUnit unit):在队尾插入一个元素,,如果数组已满,则进入等待,直到等待时间超时
出队:
poll():非阻塞拿数据,立即返回
take():阻塞拿数据
poll(long timeout, TimeUnit unit):带有一定超时时间的poll拿取数据
ArrayBlockingQueue
基于数组的阻塞队列实现,在其内部维护了一个定长数组,以便缓存队列中的数据对象,由于ArrayBlockingQueue内部只有一个锁对象(ReentrantLock),因此读写没有实现分离,也就意味着生产消费不能完全并行。由于长度需要定义,因此也叫有界队列。
LinkedBlockingQueue
基于链表的阻塞队列实现,同ArrayBlockingQueue类似,其内部也维持着一个数据缓冲队列(链表构成)。
LinkedBlockingQueue之所以较ArrayBlockingQueue更加高效的处理并发数据,是因为内部实现采用了2把锁,也就是实现了入队、出队分别上锁,即读写分离,从而生产者、消费者完全到达了并行。
无需定义长度,也叫×××队列。当然不定义长度时,需要注意下生产者的速度和消费者的速度,因为默认情况下队列长度是Integer.MAX_VALUE。
SynchronousQueue
一个没有缓冲的队列,生产者生产的数据会直接被消费者获取到并消费。它是一个轻量级的阻塞队列,因为不具备容量,在用法上,只能是一个线程阻塞着取元素,等待另一个线程往队列里面放入一个元素,然后会被等待着的线程立即取走,其实就是实现了线程间的轻量级的单元素交换。SynchronousQueue直接使用CAS实现线程的安全访问。
PriorityBlockingQueue
基于优先级的阻塞队列(优先级的判断通过构造函数传入的Compator对象决定,也就是传入队列中对象必须实现Comparable接口)。
在实现PriorityBlockingQueue时,内部控制线程同步的锁采用的是公平锁,也是一个×××的队列。
通俗的来说,不是先进先出的队列了,而是谁的优先级低谁先出去。那么可以思考下,是否每次add/offer都会进行一次排序呢?我们是否需要按照优先级进行全排序呢?实际上,可以大致看一看add/take方法,会了解到PriorityBlockingQueue的设计思想:在add时,并不进行排序处理,当进行take时,选择优先级最小的拿出来而已,这样既避免了在add时花费时间排序,又在take时节省了时间,因为并没有全排序,仅仅是挑选了一个优先级低的元素而已。
DelayQueue
带有延迟时间的Queue,其中的元素只有当指定的延迟时间到了,才能从队列中获取到该元素。队列中的元素必须实现Delayed接口,没有大小限制。本质上来说,是借助于PriorityBlockingQueue来实现的,以延迟时间作为优先级。延迟队列的应用场景很多,比如缓存超时的数据进行移除,任务超时处理,空闲连接的关闭等等。
四:Map接口

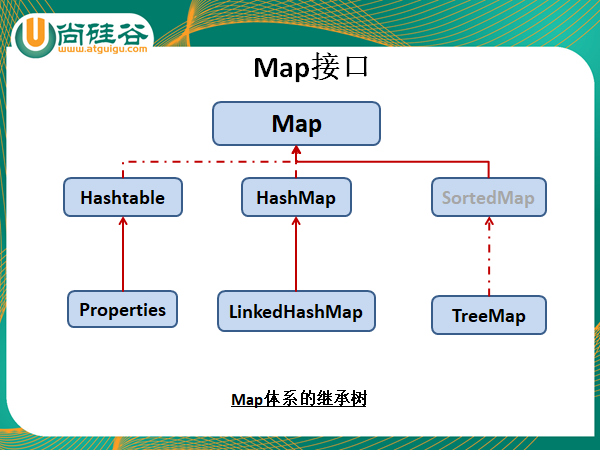
3.1 hashmap

3.2 Linkedhashmap

LinkedHashMap的概述: Map 接口的哈希表和链接列表实现,具有可预知的迭代顺序LinkedHashMap的特点: 底层的数据结构是链表和哈希表 元素有序 并且唯一
元素的有序性由链表数据结构保证 唯一性由 哈希表数据结构保证
Map集合的数据结构只和键有关
3.3 Treemap

TreeMap 键不允许插入null
TreeMap: 键的数据结构是红黑树,可保证键的排序和唯一性
排序分为自然排序和比较器排序
线程是不安全的效率比较高
TreeMap集合排序:
实现Comparable接口,重写CompareTo方法
使用比较器
3.4 Hashtable

3.5 properties

1 @Test 2 public void Test5() throws IOException { 3 Properties pros = new Properties(); 4 pros.load(new FileInputStream(new File("D:/config.txt"))); 5 String user = pros.getProperty("user"); 6 System.out.println(user); 7 }
五:Collections工具类


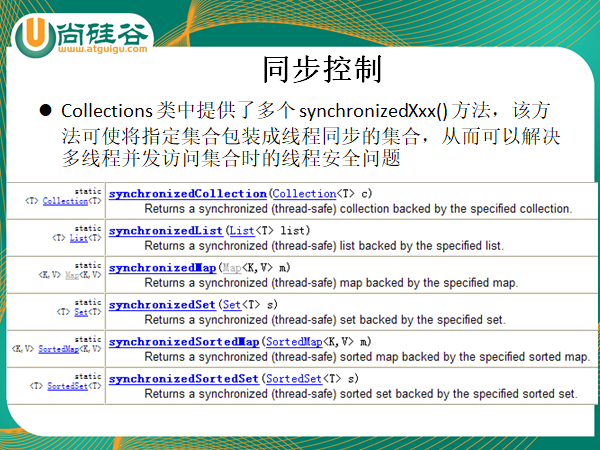
1 package com.atguigu.java; 2 3 import java.util.ArrayList; 4 import java.util.Arrays; 5 import java.util.Collections; 6 import java.util.List; 7 8 import org.junit.Test; 9 10 /* 11 * 操作Collection以及Map的工具类:Collections 12 * 13 * 面试题:区分Collection与Collections 14 * 15 */ 16 public class TestCollections { 17 /* 18 * Object max(Collection):根据元素的自然顺序,返回给定集合中的最大元素 19 Object max(Collection,Comparator):根据 Comparator 指定的顺序,返回给定集合中的最大元素 20 Object min(Collection) 21 Object min(Collection,Comparator) 22 int frequency(Collection,Object):返回指定集合中指定元素的出现次数 23 void copy(List dest,List src):将src中的内容复制到dest中 24 boolean replaceAll(List list,Object oldVal,Object newVal):使用新值替换 List 对象的所有旧值 25 26 */ 27 @Test 28 public void testCollections2(){ 29 List list = new ArrayList(); 30 list.add(123); 31 list.add(456); 32 list.add(12); 33 list.add(78); 34 list.add(456); 35 Object obj = Collections.max(list); 36 System.out.println(obj); 37 int count = Collections.frequency(list, 4567); 38 System.out.println(count); 39 //实现List的复制 40 //List list1 = new ArrayList();//错误的实现方式 41 List list1 = Arrays.asList(new Object[list.size()]); 42 Collections.copy(list1, list); 43 System.out.println(list1); 44 //通过如下的方法保证list的线程安全性。 45 List list2 = Collections.synchronizedList(list); 46 System.out.println(list2); 47 } 48 /* 49 * reverse(List):反转 List 中元素的顺序 50 shuffle(List):对 List 集合元素进行随机排序 51 sort(List):根据元素的自然顺序对指定 List 集合元素按升序排序 52 sort(List,Comparator):根据指定的 Comparator 产生的顺序对 List 集合元素进行排序 53 swap(List,int, int):将指定 list 集合中的 i 处元素和 j 处元素进行交换 54 55 */ 56 @Test 57 public void testCollections1(){ 58 List list = new ArrayList(); 59 list.add(123); 60 list.add(456); 61 list.add(12); 62 list.add(78); 63 System.out.println(list); 64 Collections.reverse(list); 65 System.out.println(list); 66 Collections.shuffle(list); 67 System.out.println(list); 68 Collections.sort(list); 69 System.out.println(list); 70 Collections.swap(list, 0, 2); 71 System.out.println(list); 72 } 73 }


 浙公网安备 33010602011771号
浙公网安备 33010602011771号