ElasticSearch学习笔记_1




具体的代码,在kibana实现
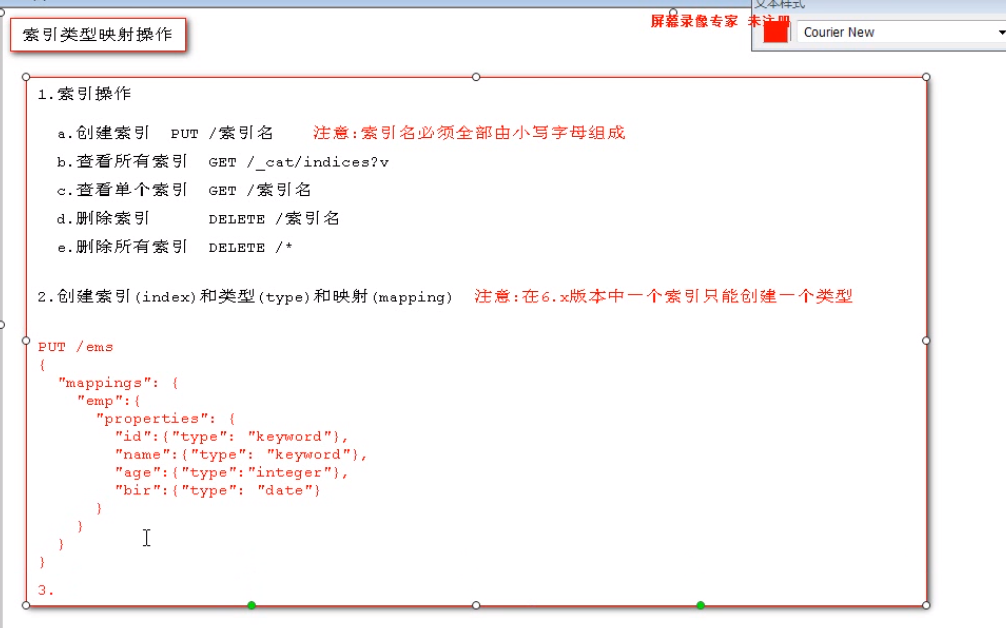
1 PUT /ems #建立索引 2 PUT /dangdang 3 GET /_cat/indices#查看所有索引 4 GET /dangdang 5 DELETE /dangdang#删除索引 6 DELETE /* #删除所有索引 7 8 PUT /ems1#设定索引,类型唯一为_doc可以省略 9 { 10 "mappings":{ 11 12 "properties":{ 13 "id":{"type":"keyword"}, 14 "name":{"type":"keyword"}, 15 "age":{"type":"integer"}, 16 "bir":{"type":"date"} 17 18 19 } 20 } 21 } 22 GET /ems1/_mapping#查看映射,在版本7中,类型唯一, 23 PUT /ems1/_doc/1#插入文档,一般用_id(前面的1)代替下面的id 24 { 25 "id":"12", 26 "name":"刘雷", 27 "age":12, 28 "bir":"1997-03-02" 29 } 30 GET /ems1/_doc/1 #查看指定文档类型默认为_doc, 31 POST /ems1/_doc/1#对原文档进行覆盖,不是更新,更新的话需要在后面指定update,不指定id会自动生成 32 { 33 "id":"12", 34 "name":"刘雷111", 35 "age":12, 36 "bir":"1997-03-02" 37 } 38 GET /ems1/_doc/1 39 PUT /ems1/_doc/2 40 { 41 "id":"12", 42 "name":"流泪", 43 "age":12, 44 "bir":"2002-12-12" 45 } 46 DELETE /ems1/_doc/1#删除 47 GET /ems1/#查看 48 POST /ems1/_doc/2/_update#在原有基础上更新 49 { 50 "doc":{ 51 "name": "哈哈" 52 } 53 } 54 POST /ems1/_doc/2/_update#添加新的数据time 55 { 56 "doc": { 57 "name":"哈哈", 58 "time":"16:40", 59 "num": 12 60 } 61 } 62 GET /ems1/_doc/2 63 64 POST /ems1/_doc/2/_update#对文档数字进行直接更新 65 { 66 "script":"ctx._source.num += 5" 67 } 68 GET /ems1/_doc/2 #num=17 69 PUT /ems1/_bulk#批量增加数据 70 {"index":{"_id":"3"}} 71 {"name":"liulei","age":23,"bir":"2020-12-12"} 72 {"index":{"_id":"4"}} 73 {"name":"liuya","age":13,"bir":"2020-12-12"} 74 GET /ems1/_doc/3 75 POST /ems1/_bulk#批量进行增加删除修改一起操作,更新指定doc表明在原内容上进行更新,不会删除原来的内容 76 {"update":{"_id":"3"}} 77 {"doc":{"name":"lisi"}} 78 {"delete":{"_id":"2"}} 79 {"index":{}} 80 {"name":"ll","age":12} 81 ###########################使用请求体进行检索########################### 82 83 84 PUT /ems 85 { 86 "mappings": { 87 "properties": { 88 "name":{ 89 "type": "text" 90 }, 91 "age":{ 92 "type": "integer" 93 }, 94 "bir":{ 95 "type": "date" 96 }, 97 "content":{ 98 "type": "text" 99 }, 100 "address":{ 101 "type": "keyword" 102 } 103 } 104 } 105 } 106 DELETE /ems 107 PUT /ems/_bulk 108 {"index":{}} 109 {"name":"小黑","age":23,"bir":"2020-12-12","content":"开发一个MVC框架是个难事","address":"北京"} 110 {"index":{}} 111 {"name":"梅开风","age":24,"bir":"2020-12-12","content":"框架是一个分层次的架构,有多个模块组成,Spring 模块构建在核心容器之上","address":"上海"} 112 {"index":{}} 113 {"name":"王小黑","age":8,"bir":"2020-12-12","content":"Spring boot是Java语言的微服务架构","address":"南京"} 114 {"index":{}} 115 {"name":"张小五","age":9,"bir":"2020-12-12","content":"Spring的目标是简化Java的开发","address":"无锡"} 116 {"index":{}} 117 {"name":"win7","age":43,"bir":"2020-12-12","content":"Redis是一个开源的ansi c语言编写,支持网络的数据库","address":"杭州"} 118 {"index":{}} 119 {"name":"张无忌","age":58,"br":"2020-12-12","content":"Elasticsearch是一个搜索服务器","address":"郑州"} 120 121 122 ####使用url方式进行查询 123 GET /ems/_search?q=* 124 #对查询结果进行排序asc是升序,size表示只取结果的前几个,from是进行分页,表示从第几个记录开始展示 125 GET /ems/_search?q=*&sort=age:desc&size=2&from=2 126 #使用DSL方式进行检索 127 #查询所有数据,进行分页排序,选定大小 128 GET /ems/_search 129 { 130 "query":{"match_all": {}}, 131 "size": 2, 132 "from": 0, 133 "sort": [ 134 { 135 "FIELD": { 136 "age": "desc" 137 } 138 } 139 ] 140 } 141 #查询结果中返回指定的字段 142 GET /ems/_search 143 { 144 "query": {"match_all": {}}, 145 "_source": ["age","name"] 146 } 147 #关键字查询,这种查询方式是根据单个词或者单个汉字进行查询,之后引入分词才可以进行以词语为单位等,注意只有声明为text的时候是进行单个词的匹配,其他的类型(ip,boolean,integer,data,double,keyword等都是根据value的全部内容进行匹配) 148 GET /ems/_search#可以检索到 149 { 150 "query": {"term": { 151 "content": { 152 "value": "框" 153 } 154 }} 155 } 156 GET /ems/_search#可以检索到 157 { 158 "query": {"term": { 159 "name": { 160 "value": "黑" 161 } 162 }} 163 } 164 GET /ems/_search#不可以检索到 165 { 166 "query": {"term": { 167 "content": { 168 "value": "框架" 169 } 170 }} 171 } 172 GET /ems/_search #可以检索到 173 { 174 "query": {"term": { 175 "bir": { 176 "value": "2020-12-12" 177 } 178 }} 179 } 180 #范围查询(range) 181 GET /ems/_search 182 { 183 "query": {"range":{ 184 "age": { 185 "gte": 10, 186 "lte": 30 187 } 188 } 189 190 } 191 } 192 #前缀查询 193 GET /ems/_search 194 { 195 "query": { 196 "prefix": { 197 "content": { 198 "value": "框" 199 } 200 } 201 } 202 } 203 GET /ems/_search#需要注意的是数据库中的所有英文都被变成小写了,前缀主要是对于非text或者text引入了分词的概念此时通配符才能有作用,如下面的例子,南京在address里面是个整体所以正常需要“南京”才能匹配到,引入前缀就可以部分词进行匹配 204 { 205 "query": { 206 "prefix": { 207 "address": { 208 "value": "南" 209 } 210 } 211 } 212 } 213 #通配符查询?用来匹配一个任意的字符*用来匹配多个字符 214 GET /ems/_search 215 { 216 "query": { 217 "wildcard": { 218 "content": { 219 "value": "sp*" 220 } 221 } 222 } 223 } 224 GET /ems/_search 225 { 226 "query": { 227 "wildcard": { 228 "content": { 229 "value": "框*" 230 } 231 } 232 } 233 } 234 #多id进行查询 235 GET ems/_search 236 { 237 "query": { 238 "ids": { 239 "values": [ 240 "AoUFPHUBwStJbspbRiwc","A4UFPHUBwStJbspbRiwc"] 241 } 242 } 243 } 244 #模糊查询。此时当查询的内容与被查询的内容之间的编辑距离不大于2时可以成功的进行模糊匹配,具体是2个字符一下的要完全正确,2到4个只能错1个,五个以上最多错2个,其中编辑距离的概念是是指两个字串之间,由一个转成另一个(增删改)所需的最少编辑操作次数 245 GET /ems/_search 246 { 247 "query": { 248 "fuzzy": { 249 "content": "spr0og" 250 } 251 } 252 } 253 #布尔查询,是对多个条件实现复杂查询,bool表达式 254 #must 相当于&&同时成立,should: 相当于||成立一个就可以 255 #must not: 相当于!不能满足任何一个 256 257 GET /ems/_search 258 { 259 "query": { 260 "bool": { 261 "must": [ 262 {"term": { 263 "content": { 264 "value": "语" 265 } 266 }} 267 ] 268 , "must_not": [ 269 {"term": { 270 "age": { 271 "value": "43" 272 } 273 }} 274 ] 275 } 276 } 277 } 278 #多字段查询。得分是根据文章长度,和匹配到的次数,文章越短匹配次数越多越正确 279 #对于字段来说类型是text的需要对query进行分词处理,对于address则需要整体进行匹配 280 GET /ems/_search 281 { 282 "query": { 283 "multi_match": { 284 "query": "上海框架", 285 "fields": ["content","address"] 286 } 287 } 288 } 289 #多字段分词查询,这种查询方式需要先设定好分词器的类型 290 GET /ems/_search 291 { 292 "query": { 293 "multi_match": { 294 "analyzer": "standard", 295 "query": "上海框架", 296 "fields": ["content","address"] 297 } 298 } 299 } 300 GET _analyze #分成一个个字 301 { 302 "analyzer": "standard", 303 "text": "这是个框架" 304 } 305 GET _analyze#分成的结果是个整体 306 { 307 "analyzer": "simple", 308 "text": "这是个框架" 309 } 310 #高亮查询,一般把类型设置为text方便进行匹配 311 GET /ems/_search 312 { 313 "query": {"term": { 314 "content": { 315 "value": "开" 316 } 317 }}, 318 "highlight": { 319 320 "fields": {"*": {}}, 321 "pre_tags": ["<span style='color:red'>"], 322 "post_tags": ["</span>"], 323 "require_field_match": "false" 324 } 325 326 }
另一篇相关的关于elasticsearch的代码博客:https://www.cnblogs.com/naixin007/p/12088752.html
需要也可以看一下
作者:你的雷哥
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须在文章页面给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号