机器学习中各种熵的定义及理解
机器学习领域有一个十分有魅力的词:熵。然而究竟什么是熵,相信多数人都能说出一二,但又不能清晰的表达出来。
而笔者对熵的理解是:“拒绝学习、拒绝提升的人是没有未来的,也只有努力才能变成自己想成为的人”。
下图是对熵的一个简单描述:
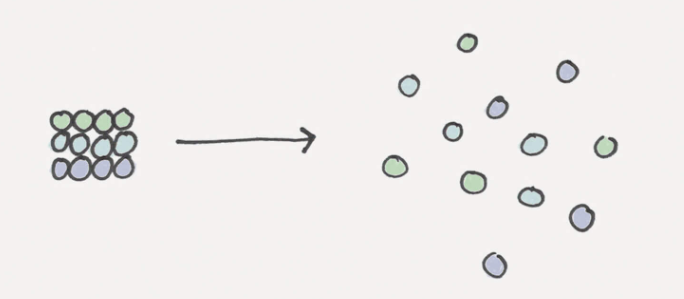
熵可以理解为是一种对无序状态的度量方式。那么熵又是如何被用在机器学习中呢?
在机器学习领域中,量化与随机事件相关的预期信息量以及量化概率分布之间的相似性是常见的问题。针对这类问题,利用香农熵以及衍生的其他熵概念去度量概率分布的信息量是个很好的解决方案。本文会尽可能用简单的描述分享自己对各种熵的定义及理解,欢迎交流讨论。
1. 自信息
自信息又称信息量。
“陈羽凡吸毒?!工作室不是刚辟谣了吗?哇!信息量好大!”
在生活中,极少发生的事情最容易引起吃瓜群众的关注。而经常发生的事情则不会引起注意,比如吃瓜群众从来不会去关系明天太阳会不会东边升起。
也就是说,信息量的多少与事件发生概率的大小成反比。
对于已发生的事件i,其所提供的信息量为:
![]()
其中底数通常为2,负号的目的是为了保证信息量不为负。
事件i发生的概率与对应信息量的关系如下所示:
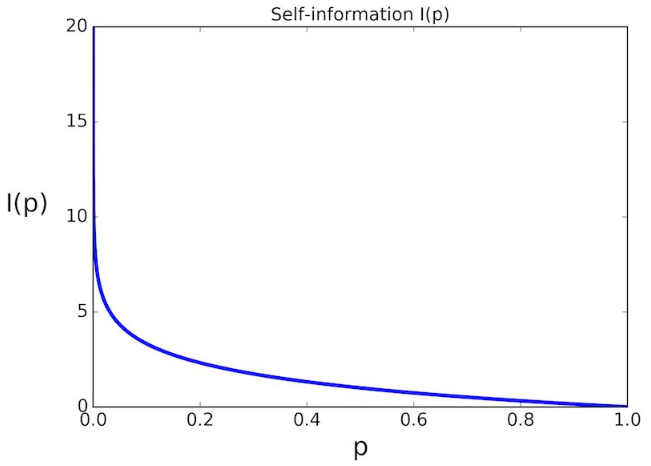
我们再考虑一个问题:假设事件x个可能的状态,例如一枚硬币抛出落地后可能有两种状态,正面或反面朝上,这时候该怎样取衡量事件所提供的信息量?
2. 信息熵
信息熵又称香农熵。
到目前为止,我们只讨论了自信息。实际上,对于一枚硬币来讲,自信息实际上等于信息熵,因为无论正反面,朝上的概率都相等。
信息熵用来度量一个事件可能具有多个状态下的信息量,也可以认为是信息量关于事件概率分布的期望值:
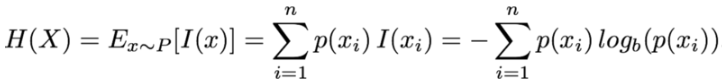
其中事件x共有n个状态,i表示第i个状态,底数b通常设为2,也可设为10或e。
H(x)表示用以消除这个事件的不确定性所需要的统计信息量,即信息熵。
还是以抛硬币为例来理解信息熵:
|
事件 |
概率 |
信息量(自信息) |
信息熵(统计信息量) |
|
正面朝上 |
1/2 |
-log(1/2) |
(-1/2 * log(1/2))+( -1/2 * log(1/2)) |
|
反面朝上 |
1/2 |
-log(1/2) |
(-1/2 * log(1/2))+( -1/2 * log(1/2)) |
根据信息熵公式可得出以下结论:
- 若事件x个状态发生概率为1,那么信息熵H(x)等于0
- 若事件x的所有状态n发生概率都一致,即都为1/n,那么信息熵H(x)有极大值logn。
信息熵可以推广到连续域,此时被称为微分熵。对于连续随机变量x和概率密度函数p(x), 信息熵的定义如下:
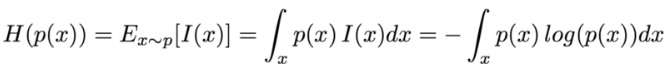

3. 联合熵
上面我们讲到的都是对于一个事件的熵。那么如果有多个事件,例如事件x和事件y都出现时,又该怎样去度量呢?
首先,是联合熵,公式如下:
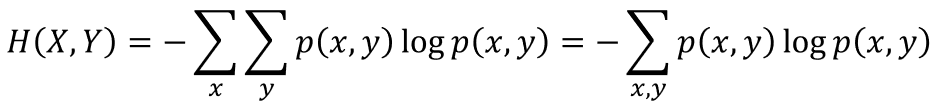
其中p(x,y)代表事件x和事件y的联合概率。
这次以同时抛两枚硬币为例来说明联合熵如何对两个事件进行度量:
|
事件 |
概率 |
信息量(自信息) |
联合熵 |
|
x正,y正 |
1/2 * 1/2 = 1/4 |
-log(1/4) |
-(1/4*log(1/4)+ 1/4 * log(1/4) + 1/4 * log(1/4) + 1/4 * log(1/4)) |
|
x正,y反 |
1/2 * 1/2 = 1/4 |
-log(1/4) |
-(1/4*log(1/4)+ 1/4 * log(1/4) + 1/4 * log(1/4) + 1/4 * log(1/4)) |
|
X反,y正 |
1/2 * 1/2 = 1/4 |
-log(1/4) |
-(1/4*log(1/4)+ 1/4 * log(1/4) + 1/4 * log(1/4) + 1/4 * log(1/4)) |
|
X反,y反 |
1/2 * 1/2 = 1/4 |
-log(1/4) |
-(1/4*log(1/4)+ 1/4 * log(1/4) + 1/4 * log(1/4) + 1/4 * log(1/4)) |
4. 条件熵
条件熵表示在已知事件x的条件下,事件y的不确定性。定义为在给定条件下x,y的条件分布概率的熵对x的数学期望:
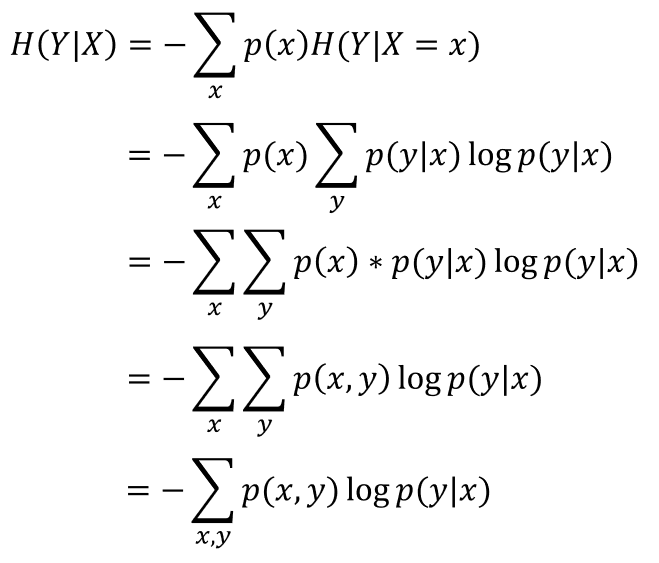
可以发现,条件熵与联合熵仅仅在于log项不同。
此外,根据联合概率分布与条件概率分布的关系,可得:
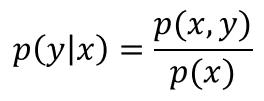
所以:
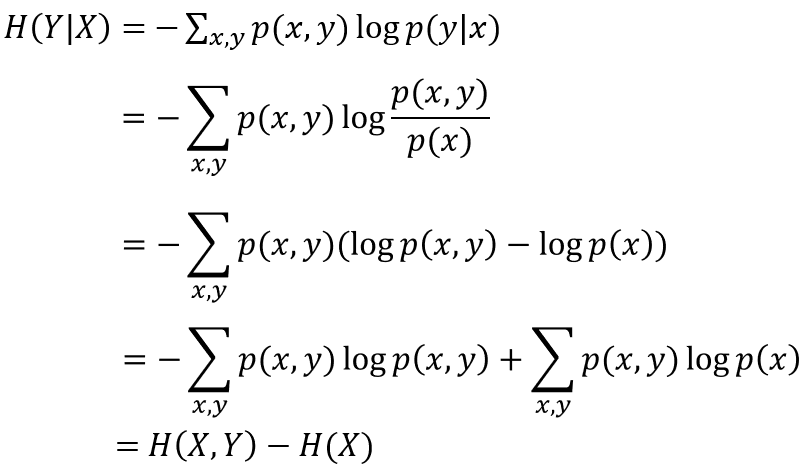
即在x条件下,y的条件熵 = x,y的联合熵 - x的信息熵。
5. 交叉熵
交叉熵是一个用来比较两个概率分布p和q的度量公式。换句话说,交叉熵是衡量在真实分布下,使用非真实分布所制定的策略能够消除系统不确定性的大小。
如何正确理解上述这段描述呢?首先,观察交叉熵的公式,如下图所示:
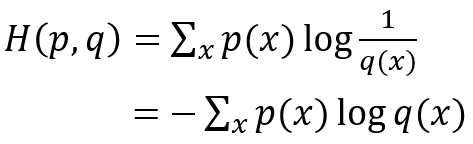
其中,p(x)为事件的真实分布概率,q(x)为事件的非真实分布概率。
可以看到,与信息熵相比,唯一不同的是log里的概率由信息熵中的真实分布概率p(x)变成了非真实概率(假设分布概率)q(x),即1-p(x)。也就是与信息熵相比,交叉熵计算的不是log(p)在p下的期望,而是log(q)在p下的期望。
同样地,交叉熵可也以推广到连续域。对于连续随机变量x和概率密度函数p(x)和假设分布概率密度函数q(x), 交叉熵的定义如下:
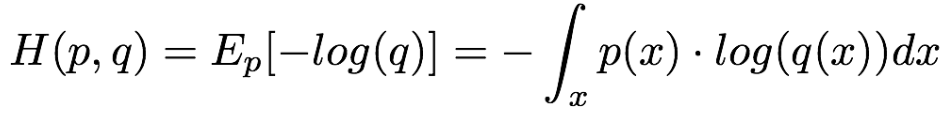
所以,如果假设分布概率与真实分布概率一致,那么交叉熵 = 信息熵。
6. 相对熵
相对熵又称KL散度。
相对熵衡量了当修改从先验分布p到后验分布q的信念后所带来的信息增益。换句话说,就是用后验分布 q 来近似先验分布 p 的时候造成的信息损失。再直白一点,就是衡量不同策略之间的差异性。
计算公式如下:
![]()
其中H(p,q)代表策略p下的交叉熵,H(p)代表信息熵。所以,相对熵 = 某个策略的交叉熵-信息熵。
相对熵用来衡量q拟合p的过程中产生的信息损耗,损耗越少,q拟合p也就越好。
需要注意的是,尽管从直觉上相对熵(KL散度)是个度量或距离函数, 但是它实际上并不是一个真正的度量或距离。因为KL散度不具有对称性:从分布P到Q的距离通常并不等于从Q到P的距离。
![]()
7. 互信息
互信息用来表示两个变量X与Y之间是否有关系,以及关系的强弱。
用公式可以表示为:
![]()
因此,可认为变量X与Y的互信息就是信息熵H(X)与条件熵H(X|Y)的差。
8. 熵在机器学习中的应用
针对熵的应用,个人总结主要有以下几点:
- 在贝叶斯网络中,会假设一个先验分布,目的是为了反映随机变量在观测前的不确定性。在进行模型训练时,减小熵,同时让后验分布在最可能的参数值周围形成峰值。
- 在做分类任务的参数估计时,尤其是在神经网络中,交叉熵往往作为损失函数用来更新网络权重。
- 在树模型算法中,熵的作用也是不可或缺,尤其是在使用ID3信息增益、C4.5增益率时,通过使用熵来划分子节点,从而可以构造出整棵树。
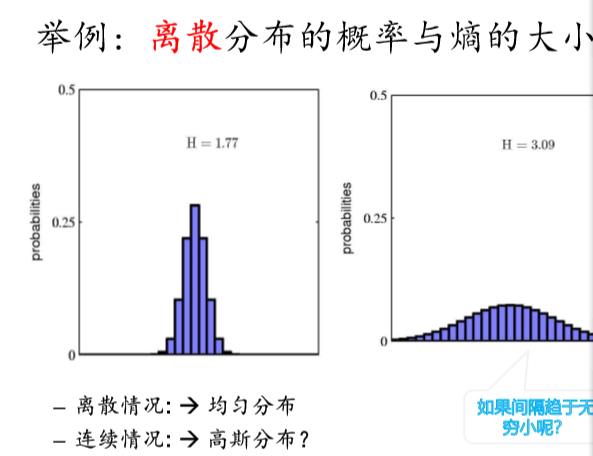
离散分布熵的最大值对应均匀分布,连续情况对应的是高斯分布时对应的熵最大
转:https://www.cnblogs.com/wkang/p/10068475.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!
· 零经验选手,Compose 一天开发一款小游戏!