命名实体识别
命名实体识别(Named Entity Recognition,NER)是NLP中一项非常基础的任务。NER是信息提取、问答系统、句法分析、机器翻译等众多NLP任务的重要基础工具。
命名实体识别的准确度,决定了下游任务的效果,是NLP中非常重要的一个基础问题。
作者&编辑 | 小Dream哥
1 命名实体识别是什么?
要了解NER是一回什么事,首先要先说清楚,什么是实体。要讨论实体的理论概念,可能会花上一整天的时间,我们不过多纠缠。
简单的理解,实体,可以认为是某一个概念的实例。
例如,“人名”是一种概念,或者说实体类型,那么“蔡英文”就是一种“人名”实体了。“时间”是一种实体类型,那么“中秋节”就是一种“时间”实体了。
所谓实体识别,就是将你想要获取到的实体类型,从一句话里面挑出来的过程。
小明 在 北京大学 的 燕园 看了
PER ORG LOC
中国男篮 的一场比赛
ORG
如上面的例子所示,句子“小明在北京大学的燕园看了中国男篮 的一场比赛”,通过NER模型,将“小明 ”以PER,“北京大学”以ORG,“燕园”以LOC,“中国男篮”以ORG为类别分别挑了出来。
2 命名实体识别的数据标注方式
NER是一种序列标注问题,因此他们的数据标注方式也遵照序列标注问题的方式,主要是BIO和BIOES两种。这里直接介绍BIOES,明白了BIOES,BIO也就掌握了。
先列出来BIOES分别代表什么意思:
B,即Begin,表示开始
I,即Intermediate,表示中间
E,即End,表示结尾
S,即Single,表示单个字符
O,即Other,表示其他,用于标记无关字符
将“小明在北京大学的燕园看了中国男篮的一场比赛”这句话,进行标注,结果就是:
[B-PER,E-PER,O, B-ORG,I-ORG,I-ORG,E-ORG,O,B-LOC,E-LOC,O,O,B-ORG,I-ORG,I-ORG,E-ORG,O,O,O,O]
那么,换句话说,NER的过程,就是根据输入的句子,预测出其标注序列的过程。
3 命名实体识别的方法介绍
1)HMM和CRF等机器学习算法
HMM和CRF很适合用来做序列标注问题,早期很多的效果较好的成果,都是出自这两个模型。两种模型在序列标注问题中应用,我们在之前的文章中有介绍,感兴趣的同学可以看下如下链接的文章:
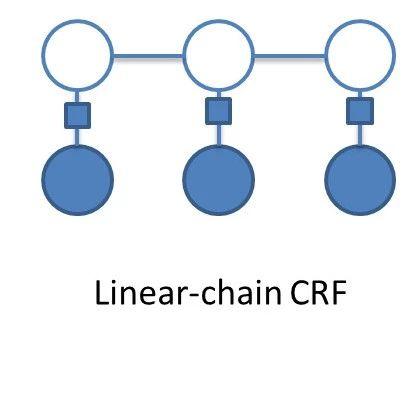
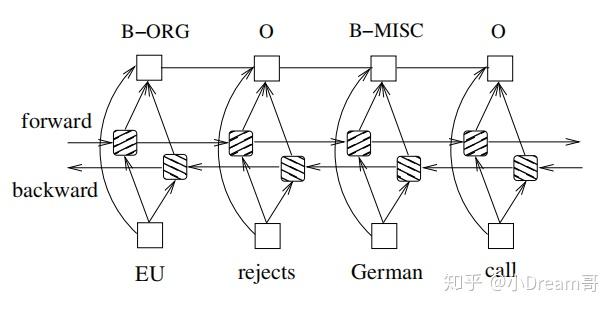
目前做NER比较主流的方法就是采用LSTM作为特征抽取器,再接一个CRF层来作为输出层,后面我们用专门的文章来介绍这个模型。如下图所示:
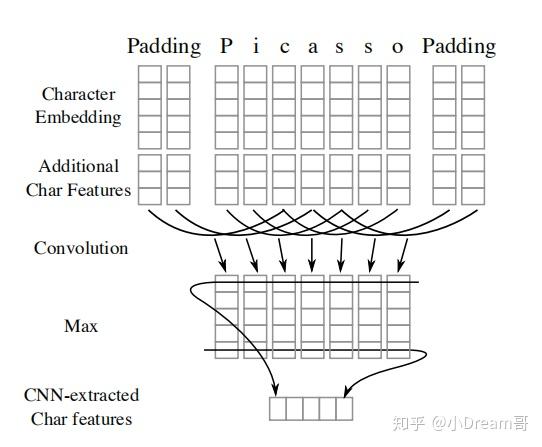
3)CNN+CRF
CNN虽然在长序列的特征提取上有弱势,但是CNN模型可有并行能力,有运算速度快的优势。膨胀卷积的引入,使得CNN在NER任务中,能够兼顾运算速度和长序列的特征提取,后面我们用专门的文章来介绍这个模型。
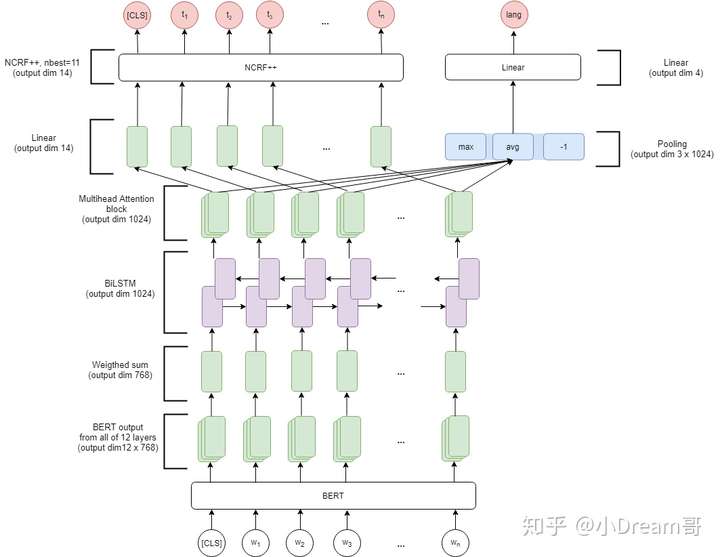
4)BERT+(LSTM)+CRF
BERT中蕴含了大量的通用知识,利用预训练好的BERT模型,再用少量的标注数据进行FINETUNE是一种快速的获得效果不错的NER的方法,后面我们用专门的文章来介绍这个模型。
NER 是 NLP 中一项基本任务,就是从文本中识别出命名性指称项,为关系抽取等任务做铺垫,在信息抽取、信息检索、机器翻译、问答系统等多种自然语言处理技术中必不可少的组成部分。
命名实体识别研究的命名实体一般分为 3 大类(实体类、时间类、数字类)和 7 小类(人名、地名、组织机构名、时间、日期、货币和百分比)。由于时间、日期、货币等实体构成的规律比较明显,其实体类型识别通常可以采用模式匹配的方式获得比较好的识别效果,所以,相较而言,人名、地名、机构名较复杂,目前的研究主要以这几种实体为主。
中文命名实体识别
NER 的效果评判主要是看实体的边界是否划分正确以及实体的类型是否标注正确。相对于英文 NER ,中文 NER 有以下难点:
(1)不像英文有明显的实体边界;
(2)各类命名实体的数量众多。如人名大多属于未登录词;
(3)命名实体的构成规律复杂。如中文人名识别可以细分为中国人名识别、音译人名识别等;另外,机构名的组成方式最复杂,种类繁多,规律不统一。
(4)嵌套情况复杂。如人名中嵌套着地名,地名中嵌套着人名、机构名。
(5)长度不确定。相对于人名、地方,机构名的长度和边界更难以识别,中国人名一般为2-4字,常用地方也大多为2-4字,但机构名长度变化范围极大。
命名实体识别的主要三种方法:
-
基于规则的命名实体识别:
利用手工构造规则模板,选用特征包括统计信息、标点符号、关键字、指示词和方向词、位置词(如尾字)、中心词等方法,结合命名实体库,对每条规则进行权重赋值,然后通过实体与规则的相符情况来进行类型判断,即:将文本与规则进行匹配来识别出命名实体。例如,对于中文来说,“说”、“老师”等词语可作为人名的下文,“大学”、“医院”等词语可以作为组织机构名的结尾,还可以利用到词性、句法信息。
当提取的规则能够较好地反映语言现象时,该方法能明显优于其他方法。但在大多数场景下,在构建规则的过程中往往需要大量的语言学知识,不同语言的识别规则不尽相同。规则的构建往往依赖于具体语言、领域和文本风格,其构建规则过程耗时且难以覆盖所有的语言现象,可移植性差、更新维护困难等。 -
基于统计的命名实体识别:
目前常用的基于统计机器学习的命名实体识别方法有:隐马尔可夫模型(HMM)、最大熵模型(ME)、支持向量机(SVM)、条件随机场(CRF)等。其主要思想是:基于人工标注的大量语料,将命名实体识别作为序列标注问题,利用语料来学习标注模型,从而对句子的各个位置进行标注。 -
混合方法:
自然语言处理并不完全是一个随机的过程,单独使用基于规则的方法,状态搜索空间大,必须要借助规则提前进行过滤修剪处理。目前没有单独使用统计模型而不使用规则知识的命名实体识别系统,很多情况下是使用规则和统计结合的混合方法。目前主流的方法是序列标注方式,即特征模板 +CRF 。
-
# coding: utf-8 import nltk #nltk.download('maxent_ne_chunker') ex = "Shubhangi visited the Taj Mahal after taking a SpiceJet flight from Pune " tags = nltk.pos_tag(nltk.word_tokenize(ex)) ne = nltk.ne_chunk(tags,binary = True) ne.draw()
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号