Semi-supervised半监督学习
1.半监督学习
1.1 定义
- 监督学习样本数据 例如:图片+标签
- 半监督学习样本数据 例如:R个图片+标签,U个图片,通常U >> R。分类:transductive learning、inductive learning
- 直推式学习(transductive learning):将无标签数据作为测试数据。该做法不算是欺骗(当应用label才算欺骗,该做法仅应用feature)
- 归纳学习(inductive learning):无标签数据不作为测试数据,在training时还不知道testing set是什么样子,即事先无法利用testing set,需要先训练好model。
- 采用直推式学习/归纳学习取决于testing set是否已知
1.2 为什么采用半监督学习
- 不缺数据,缺带标签的数据且收集昂贵
- 人类行为也是在做半监督学习
1.3 课程内容
- 生成模型的半监督学习
- 低密度分离的假设
- 平滑性假设
- 更好表示
2.生成模型的半监督学习
在监督学习中:已知样本来自C1 C2两类,我们统计得到数据的先验概率P(Ci)和分类概率P(x|Ci),假设每类数据均服从高斯分布,则其均值分别为μ
-
使用上面的式子更新模型的参数

3.低密度分离的假设(low-density separation)
3.1 low-density separation定义
若仅给定两类有标签数据那么boundary为两条红线中的任一条均可(下图),但当加入无标签数据时(绿圆)则左侧boundary最优,因为low-density separation定义为交界处data密度最低 则最合理。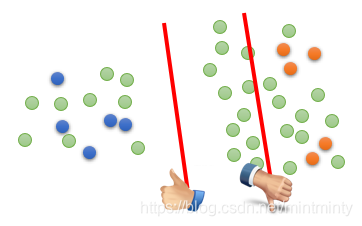
3.2 self-training
过程:
- 给定R组labelled data,U组unlabelled data
- 通过labelled data训练得到模型 ff f f*
- 将unlabelled data放入模型 ff f f*中得到伪标签数据
- 将部分伪标签数据+R组labelled data,放入模型 ff f f*中再训练(选择哪部分伪标签放入训练需要自定义,甚至自己提供权重)
- 循环
思考:
- 将该方法应用于回归问题中是否有用?不会,伪标签数据由 ff f f*产生,再加入至模型中,对模型无改进。
- generative model与self-training对比:generative model用的是soft label(存在一定概率属于C1,同时也存在一定概率属于C2),self-training用的是hard label(类别是明确的)。在neural network中,采用soft label是鸡肋的,分析:
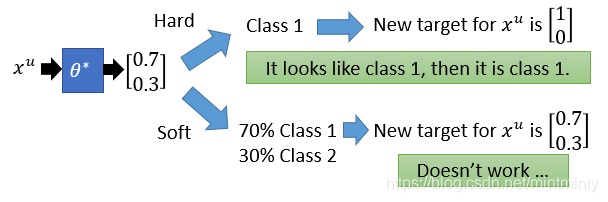
若认为这样的判断过于武断,则可采用下面进阶的方法——基于熵的正则化
3.3 基于熵的正则化(entropy-based regularization)
评估一个模型的优劣:类别梯度明显则为优,类别梯度都差不多则为劣。如图: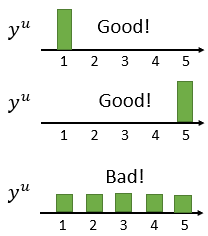
引入熵概念:熵越小,该模型越好。据此假设即可重新设计loss function(下图),针对标签数据即,使预测标签和正确标签差距越小越好(如可使交叉熵估测),针对无标签数据则采用熵进行衡量,并且也可根据个人对于标签数据/非标签数据的偏好*权重 λλ \lambda
λ,同时因为loss function可微分,所以训练起来无障碍。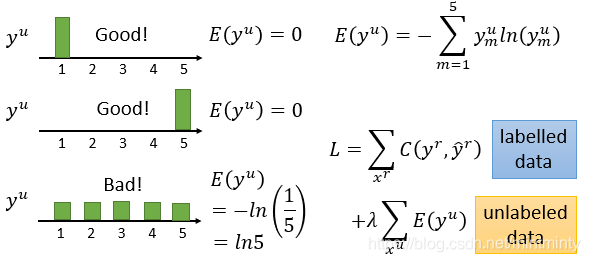
4.平滑假设(smoothness assumption)
4.1 假设
- x的分布是不平均的,某些地方集中,某些地方分散
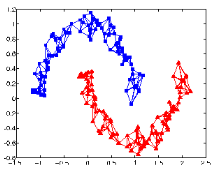
- x1和x2当处于同一个高密度区域时,则其标签相同;x3和x2当处于不同高密度区域时,则其标签不同(下图)
4.2 应用
- 如数字识别,单纯计算pixel的相似度不够准确,而可通过中间过渡形态(即不直接相连的相似)进行分类
- 如在文件分类,收集够多的无标签数据找到相似性

4.3 做法
4.3.1 方法1:先聚类再标注(实际先用deep autoencoder提取特征,再操作)
- 如图有两个标签,蓝色无标签数据
- 先分成3个cluster
- 再标注类别
4.3.2 方法2:graph-based approach
定性分析:
- 定义 xi 和 xj 计算相似度的方法s(xi,xj)s(xi,xj) s(x^i,x^j) s(xi,xj)
- 建立graph,添加edge,如k nearest neighbor(即与自己最近的k点相连)
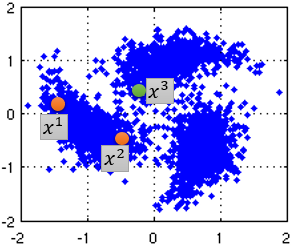
- 可根据相似度添加edge权重,如Gaussian Radial Basis Function(可以保证距离小的相连 e.g.两橙色点,距离较大的 虽然不明显但也无法相连 e.g.橙色和绿色点,原因:取了exponential后值会变大 区分效果较好):
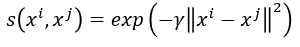
- 标签数据会影响其邻居类别,且标签会通过link传递(即虽然可能某点并没有直接与标签数据相连,但是通过传递,判定该点为该标签类别)
定量分析:
- 如何衡量smoothness程度?使用下图公式,计算两两相连的所有点,其中ww w
w为权重。得到的ss s
s越小,越平滑。

整理一下算法: - yy y y为(R+U)维向量,WW W W为权重矩阵,DD D D为将WW W W每一行求和放在对角线位置
- 拉普拉斯矩阵 LL L
L = DD D
D - WW W
W
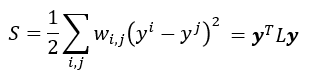
- loss function如下图,分析:不仅要使C(yr,yˆr)C(yr,y^r) C(y^r,\hat y^r)
C(yr,y^r)越小越好,还要是其足够平滑(即λSλS \lambda S
λS最小,也象征正则化项)
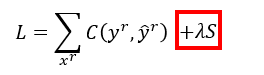
5.更好表示(better representation)
思想就是直指核心,具体内容下节课讲。
作者:你的雷哥
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须在文章页面给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号