吴恩达《深度学习》第五门课(3)序列模型和注意力机制
3.1序列结构的各种序列
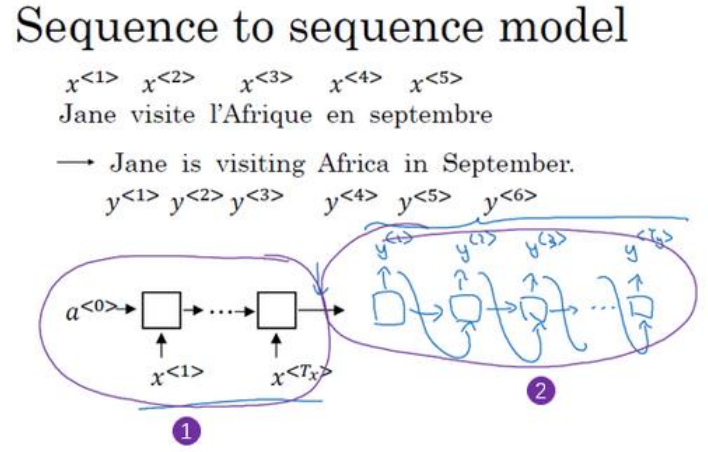
(1)seq2seq:如机器翻译,从法文翻译成英文,将会是下面这样的结构,包括编码网络和解码网络。
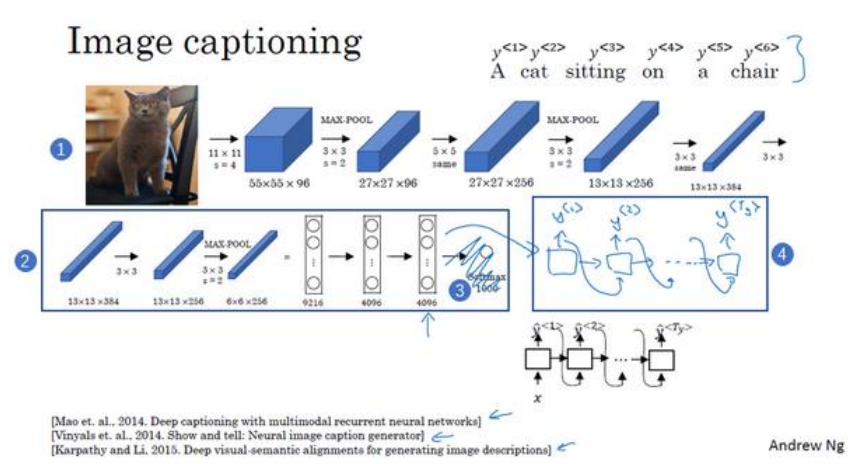
(2)image to sequence:比如给一幅图像添加描述,如下图中的“一只猫站在椅子上”。同样包括编码网络和解码网络。
3.2选择最可能的句子
(1)机器翻译的本质就是一个条件语言模型,在给定输入的条件下输出最有可能的句子。
(2)这里的条件语言模型与第一周讲的语言模型的区别在于,前者是有输入的,而后者是没有输入直接随机生成一个句子。
(3)将使用束搜索的方法来寻找概率最高的句子,之所以不用贪心搜索是因为,每一次都选择概率最大的词组成的句子未必是概率最大的。
3.3集束搜索
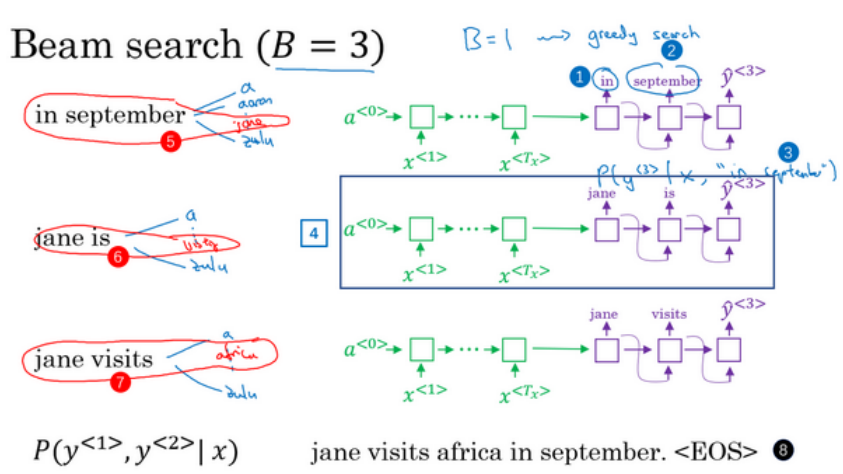
(1)假设词汇量是10000,集束宽是3.
(2)首先选出3个概率最大的作为第一个词。
(2)然后3个词分别于10000个词总共组成30000个组,同样选出三个最大的概率。注意p(y1,y2|X)=p(y1|X)p(y2|y1,X).
(3)上面选出来的3个两个词组成的词语又与10000个词组合成30000个组,选出最大的3个概率的词组,以此类推直到出现结束符。最后选出概率最大的句子。
3.4改进集束搜索
(1)由于每一项的值都是概率,小于1,所以很多项相乘时会越来越小,甚至出现下溢(电脑无法用浮点数精确表示)。所以对每个概率取对数,因为对数是单调递增,所以不会影响最终输出。
(2)由于各项都是非常小的值,所以网络会偏向于输出很短的句子,为了避免这种情况,添加归一化项,将上面算出来的结果除以Tyα,其中Ty是每个句子单词数,α取值为0-1,为0时即不归一化,为1时表示完全用长度归一化,可以取中间的值。
(3)经过改进之后的目标函数叫归一化的对数似然目标函数。
3.5集束搜索的误差分析
(1)使用开发集,找出翻译错误的句子,用来做误差分析。人工翻译的句子记做y*,网络得到的结果记做ý,如下图所示:

(2)出错的原因只要分为两个原因,要么是RNN网络(包括编码和解码部分)出错,要么是使用的集束搜索算法有问题。
(3)当p(y*|x)>y(ý|x)时说明集束搜索不能够给你一个概率更大的句子,所以是集束搜索出了问题,可以改变集束宽。
(4)当p(y*|x)<y(ý|x)时说明RNN网络出问题了,网络本身没法让最好的翻译的概率最大。
3.6Bleu得分
(1)Bleu代表bilingual evaluation understudy(双语评估替补)。
(2)比如说参考的标准翻译有“The cat is on the mat”和“There is a cat on the mat”都是非常好的翻译,同理还有其他很好的类似的句子,那么该怎么评估好坏呢?
(3)上面的句子中the出现最多的次数是2,所以按照占比2/7,如果翻译出来的句子也有the,比如说翻译出来6个是the一个cat,其得分为2/7加上1/7.这是按照单词来计算了,分数的分子最大值是词汇在参考句子中占比的上限。
(3)所有的参考翻译中相连的两词汇也可以组成一个词组,翻译的结果(相同的算一个)同样进行比对按照上面的方式来计算得分。三元词,四元词同样如此。

(4)最后按照下面式子翻译的计算精确度:

3.7注意力模型的直观理解
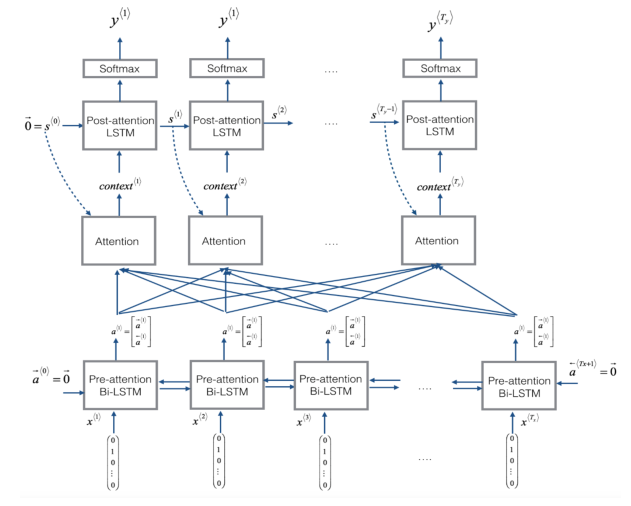
(1)当翻译一个特别长的句子时,如果将整个句子输入进去再进行翻译,网络是很难记住那么长的句子的,就跟人一样,人习惯看一点翻译一点,注意力集中在某一部分,注意力模型也是如此,如下图所示,首先是双向循环神经网络,这时不直接输出结果,而是利用一个注意力权重,再输入到一个RNN中之后在进行输出。
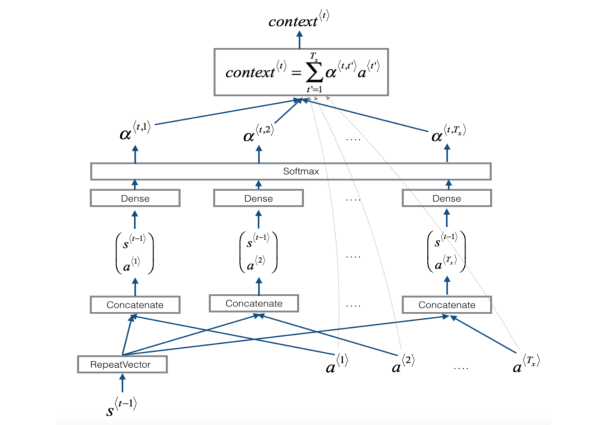
3.8注意力模型
(1)直接看上面的结构图。
3.9语音识别
(1)语音识别有两种主要的系统,一个是前面提到的注意力模型,还有一种叫做CTC(connectionist temporal classification)的系统。
(2)由于在语音识别中,比如10s时长,采样频率是100,那么10秒钟将会有1000个输入,显然输出不可能有那么长的结果,这时让输出的长度与输入相等,输出可以用重复的字符和特殊的空白符(注意不是空格,空格的输出就是空格),如下图所示,这时将空白符所分割的重复字符折叠起来,最终生成正确的输出“the q”:

3.10触发字检测
(1)下面是一个简单的触发字的示意图,当没有听到触发字时输出0,当听到关键字时输出1,由于正负样本严重失衡,所以可以在听到触发字之后一段时间都输出1来解决。

3.11总结和致谢
(1)用深度学习这个强大的武器,去做你觉得可以让世界变得更加美好的事。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号