yolo,ssd系列
YOLOv1
YOLOv2
YOLOv3
SSD
优秀文章摘录
目标检测之YOLOv3算法: An Incremental Improvement
1. 前言
论文地址:https://pjreddie.com/media/files/papers/YOLOv3.pdf
相关代码:https://github.com/yjh0410/yolov2-yolov3_PyTorch
目标检测之YOLO算法:YOLOv1,YOLOv2,YOLOv3,TinyYOLO,YOLOv4,YOLOv5,YOLObile,YOLOF详解:
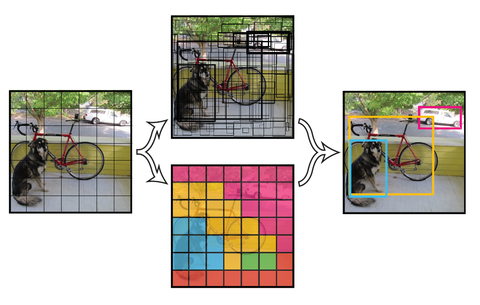
2. YOLOv3算法详解
 YOLO v3网络结构
YOLO v3网络结构
YOLO v3的模型(如上图所示,图来自这里)比之前的模型复杂了不少,可以通过改变模型结构的大小来权衡速度与精度。
DBL:代码中的Darknetconv2d_BN_Leaky,是yolo_v3的基本组件。就是卷积+BN+Leaky relu。resn:n代表数字,有res1,res2, … ,res8等等,表示这个res_block里含有多少个res_unit。concat:张量拼接。将darknet中间层和后面的某一层的上采样进行拼接。拼接的操作和残差层add的操作是不一样的,拼接会扩充张量的维度,而add只是直接相加不会导致张量维度的改变
速度和精度(mAP)对比如下:
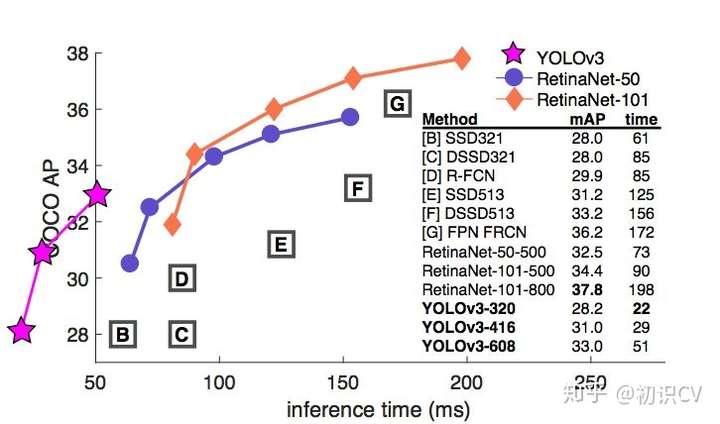
简而言之,YOLOv3 的先验检测(Prior detection)系统将分类器或定位器重新用于执行检测任务。他们将模型应用于图像的多个位置和尺度。而那些评分较高的区域就可以视为检测结果。此外,相对于其它目标检测方法,我们使用了完全不同的方法。我们将一个单神经网络应用于整张图像,该网络将图像划分为不同的区域,因而预测每一块区域的边界框和概率,这些边界框会通过预测的概率加权。我们的模型相比于基于分类器的系统有一些优势。它在测试时会查看整个图像,所以它的预测利用了图像中的全局信息。与需要数千张单一目标图像的 R-CNN 不同,它通过单一网络评估进行预测。这令 YOLOv3 非常快,一般它比 R-CNN 快 1000 倍、比 Fast R-CNN 快 100 倍。
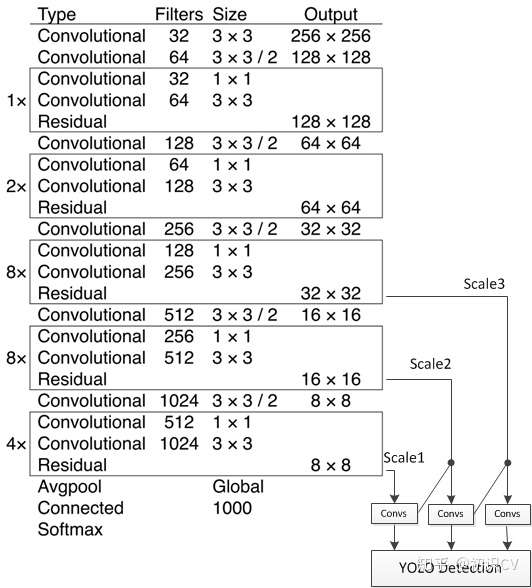
2.1 基础网络 Darknet-53
下图是YOLOv3的网络模型结构图,此结构主要由75个卷积层构成,卷积层对于分析物体特征最为有效。由于没有使用全连接层,该网络可以对应任意大小的输入图像。此外,池化层也没有出现在YOLOv3当中,取而代之的是将卷积层的stride设为2来达到下采样的效果,同时将尺度不变特征传送到下一层。除此之外,YOLOv3中还使用了类似ResNet和FPN网络的结构,这两个结构对于提高检测精度也是大有裨益。作者在3条预测支路采用的也是全卷积的结构,其中最后一个卷积层的卷积核个数是255,是针对COCO数据集的80类:3*(80+4+1)=255,3表示一个grid cell包含3个bounding box,4表示框的4个坐标信息,1表示objectness score。
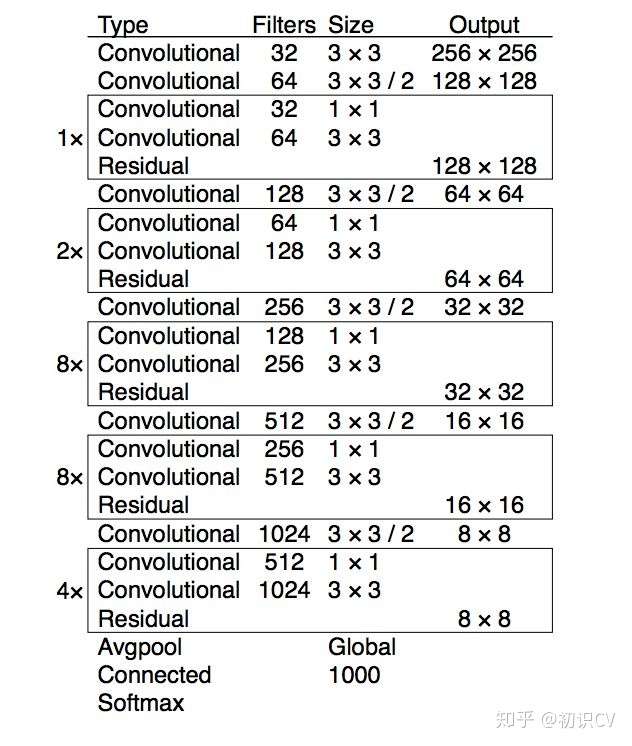
darknet-53:
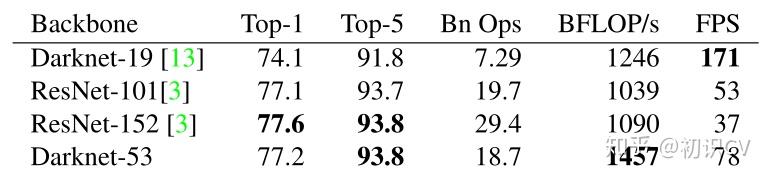
作者在ImageNet上实验发现这个darknet-53,的确很强,相对于ResNet-152和ResNet-101,darknet-53不仅在分类精度上差不多,计算速度还比ResNet-152和ResNet-101强多了,网络层数也比他们少。对比如下:
darknet-53代码解析如下(Pytorch):
class DarkNet_53(nn.Module):
"""
YOLOv3 model module. The module list is defined by create_yolov3_modules function. \
The network returns loss values from three YOLO layers during training \
and detection results during test.
"""
def __init__(self, num_classes=1000):
super(DarkNet_53, self).__init__()
# stride = 2
self.layer_1 = nn.Sequential(
Conv_BN_LeakyReLU(3, 32, 3, padding=1),
Conv_BN_LeakyReLU(32, 64, 3, padding=1, stride=2),
resblock(64, nblocks=1)
)
# stride = 4
self.layer_2 = nn.Sequential(
Conv_BN_LeakyReLU(64, 128, 3, padding=1, stride=2),
resblock(128, nblocks=2)
)
# stride = 8
self.layer_3 = nn.Sequential(
Conv_BN_LeakyReLU(128, 256, 3, padding=1, stride=2),
resblock(256, nblocks=8)
)
# stride = 16
self.layer_4 = nn.Sequential(
Conv_BN_LeakyReLU(256, 512, 3, padding=1, stride=2),
resblock(512, nblocks=8)
)
# stride = 32
self.layer_5 = nn.Sequential(
Conv_BN_LeakyReLU(512, 1024, 3, padding=1, stride=2),
resblock(1024, nblocks=4)
)
# self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
# self.fc = nn.Linear(1024, num_classes)
def forward(self, x, targets=None):
x = self.layer_1(x)
x = self.layer_2(x)
C_3 = self.layer_3(x)
C_4 = self.layer_4(C_3)
C_5 = self.layer_5(C_4)
# x = self.avgpool(x)
# x = x.view(x.size(0), -1)
# x = self.fc(x)
return C_3, C_4, C_5其中,Conv_BN_LeakyReLU和resblock代码如下,Conv_BN_LeakyReLU等价于Conv+BN+LReLU即YOLO v3网络结构中的DBL,resblock意思是残差部分的主体结构即YOLO v3网络结构中的res unit:
class Conv_BN_LeakyReLU(nn.Module):
def __init__(self, in_channels, out_channels, ksize, padding=0, stride=1, dilation=1):
super(Conv_BN_LeakyReLU, self).__init__()
self.convs = nn.Sequential(
nn.Conv2d(in_channels, out_channels, ksize, padding=padding, stride=stride, dilation=dilation),
nn.BatchNorm2d(out_channels),
nn.LeakyReLU(0.1, inplace=True)
)
def forward(self, x):
return self.convs(x)
class resblock(nn.Module):
def __init__(self, ch, nblocks=1):
super().__init__()
self.module_list = nn.ModuleList()
for _ in range(nblocks):
resblock_one = nn.Sequential(
Conv_BN_LeakyReLU(ch, ch//2, 1),
Conv_BN_LeakyReLU(ch//2, ch, 3, padding=1)
)
self.module_list.append(resblock_one)
def forward(self, x):
for module in self.module_list:
x = module(x) + x
return x主干架构的性能对比:
检测结构如下:
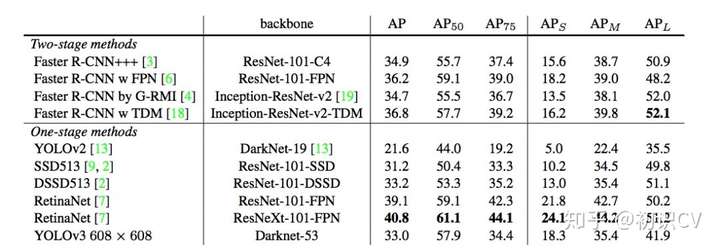
YOLOv3在mAP@0.5及小目标APs上具有不错的结果,但随着IOU的增大,性能下降,说明YOLOv3不能很好地与ground truth切合。
2.2 YOLOV3中的边框回归
一个回归框是由四个参数决定, 。yolov3是在训练的数据集上聚类产生prior boxes的一系列宽高(是在图像416x416的坐标系里),默认9种。YOLOV3思想理论是将输入图像分成SxS个格子(有三处进行检测,分别是在52x52, 26x26, 13x13的feature map上,即S会分别为52,26,13),若某个物体Ground truth的中心位置的坐标落入到某个格子,那么这个格子就负责检测中心落在该栅格中的物体。三次检测,每次对应的感受野不同,32倍降采样的感受野最大(13x13),适合检测大的目标,每个cell的三个anchor boxes为(116 ,90),(156 ,198),(373 ,326)。16倍(26x26)适合一般大小的物体,anchor boxes为(30,61), (62,45),(59,119)。8倍的感受野最小(52x52),适合检测小目标,因此anchor boxes为(10,13),(16,30),(33,23)。所以当输入为416×416时,实际总共有(52×52+26×26+13×13)×3=10647个proposal boxes。
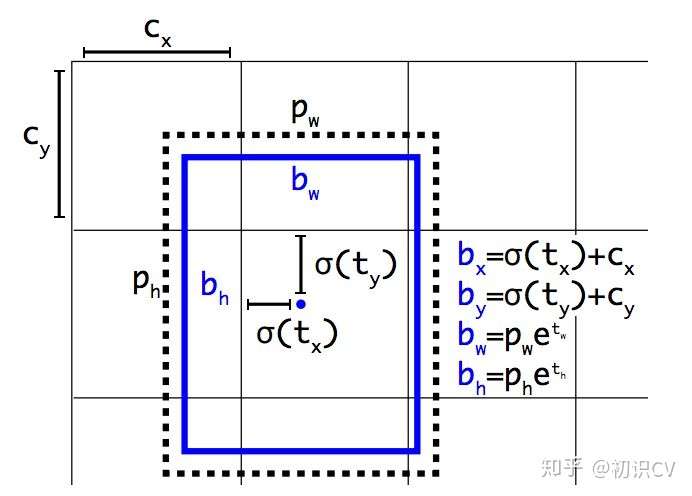 图 2:带有维度先验和定位预测的边界框。我们边界框的宽和高以作为离聚类中心的位移,并使用 Sigmoid 函数预测边界框相对于滤波器应用位置的中心坐标。
图 2:带有维度先验和定位预测的边界框。我们边界框的宽和高以作为离聚类中心的位移,并使用 Sigmoid 函数预测边界框相对于滤波器应用位置的中心坐标。
yolov3对每个bounding box预测偏移量和尺度缩放四个值 (网络需要学习的目标),对于预测的cell(一幅图划分成S×S个网格cell)根据图像左上角的偏移
,每个grid cell在feature map中的宽和高均为1,以及预先设的anchor box的宽和高
(预设聚类的宽高需要除以stride映射到feature map上)。最终得到的边框坐标值是b*,而网络学习目标是t*,用sigmod函数、指数转换。可以对bounding box按如下的方式进行预测:
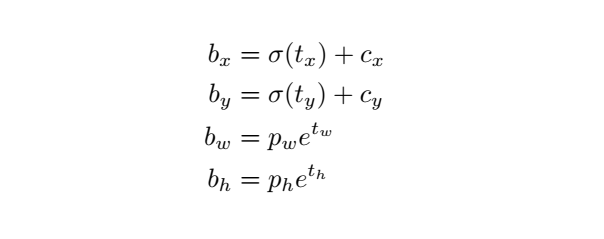
代码解析:
1.首先需要产生所需的图像左上角的偏移 即
self.grid_cell,三次检测所需的缩放尺度self.stride_tensor,以及 预先设的anchor box的宽和高 即
self.all_anchors_wh 。
def create_grid(self, input_size):
total_grid_xy = []
total_stride = []
total_anchor_wh = []
w, h = input_size[1], input_size[0]
for ind, s in enumerate(self.stride):
# generate grid cells
ws, hs = w // s, h // s
grid_y, grid_x = torch.meshgrid([torch.arange(hs), torch.arange(ws)])
grid_xy = torch.stack([grid_x, grid_y], dim=-1).float()
grid_xy = grid_xy.view(1, hs * ws, 1, 2)
# generate stride tensor
stride_tensor = torch.ones([1, hs * ws, self.anchor_number, 2]) * s
# generate anchor_wh tensor
anchor_wh = self.anchor_size[ind].repeat(hs * ws, 1, 1)
total_grid_xy.append(grid_xy)
total_stride.append(stride_tensor)
total_anchor_wh.append(anchor_wh)
total_grid_xy = torch.cat(total_grid_xy, dim=1).to(self.device)
total_stride = torch.cat(total_stride, dim=1).to(self.device)
total_anchor_wh = torch.cat(total_anchor_wh, dim=0).to(self.device).unsqueeze(0)
return total_grid_xy, total_stride, total_anchor_wh
if __name__ == '__main':
self.stride = [8, 16, 32]
self.anchor_size = torch.tensor(anchor_size).view(3, len(anchor_size) // 3, 2)
self.grid_cell, self.stride_tensor, self.all_anchors_wh = self.create_grid(input_size)2. 然后需要将[tx, ty, tw, th]解码成 [bx, by, bw, bh] 的形式:
def decode_xywh(self, txtytwth_pred):
"""
Input:
txtytwth_pred : [B, H*W, anchor_n, 4] containing [tx, ty, tw, th]
Output:
xywh_pred : [B, H*W*anchor_n, 4] containing [x, y, w, h]
"""
# b_x = sigmoid(tx) + gride_x, b_y = sigmoid(ty) + gride_y
B, HW, ab_n, _ = txtytwth_pred.size()
c_xy_pred = (torch.sigmoid(txtytwth_pred[:, :, :, :2]) + self.grid_cell) * self.stride_tensor
# b_w = anchor_w * exp(tw), b_h = anchor_h * exp(th)
b_wh_pred = torch.exp(txtytwth_pred[:, :, :, 2:]) * self.all_anchors_wh
# [B, H*W, anchor_n, 4] -> [B, H*W*anchor_n, 4]
xywh_pred = torch.cat([c_xy_pred, b_wh_pred], -1).view(B, HW * ab_n, 4)
return xywh_pred
def decode_boxes(self, txtytwth_pred):
"""
Input:
txtytwth_pred : [B, H*W, anchor_n, 4] containing [tx, ty, tw, th]
Output:
x1y1x2y2_pred : [B, H*W, anchor_n, 4] containing [xmin, ymin, xmax, ymax]
"""
# [B, H*W*anchor_n, 4]
xywh_pred = self.decode_xywh(txtytwth_pred)
# [center_x, center_y, w, h] -> [xmin, ymin, xmax, ymax]
x1y1x2y2_pred = torch.zeros_like(xywh_pred)
x1y1x2y2_pred[:, :, 0] = (xywh_pred[:, :, 0] - xywh_pred[:, :, 2] / 2)
x1y1x2y2_pred[:, :, 1] = (xywh_pred[:, :, 1] - xywh_pred[:, :, 3] / 2)
x1y1x2y2_pred[:, :, 2] = (xywh_pred[:, :, 0] + xywh_pred[:, :, 2] / 2)
x1y1x2y2_pred[:, :, 3] = (xywh_pred[:, :, 1] + xywh_pred[:, :, 3] / 2)
return x1y1x2y2_pred
if __name__ == '__main__':
decode_boxes(txtytwth_pred)公式中为何使用sigmoid函数呢?
YOLO不预测边界框中心的绝对坐标,它预测的是偏移量,预测的结果通过一个sigmoid函数,迫使输出的值在0~1之间。例如,若对中心的预测是(0.4,0.7),左上角坐标是(6,6),那么中心位于13×13特征地图上的(6.4,6.7)。若预测的x,y坐标大于1,比如(1.2,0.7),则中心位于(7.2,6.7)。注意现在中心位于图像的第7排第8列单元格,这打破了YOLO背后的理论,因为如果假设原区域负责预测某个目标,目标的中心必须位于这个区域中,而不是位于此区域旁边的其他网格里。为解决这个问题,输出是通过一个sigmoid函数传递的,该函数在0到1的范围内缩放输出,有效地将中心保持在预测的网格中。
预测推理阶段时,根据 这4个offsets,和
(是已知的)及上图的回归公式倒推出最终得到的边框坐标值是
,即边界框bboxes相对于feature maps的位置和大小,是我们需要的预测输出坐标。最后再乘以stride再乘以原始图像的宽高就得到原图上的预测框。
其实图像在输入之前是按照图像的长边缩放为416,短边根据比例缩放(图像不会变形扭曲),然后再对短边的两侧填充至416,这样就保证了输入图像是416*416的。
注意点:loss计算时 anchor box与ground truth的匹配。
为啥需要匹配呢?你是监督学习,那得知道网络预测的结果是啥呀?这样才能逼近真实的label,反过来就是我现在让他们匹配,给他分配好label,后面就让网络一直这样学习,最后就是以假乱真了,输出的结果无线接近正确结果了。yolov3的输出prediction的shape为(num_samples, self.num_anchors*(self.num_classes + 5), grid_size, grid_size),为了计算loss,转换为(num_samples, self.num_anchors, grid_size, grid_size, 5+self.num_classes ), 其中self.num_anchors为3, 总共这么多boxes,哪些框可能有目标呢,而且一个cell对应有三个anchor boxes,究竟选择哪个anchor去匹配ground truth?
将每个锚框(anchor boxes)视为一个训练样本,需要标记每个anchor box的标签,即类别标签和偏移量。所以我们只需要考虑有目标的anchor boxes,哪些有目标呢?ground truth的中心落在哪个cell,那对应这三个anchor boxes就有,所以计算ground truth与anchor boxeses的IOU(bbox_wh_iou(计算Gw,Gh与Pw,Ph的IOU)),其实只需要选取重叠度最高的anchor box就行,再将三个anchores通过torch.stack后max(0)下就知道选择三个中的哪个了,将这种方式匹配到的boxes视为有目标的box。请看源代码进行理解。
接下来我们来对比一下Faster RCNN和YOLOV3的anchor之间的差别(代码分析):
Faster-RCNN产生anchor boxes的代码:
import numpy as np
def generate_anchors(base_size=16, ratios=[0.5, 1, 2],
scales=2**np.arange(3, 6)):
"""
Generate anchor (reference) windows by enumerating aspect ratios X
scales wrt a reference (0, 0, 15, 15) window.
"""
base_anchor = np.array([1, 1, base_size, base_size]) - 1
ratio_anchors = _ratio_enum(base_anchor, ratios)
anchors = np.vstack([_scale_enum(ratio_anchors[i, :], scales)
for i in xrange(ratio_anchors.shape[0])])
return anchors
def _whctrs(anchor):
"""
Return width, height, x center, and y center for an anchor (window).
"""
w = anchor[2] - anchor[0] + 1
h = anchor[3] - anchor[1] + 1
x_ctr = anchor[0] + 0.5 * (w - 1)
y_ctr = anchor[1] + 0.5 * (h - 1)
return w, h, x_ctr, y_ctr
def _mkanchors(ws, hs, x_ctr, y_ctr):
"""
Given a vector of widths (ws) and heights (hs) around a center
(x_ctr, y_ctr), output a set of anchors (windows).
"""
ws = ws[:, np.newaxis]
hs = hs[:, np.newaxis]
anchors = np.hstack((x_ctr - 0.5 * (ws - 1),
y_ctr - 0.5 * (hs - 1),
x_ctr + 0.5 * (ws - 1),
y_ctr + 0.5 * (hs - 1)))
return anchors
def _ratio_enum(anchor, ratios):
"""
Enumerate a set of anchors for each aspect ratio wrt an anchor.
"""
w, h, x_ctr, y_ctr = _whctrs(anchor)
size = w * h
size_ratios = size / ratios
ws = np.round(np.sqrt(size_ratios))
hs = np.round(ws * ratios)
anchors = _mkanchors(ws, hs, x_ctr, y_ctr)
return anchors
def _scale_enum(anchor, scales):
"""
Enumerate a set of anchors for each scale wrt an anchor.
"""
w, h, x_ctr, y_ctr = _whctrs(anchor)
ws = w * scales
hs = h * scales
anchors = _mkanchors(ws, hs, x_ctr, y_ctr)
return anchors
if __name__ == '__main__':
import time
t = time.time()
a = generate_anchors()
print time.time() - t
print a
from IPython import embed; embed()代码的意思简单来说就是实现:
- 初始的框是(0,0,15,15),之后根据_ratio_enum生成三个中心坐标不变(只改变长宽比,分别为0.5,1,2),但是ratio改变的anchors. 如下图:
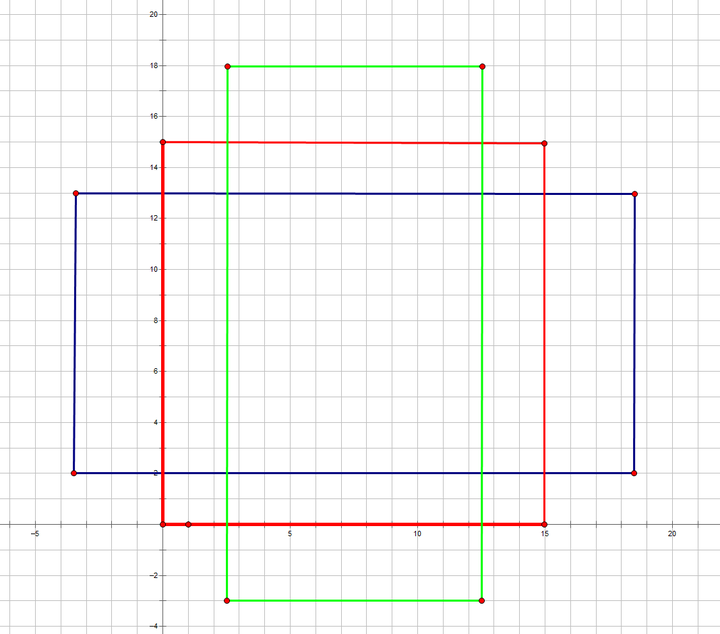
2. 三个不同ratio的anchors再分别_scale_enum生成不同尺寸的anchors,最后产生三种尺度三种比例的9个anchors(图中只画出了红色框产生的3个anchors,其他的两种颜色类似),如下图:
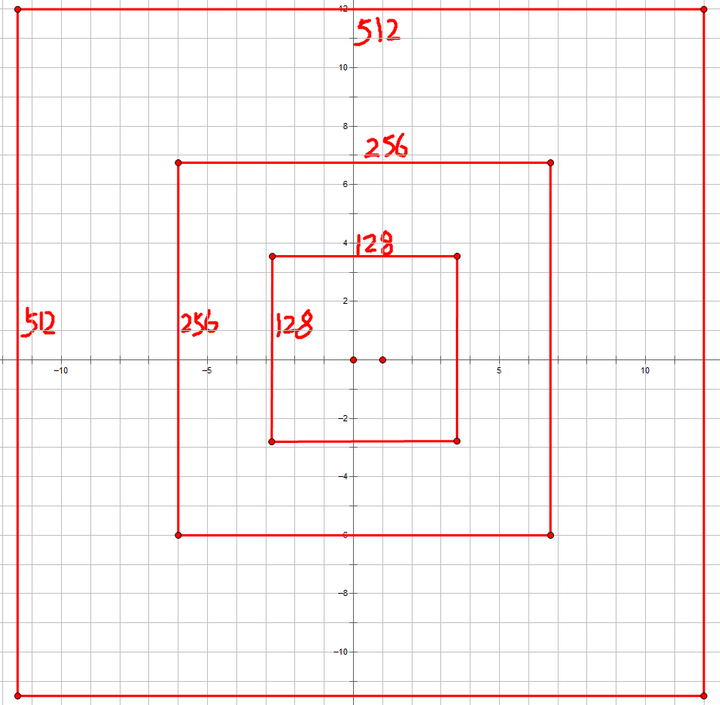
Faster-RCNN产生的anchor作用用一张图对照原论文可以很容易的看懂,如下图:

16是网络下采样的倍数,把9个anchor放在原图(600x800)上移动,stride为16(x,y方向都是16),最后得到右边红色的图,一共17100个anchor boxes。
YOLOv3的anchor代码:
import glob
import os
import sys
import xml.etree.ElementTree as ET
import numpy as np
from kmeans import kmeans, avg_iou
# 根文件夹
ROOT_PATH = '/data/'
# 聚类的数目
CLUSTERS = 6
# 模型中图像的输入尺寸,默认是一样的
SIZE = 640
# 需要加载yolo训练数据和lable
def load_dataset(path):
jpegimages = os.path.join(path, 'JPEGImages')
if not os.path.exists(jpegimages):
print('no JPEGImages folders, program abort')
sys.exit(0)
labels_txt = os.path.join(path, 'labels')
if not os.path.exists(labels_txt):
print('no labels folders, program abort')
sys.exit(0)
label_file = os.listdir(labels_txt)
print('label count: {}'.format(len(label_file)))
dataset = []
for label in label_file:
with open(os.path.join(labels_txt, label), 'r') as f:
txt_content = f.readlines()
for line in txt_content:
line_split = line.split(' ')
roi_with = float(line_split[len(line_split)-2])
roi_height = float(line_split[len(line_split)-1])
if roi_with == 0 or roi_height == 0:
continue
dataset.append([roi_with, roi_height])
# print([roi_with, roi_height])
return np.array(dataset)
data = load_dataset(ROOT_PATH)
out = kmeans(data, k=CLUSTERS) #对训练样本聚类
print(out)
print("Accuracy: {:.2f}%".format(avg_iou(data, out) * 100))
print("Boxes:\n {}-{}".format(out[:, 0] * SIZE, out[:, 1] * SIZE))
ratios = np.around(out[:, 0] / out[:, 1], decimals=2).tolist()
print("Ratios:\n {}".format(sorted(ratios)))可以看到yolov3是直接对你的训练样本进行k-means聚类,由训练样本得来的先验框(anchor boxes),也就是对样本聚类的结果。
2.3 多尺度预测:更好地对应不同大小的目标物体
每种尺度预测3个box, anchor的设计方式仍然使用聚类,得到9个聚类中心,将其按照大小均分给3个尺度.
- 尺度1: 在基础网络之后添加一些卷积层再输出box信息.
- 尺度2: 从尺度1中的倒数第二层的卷积层上采样(x2)再与最后一个16x16大小的特征图相加,再次通过多个卷积后输出box信息.相比尺度1变大两倍.
- 尺度3: 与尺度2类似,使用了32x32大小的特征图.
参见网络结构定义文件yolov3.cfg
通常一幅图像包含各种不同的物体,并且有大有小。比较理想的是一次就可以将所有大小的物体同时检测出来。因此,网络必须具备能够“看到”不同大小的物体的能力。并且网络越深,特征图就会越小,所以越往后小的物体也就越难检测出来。SSD中的做法是,在不同深度的feature map获得后,直接进行目标检测,这样小的物体会在相对较大的feature map中被检测出来,而大的物体会在相对较小的feature map被检测出来,从而达到对应不同scale的物体的目的。
然而在实际的feature map中,深度不同所对应的feature map包含的信息就不是绝对相同的。举例说明,随着网络深度的加深,浅层的feature map中主要包含低级的信息(物体边缘,颜色,初级位置信息等),深层的feature map中包含高等信息(例如物体的语义信息:狗,猫,汽车等等)。因此在不同级别的feature map中进行检测,听起来好像可以对应不同的scale,但是实际上精度并没有期待的那么高。
在YOLOv3中,这一点是通过采用FPN结构来提高对应多重scale的精度的。
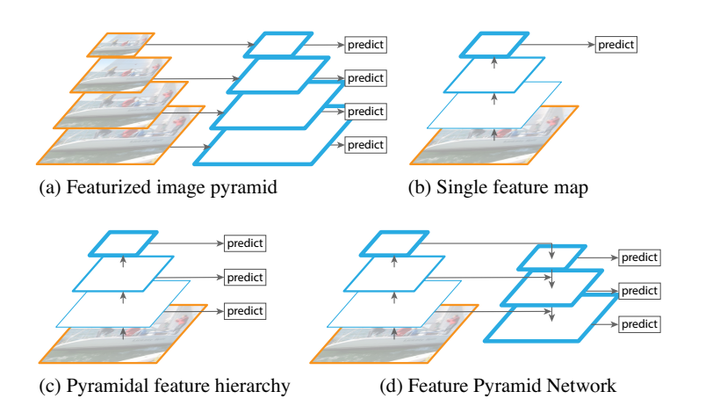
如上图所示,对于多重scale,目前主要有以下几种主流方法。
(a) Featurized image pyramid: 这种方法最直观。首先对于一幅图像建立图像金字塔,不同级别的金字塔图像被输入到对应的网络当中,用于不同scale物体的检测。但这样做的结果就是每个级别的金字塔都需要进行一次处理,速度很慢。
(b) Single feature map: 检测只在最后一个feature map阶段进行,这个结构无法检测不同大小的物体。
(c) Pyramidal feature hierarchy: 对不同深度的feature map分别进行目标检测。SSD中采用的便是这样的结构。每一个feature map获得的信息仅来源于之前的层,之后的层的特征信息无法获取并加以利用。
(d) Feature Pyramid Network 与(c)很接近,但有一点不同的是,当前层的feature map会对未来层的feature map进行上采样,并加以利用。这是一个有跨越性的设计。因为有了这样一个结构,当前的feature map就可以获得“未来”层的信息,这样的话低阶特征与高阶特征就有机融合起来了,提升检测精度。
2.4 ResNet残差结构:更好地获取物体特征
YOLOv3中使用了ResNet结构(对应着在上面的YOLOv3结构图中的Residual Block)。Residual Block是有一系列卷基层和一条shortcut path组成。shortcut如下图所示。
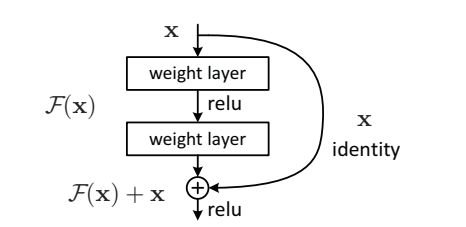 Residual Block
Residual Block
图中曲线箭头代表的便是shortcut path。除此之外,此结构与普通的CNN结构并无区别。随着网络越来越深,学习特征的难度也就越来越大。但是如果我们加一条shortcut path的话,学习过程就从直接学习特征,变成在之前学习的特征的基础上添加某些特征,来获得更好的特征。这样一来,一个复杂的特征H(x),之前是独立一层一层学习的,现在就变成了这样一个模型。H(x)=F(x)+x,其中x是shortcut开始时的特征,而F(x)就是对x进行的填补与增加,成为残差。因此学习的目标就从学习完整的信息,变成学习残差了。这样以来学习优质特征的难度就大大减小了。
2.5 替换softmax层:对应多重label分类
Softmax层被替换为一个1x1的卷积层+logistic激活函数的结构。使用softmax层的时候其实已经假设每个输出仅对应某一个单个的class,但是在某些class存在重叠情况(例如woman和person)的数据集中,使用softmax就不能使网络对数据进行很好的拟合。
2.6 改进之处
- 多尺度预测 (引入FPN)。
- 更好的基础分类网络(darknet-53, 类似于ResNet引入残差结构)。
- 分类器不在使用Softmax,分类损失采用binary cross-entropy loss(二分类交叉损失熵)
YOLOv3不使用Softmax对每个框进行分类,主要考虑因素有两个:
- Softmax使得每个框分配一个类别(score最大的一个),而对于Open Images这种数据集,目标可能有重叠的类别标签,因此Softmax不适用于多标签分类。
- Softmax可被独立的多个logistic分类器替代,且准确率不会下降。
分类损失采用binary cross-entropy loss。
YOLOv3中Loss部分计算
YOLOv1是一个anchor-free的,从YOLOv2开始引入了Anchor,在VOC2007数据集上将mAP提升了10个百分点。YOLOv3也继续使用了Anchor,本文主要讲ultralytics版YOLOv3的Loss部分的计算, 实际上这部分loss和原版差距非常大,并且可以通过arc指定loss的构建方式, 如果想看原版的loss可以在下方release的v6中下载源码。
Github地址: https://github.com/ultralytics/yolov3
Github release: https://github.com/ultralytics/yolov3/releases
1. Anchor
Faster R-CNN中Anchor的大小和比例是由人手工设计的,可能并不贴合数据集,有可能会给模型性能带来负面影响。YOLOv2和YOLOv3则是通过聚类算法得到最适合的k个框。聚类距离是通过IoU来定义,IoU越大,边框距离越近。
Anchor越多,平均IoU会越大,效果越好,但是会带来计算量上的负担,下图是YOLOv2论文中的聚类数量和平均IoU的关系图,在YOLOv2中选择了5个anchor作为精度和速度的平衡。
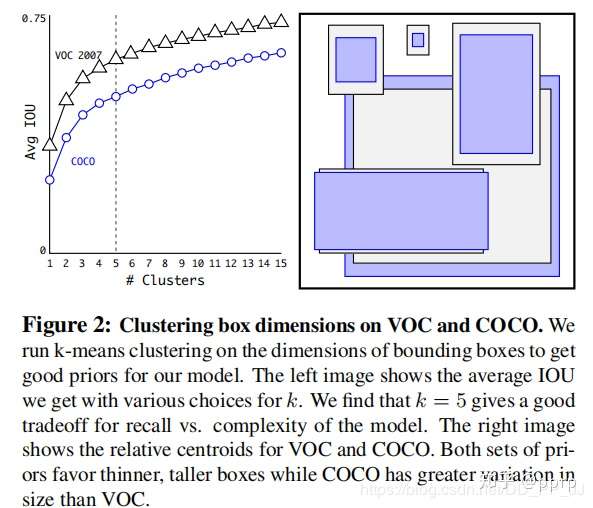
2. 偏移公式
在Faster RCNN中,中心坐标的偏移公式是:
其中、
代表中心坐标,
和
代表宽和高,
和
是模型预测的Anchor相对于Ground Truth的偏移量,通过计算得到的x,y就是最终预测框的中心坐标。
而在YOLOv2和YOLOv3中,对偏移量进行了限制,如果不限制偏移量,那么边框的中心可以在图像任何位置,可能导致训练的不稳定。
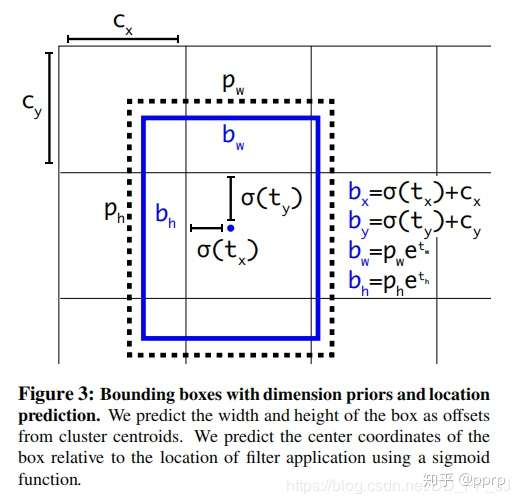
对照上图进行理解:
和
分别代表中心点所处区域的左上角坐标。
和
分别代表Anchor的宽和高。
和
分别代表预测框中心点和左上角的距离,
代表sigmoid函数,将偏移量限制在当前grid中,有利于模型收敛。
和
代表预测的宽高偏移量,Anchor的宽和高乘上指数化后的宽高,对Anchor的长宽进行调整。
是置信度预测值,是当前框有目标的概率乘以bounding box和ground truth的IoU的结果
3. Loss
YOLOv3中有一个参数是ignore_thresh,在ultralytics版版的YOLOv3中对应的是train.py文件中的iou_t参数(默认为0.225)。
正负样本是按照以下规则决定的:
- 如果一个预测框与所有的Ground Truth的最大IoU<ignore_thresh时,那这个预测框就是负样本。
- 如果Ground Truth的中心点落在一个区域中,该区域就负责检测该物体。将与该物体有最大IoU的预测框作为正样本(注意这里没有用到ignore thresh,即使该最大IoU<ignore thresh也不会影响该预测框为正样本)
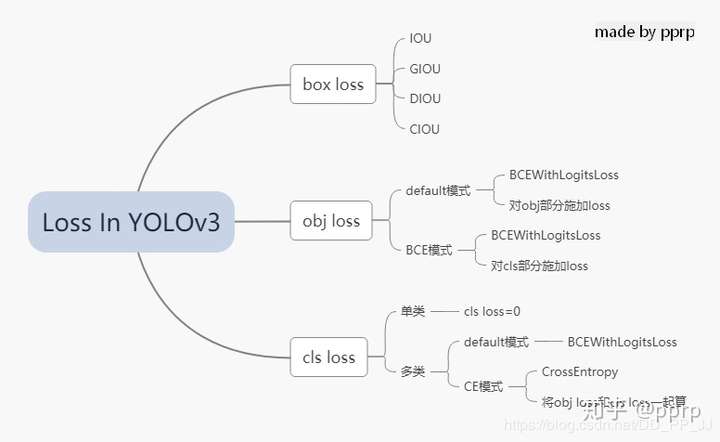
在YOLOv3中,Loss分为三个部分:
- 一个是xywh部分带来的误差,也就是bbox带来的loss
- 一个是置信度带来的误差,也就是obj带来的loss
- 最后一个是类别带来的误差,也就是class带来的loss
在代码中分别对应lbox, lobj, lcls,yolov3中使用的loss公式如下:
其中:
S: 代表grid size, 代表13x13,26x26, 52x52
B: box
: 如果在i,j处的box有目标,其值为1,否则为0
: 如果在i,j处的box没有目标,其值为1,否则为0
BCE(binary cross entropy)具体计算公式如下:
以上是论文中yolov3对应的darknet。而pytorch版本的yolov3改动比较大,有较大的改动空间,可以通过参数进行调整。
分成三个部分进行具体分析:
1. lbox部分
在ultralytics版版的YOLOv3中,使用的是GIOU,具体讲解见GIOU讲解链接。
简单来说是这样的公式,IoU公式如下:
而GIoU公式如下:
其中代表两个框最小闭包区域面积,也就是同时包含了预测框和真实框的最小框的面积。
yolov3中提供了IoU、GIoU、DIoU和CIoU等计算方式,以GIoU为例:
if GIoU: # Generalized IoU https://arxiv.org/pdf/1902.09630.pdf
c_area = cw * ch + 1e-16 # convex area
return iou - (c_area - union) / c_area # GIoU可以看到代码和GIoU公式是一致的,再来看一下lbox计算部分:
giou = bbox_iou(pbox.t(), tbox[i],
x1y1x2y2=False, GIoU=True)
lbox += (1.0 - giou).sum() if red == 'sum' else (1.0 - giou).mean()可以看到box的loss是1-giou的值。
2. lobj部分
lobj代表置信度,即该bounding box中是否含有物体的概率。在yolov3代码中obj loss可以通过arc来指定,有两种模式:
如果采用default模式,使用BCEWithLogitsLoss,将obj loss和cls loss分开计算:
BCEobj = nn.BCEWithLogitsLoss(pos_weight=ft([h['obj_pw']]), reduction=red)
if 'default' in arc: # separate obj and cls
lobj += BCEobj(pi[..., 4], tobj) # obj loss
# pi[...,4]对应的是该框中含有目标的置信度,和giou计算BCE
# 相当于将obj loss和cls loss分开计算如果采用BCE模式,使用的也是BCEWithLogitsLoss, 计算对象是所有的cls loss:
BCE = nn.BCEWithLogitsLoss(reduction=red)
elif 'BCE' in arc: # unified BCE (80 classes)
t = torch.zeros_like(pi[..., 5:]) # targets
if nb:
t[b, a, gj, gi, tcls[i]] = 1.0 # 对应正样本class置信度设置为1
lobj += BCE(pi[..., 5:], t)#pi[...,5:]对应的是所有的class3. lcls部分
如果是单类的情况,cls loss=0
如果是多类的情况,也分两个模式:
如果采用default模式,使用的是BCEWithLogitsLoss计算class loss。
BCEcls = nn.BCEWithLogitsLoss(pos_weight=ft([h['cls_pw']]), reduction=red)
# cls loss 只计算多类之间的loss,单类不进行计算
if 'default' in arc and model.nc > 1:
t = torch.zeros_like(ps[:, 5:]) # targets
t[range(nb), tcls[i]] = 1.0 # 设置对应class为1
lcls += BCEcls(ps[:, 5:], t) # 使用BCE计算分类loss如果采用CE模式,使用的是CrossEntropy同时计算obj loss和cls loss。
CE = nn.CrossEntropyLoss(reduction=red)
elif 'CE' in arc: # unified CE (1 background + 80 classes)
t = torch.zeros_like(pi[..., 0], dtype=torch.long) # targets
if nb:
t[b, a, gj, gi] = tcls[i] + 1 # 由于cls是从零开始计数的,所以+1
lcls += CE(pi[..., 4:].view(-1, model.nc + 1), t.view(-1))
# 这里将obj loss和cls loss一起计算,使用CrossEntropy Loss以上三部分总结下来就是下图:
4. 代码
ultralytics版版的yolov3的loss已经和论文中提出的部分大相径庭了,代码中很多地方地方是来自作者的经验。另外,这里读的代码是2020年2月份左右作者发布的版本,关注这个库的人会知道,作者更新速度非常快,在笔者写这篇文章的时候,loss也出现了大幅改动,添加了label smoothing等新的机制,去掉了通过arc来调整loss的机制,简化了loss部分。
这部分的代码添加了大量注释,很多是笔者通过debug得到的结果,理解的时候需要讲一下debug的配置:
- 单类数据集class=1
- batch size=2
- 模型是yolov3.cfg
计算loss这部分代码可以大概上分为两部分,一部分是正负样本选取,一部分是loss计算。
1. 正负样本选取部分
这部分主要工作是在每个yolo层将预设的anchor和ground truth进行匹配,得到正样本,回顾一下上文中在YOLOv3中正负样本选取规则:
- 如果一个预测框与所有的Ground Truth的最大IoU<ignore_thresh时,那这个预测框就是负样本。
- 如果Ground Truth的中心点落在一个区域中,该区域就负责检测该物体。将与该物体有最大IoU的预测框作为正样本(注意这里没有用到ignore thresh,即使该最大IoU<ignore thresh也不会影响该预测框为正样本)
def build_targets(model, targets):
# targets = [image, class, x, y, w, h]
# 这里的image是一个数字,代表是当前batch的第几个图片
# x,y,w,h都进行了归一化,除以了宽或者高
nt = len(targets)
tcls, tbox, indices, av = [], [], [], []
multi_gpu = type(model) in (nn.parallel.DataParallel,
nn.parallel.DistributedDataParallel)
reject, use_all_anchors = True, True
for i in model.yolo_layers:
# yolov3.cfg中有三个yolo层,这部分用于获取对应yolo层的grid尺寸和anchor大小
# ng 代表num of grid (13,13) anchor_vec [[x,y],[x,y]]
# 注意这里的anchor_vec: 假如现在是yolo第一个层(downsample rate=32)
# 这一层对应anchor为:[116, 90], [156, 198], [373, 326]
# anchor_vec实际值为以上除以32的结果:[3.6,2.8],[4.875,6.18],[11.6,10.1]
# 原图 416x416 对应的anchor为 [116, 90]
# 下采样32倍后 13x13 对应的anchor为 [3.6,2.8]
if multi_gpu:
ng = model.module.module_list[i].ng
anchor_vec = model.module.module_list[i].anchor_vec
else:
ng = model.module_list[i].ng,
anchor_vec = model.module_list[i].anchor_vec
# iou of targets-anchors
# targets中保存的是ground truth
t, a = targets, []
gwh = t[:, 4:6] * ng[0]
if nt: # 如果存在目标
# anchor_vec: shape = [3, 2] 代表3个anchor
# gwh: shape = [2, 2] 代表 2个ground truth
# iou: shape = [3, 2] 代表 3个anchor与对应的两个ground truth的iou
iou = wh_iou(anchor_vec, gwh) # 计算先验框和GT的iou
if use_all_anchors:
na = len(anchor_vec) # number of anchors
a = torch.arange(na).view(
(-1, 1)).repeat([1, nt]).view(-1) # 构造 3x2 -> view到6
# a = [0,0,1,1,2,2]
t = targets.repeat([na, 1])
# targets: [image, cls, x, y, w, h]
# 复制3个: shape[2,6] to shape[6,6]
gwh = gwh.repeat([na, 1])
# gwh shape:[6,2]
else: # use best anchor only
iou, a = iou.max(0) # best iou and anchor
# 取iou最大值是darknet的默认做法,返回的a是下角标
# reject anchors below iou_thres (OPTIONAL, increases P, lowers R)
if reject:
# 在这里将所有阈值小于ignore thresh的去掉
j = iou.view(-1) > model.hyp['iou_t']
# iou threshold hyperparameter
t, a, gwh = t[j], a[j], gwh[j]
# Indices
b, c = t[:, :2].long().t() # target image, class
# 取的是targets[image, class, x,y,w,h]中 [image, class]
gxy = t[:, 2:4] * ng[0] # grid x, y
gi, gj = gxy.long().t() # grid x, y indices
# 注意这里通过long将其转化为整形,代表格子的左上角
indices.append((b, a, gj, gi))
# indice结构体保存内容为:
'''
b: 一个batch中的角标
a: 代表所选中的正样本的anchor的下角标
gj, gi: 代表所选中的grid的左上角坐标
'''
# Box
gxy -= gxy.floor() # xy
# 现在gxy保存的是偏移量,是需要YOLO进行拟合的对象
tbox.append(torch.cat((gxy, gwh), 1)) # xywh (grids)
# 保存对应偏移量和宽高(对应13x13大小的)
av.append(anchor_vec[a]) # anchor vec
# av 是anchor vec的缩写,保存的是匹配上的anchor的列表
# Class
tcls.append(c)
# tcls用于保存匹配上的类别列表
if c.shape[0]: # if any targets
assert c.max() < model.nc, 'Model accepts %g classes labeled from 0-%g, however you labelled a class %g. ' \
'See https://github.com/ultralytics/yolov3/wiki/Train-Custom-Data' % (
model.nc, model.nc - 1, c.max())
return tcls, tbox, indices, av梳理一下在每个YOLO层的匹配流程:
- 将ground truth和anchor进行匹配,得到iou
- 然后有两个方法匹配:
- 使用yolov3原版的匹配机制,仅仅选择iou最大的作为正样本
- 使用ultralytics版版yolov3的默认匹配机制,use_all_anchors=True的时候,选择所有的匹配对
- 对以上匹配的部分在进行筛选,对应原版yolo中ignore_thresh部分,将以上匹配到的部分中iou<ignore_thresh的部分筛选掉。
- 最后将匹配得到的内容返回到compute_loss函数中。
2. loss计算部分
这部分就是yolov3中核心loss计算,这部分对照上文的讲解进行理解。
def compute_loss(p, targets, model):
# p: (bs, anchors, grid, grid, classes + xywh)
# predictions, targets, model
ft = torch.cuda.FloatTensor if p[0].is_cuda else torch.Tensor
lcls, lbox, lobj = ft([0]), ft([0]), ft([0])
tcls, tbox, indices, anchor_vec = build_targets(model, targets)
'''
以yolov3为例,有三个yolo层
tcls: 一个list保存三个tensor,每个tensor中有6(2个gtx3个anchor)个代表类别的数字
tbox: 一个list保存三个tensor,每个tensor形状[6,4],6(2个gtx3个anchor)个bbox
indices: 一个list保存三个tuple,每个tuple中保存4个tensor:
分别代表 b: 一个batch中的角标
a: 代表所选中的正样本的anchor的下角标
gj, gi: 代表所选中的grid的左上角坐标
anchor_vec: 一个list保存三个tensor,每个tensor形状[6,2],
6(2个gtx3个anchor)个anchor,注意大小是相对于13x13feature map的anchor大小
'''
h = model.hyp # hyperparameters
arc = model.arc # # (default, uCE, uBCE) detection architectures
# 具体使用的损失函数是通过arc参数决定的
red = 'sum' # Loss reduction (sum or mean)
# Define criteria
BCEcls = nn.BCEWithLogitsLoss(pos_weight=ft([h['cls_pw']]), reduction=red)
BCEobj = nn.BCEWithLogitsLoss(pos_weight=ft([h['obj_pw']]), reduction=red)
#BCEWithLogitsLoss = sigmoid + BCELoss
BCE = nn.BCEWithLogitsLoss(reduction=red)
CE = nn.CrossEntropyLoss(reduction=red) # weight=model.class_weights
# class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3
# cp, cn = smooth_BCE(eps=0.0)
# 这是最新的版本中提供了label smoothing的功能,只能用在多类问题
if 'F' in arc: # add focal loss
g = h['fl_gamma']
BCEcls, BCEobj, BCE, CE = FocalLoss(BCEcls, g), FocalLoss(
BCEobj, g), FocalLoss(BCE, g), FocalLoss(CE, g)
# focal loss可以用在cls loss或者obj loss
# Compute losses
np, ng = 0, 0 # number grid points, targets
# np这个命名真的迷,建议改一下和numpy缩写重复
for i, pi in enumerate(p): # layer index, layer predictions
# 在yolov3中,p有三个yolo layer的输出pi
# 形状为:(bs, anchors, grid, grid, classes + xywh)
b, a, gj, gi = indices[i] # image, anchor, gridy, gridx
tobj = torch.zeros_like(pi[..., 0])
# tobj = target obj, 形状为(bs, anchors, grid, grid)
np += tobj.numel() # 返回tobj中元素个数
# Compute losses
nb = len(b)
if nb:
ng += nb # number of targets 用于最后算平均loss
# (bs, anchors, grid, grid, classes + xywh)
ps = pi[b, a, gj, gi] # 即找到了对应目标的classes+xywh,形状为[6(2x3),6]
# GIoU
pxy = torch.sigmoid(
ps[:, 0:2] # 将x,y进行sigmoid
) # pxy = pxy * s - (s - 1) / 2, s = 1.5 (scale_xy)
pwh = torch.exp(ps[:, 2:4]).clamp(max=1E3) * anchor_vec[i]
# 防止溢出进行clamp操作,乘以13x13feature map对应的anchor
# 这部分和上文中偏移公式是一致的
pbox = torch.cat((pxy, pwh), 1) # predicted box
# pbox: predicted bbox shape:[6, 4]
giou = bbox_iou(pbox.t(), tbox[i], x1y1x2y2=False,
GIoU=True) # giou computation
# 计算giou loss, 形状为6
lbox += (1.0 - giou).sum() if red == 'sum' else (1.0 - giou).mean()
# bbox loss直接由giou决定
tobj[b, a, gj, gi] = giou.detach().type(tobj.dtype)
# target obj 用giou取代1,代表该点对应置信度
# cls loss 只计算多类之间的loss,单类不进行计算
if 'default' in arc and model.nc > 1:
t = torch.zeros_like(ps[:, 5:]) # targets
t[range(nb), tcls[i]] = 1.0 # 设置对应class为1
lcls += BCEcls(ps[:, 5:], t) # 使用BCE计算分类loss
if 'default' in arc: # separate obj and cls
lobj += BCEobj(pi[..., 4], tobj) # obj loss
# pi[...,4]对应的是该框中含有目标的置信度,和giou计算BCE
# 相当于将obj loss和cls loss分开计算
elif 'BCE' in arc: # unified BCE (80 classes)
t = torch.zeros_like(pi[..., 5:]) # targets
if nb:
t[b, a, gj, gi, tcls[i]] = 1.0 # 对应正样本class置信度设置为1
lobj += BCE(pi[..., 5:], t)
#pi[...,5:]对应的是所有的class
elif 'CE' in arc: # unified CE (1 background + 80 classes)
t = torch.zeros_like(pi[..., 0], dtype=torch.long) # targets
if nb:
t[b, a, gj, gi] = tcls[i] + 1 # 由于cls是从零开始计数的,所以+1
lcls += CE(pi[..., 4:].view(-1, model.nc + 1), t.view(-1))
# 这里将obj loss和cls loss一起计算,使用CrossEntropy Loss
# 使用对应的权重来平衡,这个参数是作者通过参数搜索(random search)的方法搜索得到的
lbox *= h['giou']
lobj *= h['obj']
lcls *= h['cls']
if red == 'sum':
bs = tobj.shape[0] # batch size
lobj *= 3 / (6300 * bs) * 2
# 6300 = (10 ** 2 + 20 ** 2 + 40 ** 2) * 3
# 输入为320x320的图片,则存在6300个anchor
# 3代表3个yolo层, 2是一个超参数,通过实验获取
# 如果不想计算的话,可以修改red='mean'
if ng:
lcls *= 3 / ng / model.nc
lbox *= 3 / ng
loss = lbox + lobj + lcls
return loss, torch.cat((lbox, lobj, lcls, loss)).detach()需要注意的是,三个部分的loss的平衡权重不是按照yolov3原文的设置来做的,是通过超参数进化来搜索得到的,具体请看:【从零开始学习YOLOv3】4. YOLOv3中的参数进化
5. 补充
补充一下BCEWithLogitsLoss的用法,在这之前先看一下BCELoss:
torch.nn.BCELoss的功能是二分类任务是的交叉熵计算函数,可以认为是CrossEntropy的特例。其分类限定为二分类,y的值必须为{0,1},input应该是概率分布的形式。在使用BCELoss前一般会先加一个sigmoid激活层,常用在自编码器中。
计算公式:
是每个类别的loss权重,用于类别不均衡问题。
torch.nn.BCEWithLogitsLoss的相当于Sigmoid+BCELoss, 即input会经过Sigmoid激活函数,将input变为概率分布的形式。
计算公式:
YOLO中比较难理解的就是置信度,在训练阶段置信度取决于anchor是否有物体和iou的值,对于同一组的也就是特征图同一个位置产生的多个(3个)候选框都含有前景,那么选取iou最大的框设置置信度为1其余的位0,注意如果框内没有前景一定为0,在测试的时候因为没有iou,所以就取决与置信分数来删除多有的框和使用nms来删框简化预测输出。通过map计算最终检测的效果。下面详细补充一下这部分内容。
目标检测之详解yolov3的anchor、置信度和类别概率




yolov3做非极大值抑制

使用Facol loss解决样本比例失调的问题
1. 总述
Focal loss主要是为了解决one-stage目标检测中正负样本比例严重失衡的问题。该损失函数降低了大量简单负样本在训练中所占的权重,也可理解为一种困难样本挖掘。
2. 损失函数形式
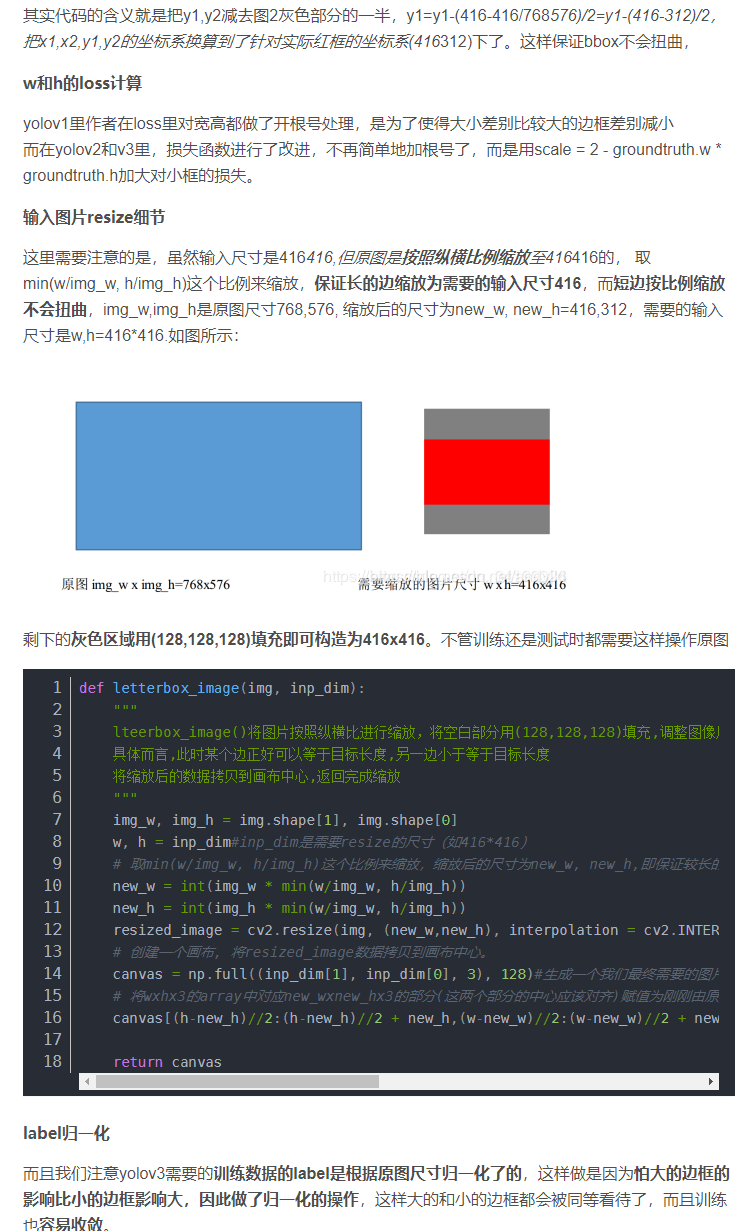
Focal loss是在交叉熵损失函数基础上进行的修改,首先回顾二分类交叉上损失:
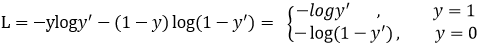
 是经过激活函数的输出,所以在0-1之间。可见普通的交叉熵对于正样本而言,输出概率越大损失越小。对于负样本而言,输出概率越小则损失越小。此时的损失函数在大量简单样本的迭代过程中比较缓慢且可能无法优化至最优。那么Focal loss是怎么改进的呢?
是经过激活函数的输出,所以在0-1之间。可见普通的交叉熵对于正样本而言,输出概率越大损失越小。对于负样本而言,输出概率越小则损失越小。此时的损失函数在大量简单样本的迭代过程中比较缓慢且可能无法优化至最优。那么Focal loss是怎么改进的呢?

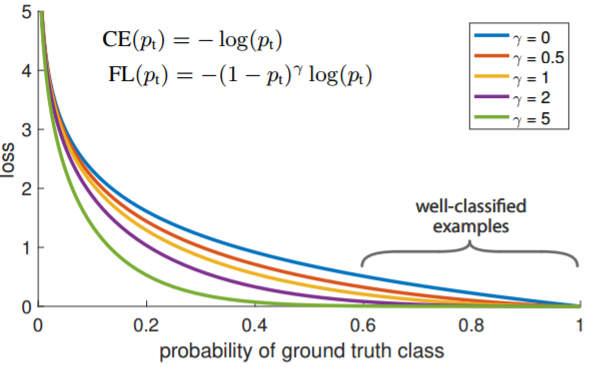
首先在原有的基础上加了一个因子,其中gamma>0使得减少易分类样本的损失。使得更关注于困难的、错分的样本。
例如gamma为2,对于正类样本而言,预测结果为0.95肯定是简单样本,所以(1-0.95)的gamma次方就会很小,这时损失函数值就变得更小。而预测概率为0.3的样本其损失相对很大。对于负类样本而言同样,预测0.1的结果应当远比预测0.7的样本损失值要小得多。对于预测概率为0.5时,损失只减少了0.25倍,所以更加关注于这种难以区分的样本。这样减少了简单样本的影响,大量预测概率很小的样本叠加起来后的效应才可能比较有效。
此外,加入平衡因子alpha,用来平衡正负样本本身的比例不均:文中alpha取0.25,即正样本要比负样本占比小,这是因为负例易分。
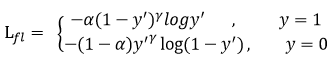
只添加alpha虽然可以平衡正负样本的重要性,但是无法解决简单与困难样本的问题。
gamma调节简单样本权重降低的速率,当gamma为0时即为交叉熵损失函数,当gamma增加时,调整因子的影响也在增加。实验发现gamma为2是最优。
3. 总结
作者认为one-stage和two-stage的表现差异主要原因是大量前景背景类别不平衡导致。作者设计了一个简单密集型网络RetinaNet来训练在保证速度的同时达到了精度最优。在双阶段算法中,在候选框阶段,通过得分和nms筛选过滤掉了大量的负样本,然后在分类回归阶段又固定了正负样本比例,或者通过OHEM在线困难挖掘使得前景和背景相对平衡。而one-stage阶段需要产生约100k的候选位置,虽然有类似的采样,但是训练仍然被大量负样本所主导。
yolov3应该是从代码方面解决样本不均衡问题,我没仔细看代码,(或者是直接忽视iou<0.5的负样本?但记得负样本的置信度是参与计算loss的啊。但毋庸置疑yolo3肯定解决了正负样本不均衡存在的问题)
MAP计算
看这个ppt


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!
· 零经验选手,Compose 一天开发一款小游戏!