吴恩达《深度学习》第四门课(2)卷积神经网络:实例探究
2.1为什么要进行实例探究
(1)就跟学编程一样,先看看别人怎么写的,可以模仿。
(2)在计算机视觉中一个有用的模型,,用在另一个业务中也一般有效,所以可以借鉴。
(3)本周会介绍的一些卷积方面的经典网络经典的包括:LeNet、AlexNet、VGG;流行的包括:ResNet、Inception,如下图:

2.2经典网络
(1)LeNet-5网络结构如下图所示:
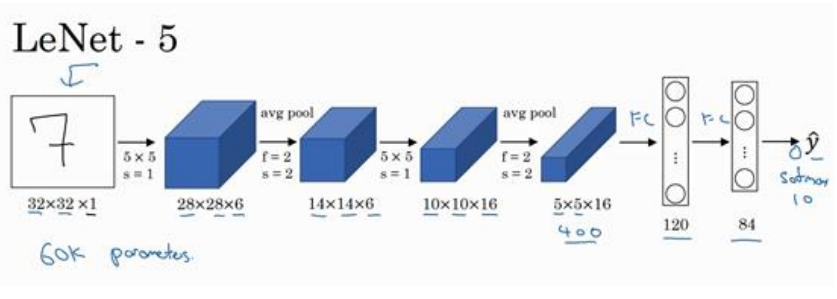
(2)在LeNet-5中的一些注意点:网络输入单通道的,大概有6万个参数,池化用的是平均池化而不是最大值池化,还没有用到padding,输出也不是现在的softmax,激活函数用的是sigmoid和tanh。综上可以看出来许多设置在今天看来都是不合适的了,说明网络在发展。
(3)AlexNet网络结构如下图所示:
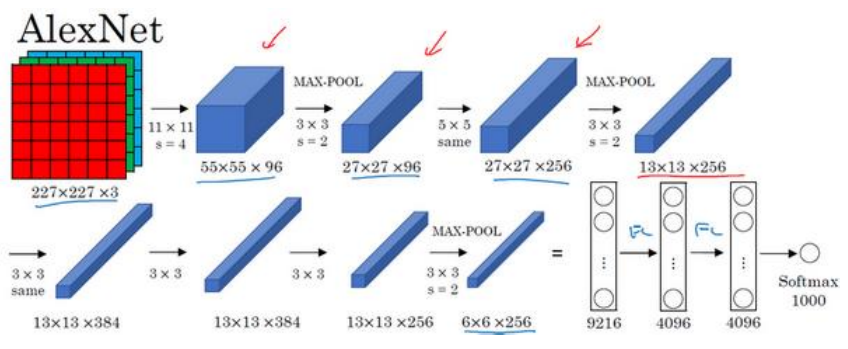
(4)AlexNet与LeNet-5有非常多相似之处,但前者的网络更深更大,参数达到6000万,同时使用了Relu激活函数。
(5)VGG-16网络结构如下图所示:
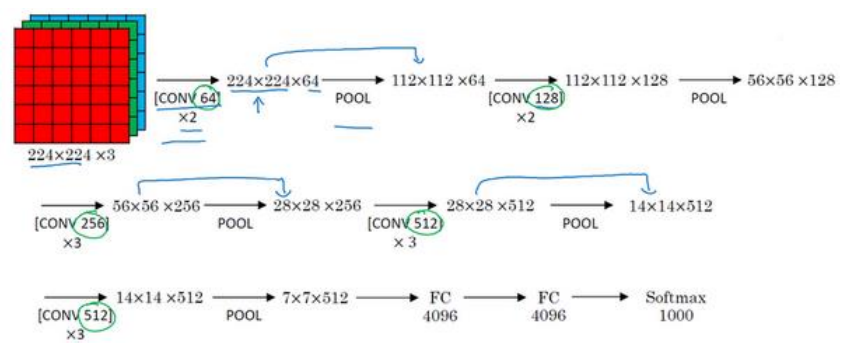
(6)VGG-16网络的说明:16代表卷积层加全连接层一共16层,图中的×2表示连续两次相同的卷积,所有卷积padding都是用了same,卷积核的个数都是成倍增加,而高宽刚好对半减小,真个网络非常简洁优美,网络参数非常多达到了1.38亿各参数,在今天看来依旧是非常大的网络。
2.3残差网络(Residual Networks(ResNets))
(1)一般正常的网络会进行如下操作:
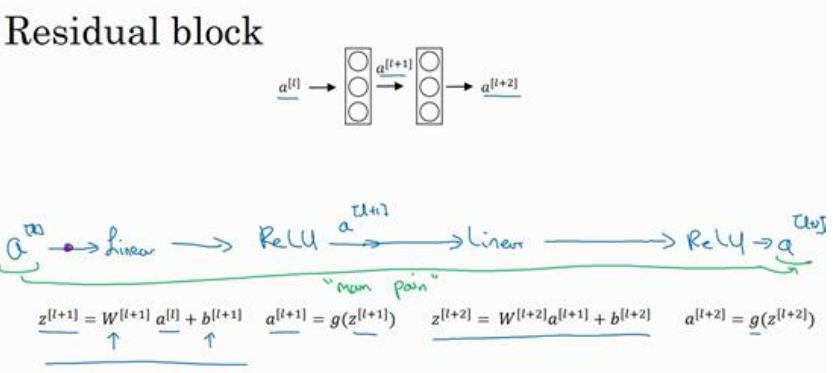
(2)然后将a[l]传到下下层的激活函数之前,即进行如下计算,就得到了残差块:
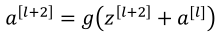
(3)以下是一个有五个残差块的网络:
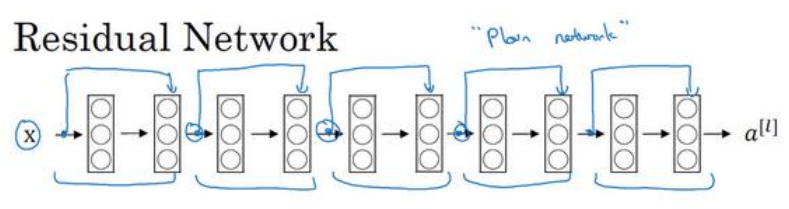
(4)残差网络克服了网络很深时存在的梯度消失或爆炸的问题。
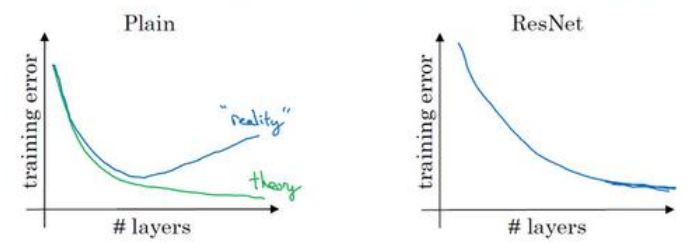
(5)下图展示了普通网络和残差网络随着网络深度训练误差的变化,普通网络由于网络很深之后难以训练所以训练误差变大了。
2.4残差网络有什么用
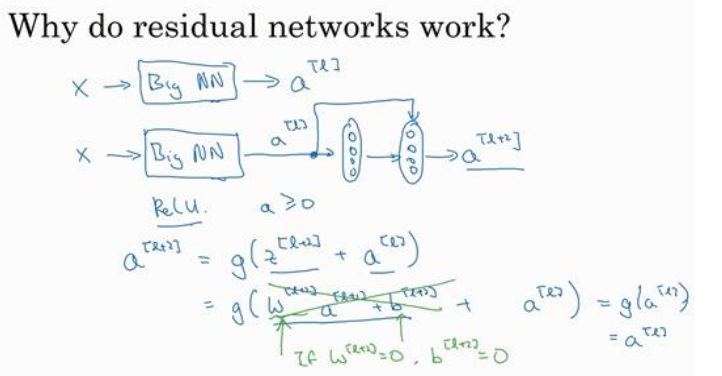
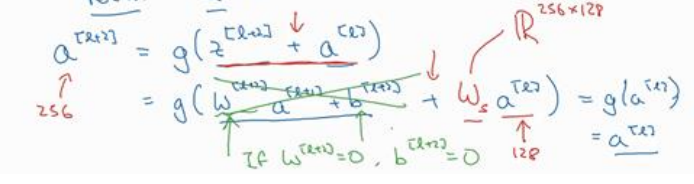
(1)因为残差网络很容易学习恒等式函数,所以随着网络加深,至少不会让网络变差。如下图中添加了两层,使用Relu激活函数,当W[l+2],b[l+2]都为0时,输出还是和不添加这两层的结果一样,都是a[l],这就是学习恒等式。
(2)另个一需要讨论的问题就是维度匹配问题,当z[l+2]和a[l]相同时,可以直接相加,如果不同时需要在让a[l]与矩阵Ws相乘,Ws的维度为(a[l+2],a[l]),如下图所示:
2.5网络中的网络以及1×1卷积
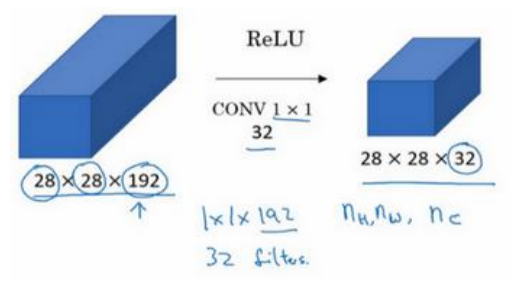
(1)1×1计算示意图如下所示:

(2)作用:首先相当于把一个点的所有通道进行了全连接操作;其次是起到压缩通道的作用(最重要的作用),或者保持不变,如下图所示。
2.6谷歌Inception网路简介
(1)构建卷积层时,你要决定使用多大的卷积核(如1×1,3×3,5×5等)或者要不要添加池化层,而Inception网络的Inception层作用就是它将替你做决定。
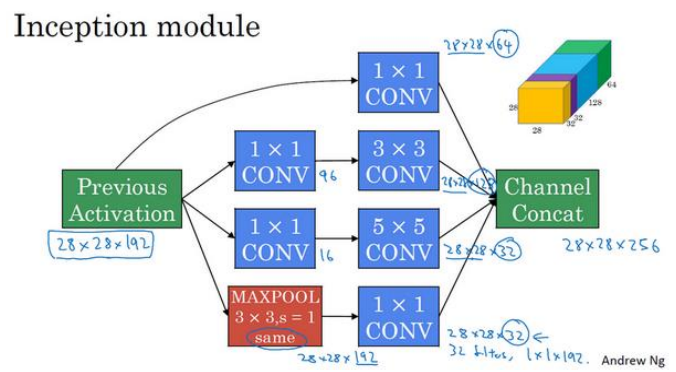
(2)下面就是一个典型的Inception模块的示意图:

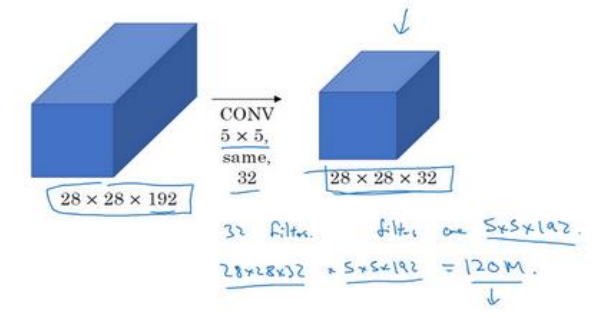
(3)用1×1卷积核来构建瓶颈层可以大大减少计算量:
首先是没有添加1×1卷积核如下图所示,由于加法的运算次数和乘法运算次数接近,所以这里只求乘法的计算次数:(5*5*192)*(28*28*32)=1.2亿
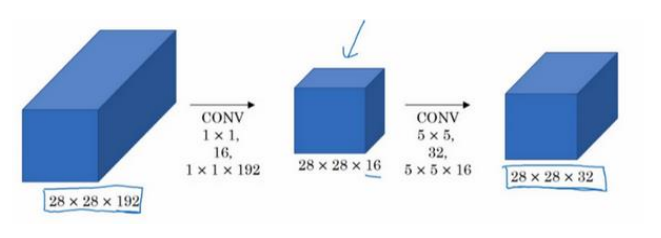
添加了卷积核之后,如下图所示,整个的输入输出是没有发生改变的,乘法计算量为(1*1*16)*(28*28*16)+(5*5*16)*(28*28*32)=1240万。只有上面的十分之一。所以计算量减少了很多,同时只要合理构建,不会影响网络性能。
2.7Inception网络
(1)下面是Inception的一个单元,需要注意的是池化时保持尺寸不变,同时池化不能改变通道数导致通道特别多,所以在其后面添加了1×1卷积核压缩通道。
(2)下面是一个完整的Inception网络,其中可以看到有一些分支,他们同样可以做最终输出预测,这样做是为了防止过拟合。
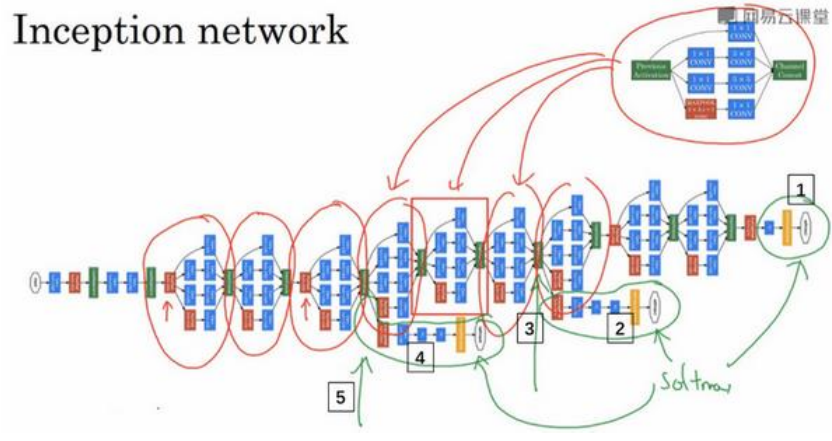
Inception知乎解析文章
2.8使用开源的实现方案
(1)在GitHub上找资源,然后在此基础上进行开发,会有更快的进展。
2.9迁移学习
(1)下载别人的模型,以前预训练的权重来初始化,同时将输出层根据自己的需要来修改,比如说分三种类别(已经包括其它了),那么输出为3个单元的sotfmax。如下图所示:
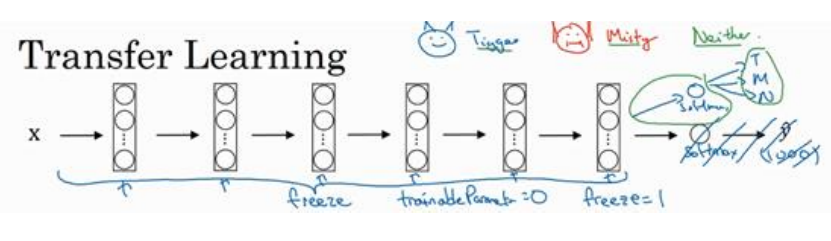
(2)冻结别人训练好的参数,在深度学习框架中可能参数是trainableParameter=0,或者freeze=1等,视实际框架而定。
(3)一个重要技巧是:数据量少时只训练最后一层,这时可以将图片输入,然后将最后一层前的输出存到硬盘中,因为这些值是不会改变的。然后在用这些值作为输入训练最后一层,这样不要每次都经过前面的网络,训练会大大加快。
(4)当数据量越来越大时,从后往前可以训练更多的层,极端情况下是所有层的参数都参与训练。
2.10数据扩充
(1)镜像、随机裁剪、旋转、剪切、扭曲
(2)色彩转换(如给一些通道加值)
(3)在实际使用过程中可以使用多线程,一些线程从硬盘中取出数据,然后进行数据扩充,再传入其他线程进行训练,这样就可以并行实现了。

2.11计算机视觉现状
(1)对于计算机视觉而言,其实当前的数据量是远远不够的,所以需要设计出一些更复杂的网络,以及人工去调整非常多的超参数,其本质都是因为数据量不够;假设数据量非常够的时候,网络也好,超参数也好都可以使用更简单的架构和调整。
(2)再次强调多多使用迁移学习,站在巨人的肩膀上。另外如果要自己设计研究全新的网络可能需要自己从头开始训练。
(3)为了在竞赛中取得好成绩,常常是以巨大的计算量为代价的(如用多个网络计算输出取平均),这在实际应用中不太实用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号