贝叶斯算法
贝叶斯介绍






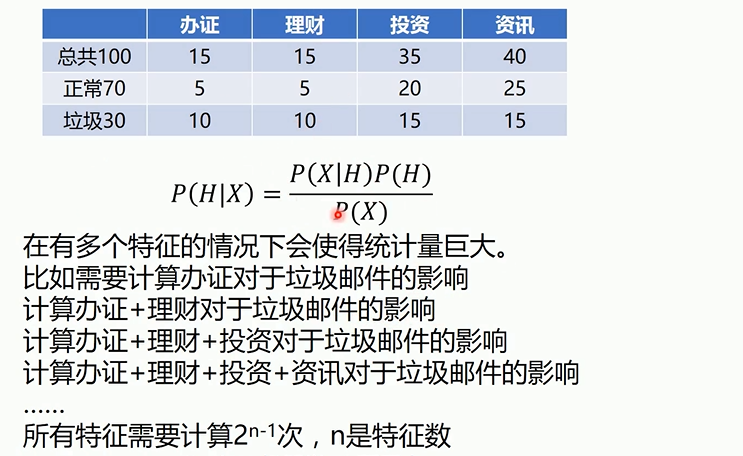


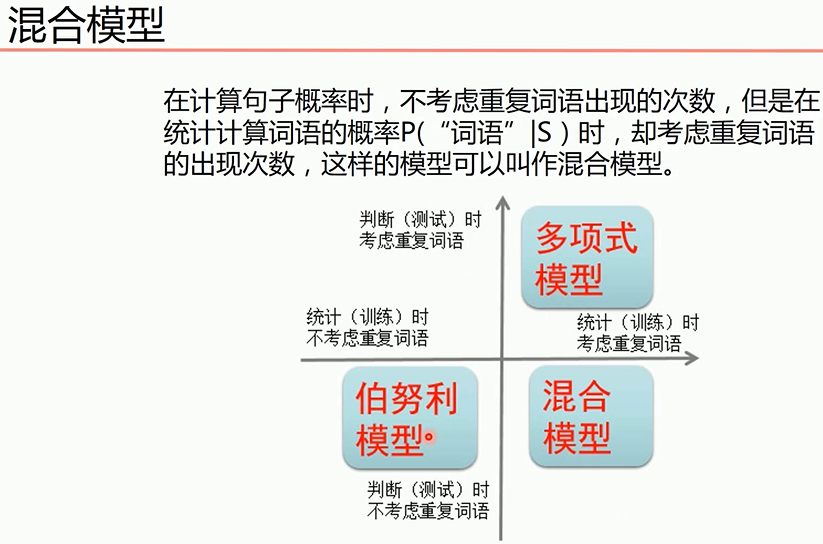

1 # 导入算法包以及数据集 2 import numpy as np 3 from sklearn import datasets 4 from sklearn.model_selection import train_test_split 5 from sklearn.metrics import classification_report,confusion_matrix 6 from sklearn.naive_bayes import MultinomialNB,BernoulliNB,GaussianNB#朴素贝叶斯的三种模型 7 # 载入数据 8 iris = datasets.load_iris() 9 x_train,x_test,y_train,y_test = train_test_split(iris.data, iris.target) 10 mul_nb = GaussianNB()#适合连续性数据,所以模型效果很好,其他两种则很差 11 mul_nb.fit(x_train,y_train) 12 print(classification_report(mul_nb.predict(x_test),y_test)) 13 print(confusion_matrix(mul_nb.predict(x_test),y_test)) 14 mul_nb = MultinomialNB() 15 mul_nb.fit(x_train,y_train) 16 print(classification_report(mul_nb.predict(x_test),y_test)) 17 print(confusion_matrix(mul_nb.predict(x_test),y_test)) 18 mul_nb = BernoulliNB() 19 mul_nb.fit(x_train,y_train) 20 print(classification_report(mul_nb.predict(x_test),y_test)) 21 print(confusion_matrix(mul_nb.predict(x_test),y_test))
词袋模型介绍
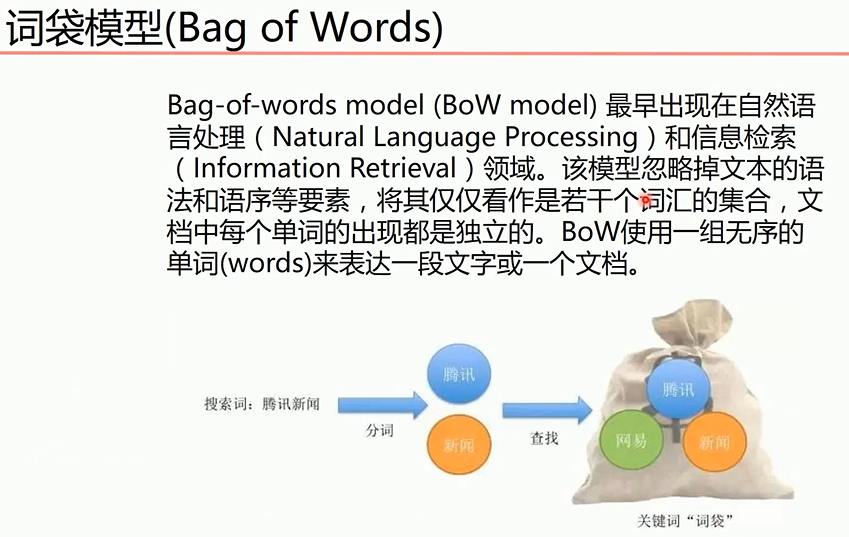

1 from sklearn.feature_extraction.text import CountVectorizer#向量化 2 3 texts=["dog cat fish","dog cat cat","fish bird", 'bird'] 4 cv = CountVectorizer() 5 cv_fit=cv.fit_transform(texts) 6 7 # 8 print(cv.get_feature_names()) 9 print(cv_fit.toarray()) 10 print(cv_fit.toarray().sum(axis=0)) 11 ''' 12 ['bird', 'cat', 'dog', 'fish'] 13 [[0 1 1 1] 14 [0 2 1 0] 15 [1 0 0 1] 16 [1 0 0 0]] 17 [2 3 2 2] 18 '''
TF-IDF算法介绍





1 from sklearn.feature_extraction.text import TfidfVectorizer 2 # 文本文档列表 3 text = ["The quick brown fox jumped over the lazy dog.", 4 "The dog.", 5 "The fox"] 6 # 创建变换函数 7 vectorizer = TfidfVectorizer() 8 # 词条化以及创建词汇表 9 vectorizer.fit(text) 10 # 总结 11 print(vectorizer.vocabulary_) 12 print(vectorizer.idf_) 13 # 编码文档 14 vector = vectorizer.transform([text[0]]) 15 # 总结编码文档 16 print(vector.shape) 17 print(vector.toarray())
作者:你的雷哥
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须在文章页面给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号