CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)概念区分理解
1、相关知识
从广义上来说,NN(或是更美的DNN)确实可以认为包含了CNN、RNN这些具体的变种形式。有很多人认为,它们并没有可比性,或是根本没必要放在一起比较。在实际应用中,所谓的深度神经网络DNN,往往融合了多种已知的结构,包括convolution layer 或是 LSTM 单元。其实,如果我们顺着神经网络技术发展的脉络,就很容易弄清这几种网络结构发明的初衷,和他们之间本质的区别。
2、神经网络发展2.1 感知机
神经网络技术起源于上世纪五、六十年代,当时叫感知机(perceptron),拥有输入层、输出层和一个隐含层。输入的特征向量通过隐含层变换达到输出层,在输出层得到分类结果。早期感知机的推动者是Rosenblatt。但是,Rosenblatt的单层感知机有一个严重得不能再严重的问题,对于计算稍微复杂的函数其计算力显得无能为力。
2.2 多层感知机的出现
随着数学的发展,这个缺点直到上世纪八十年代才被Rumelhart、Williams、Hinton、LeCun等人发明的多层感知机(multilayer perceptron)克服。多层感知机,顾名思义,就是有多个隐含层的感知机。我们看一下多层感知机的结构:
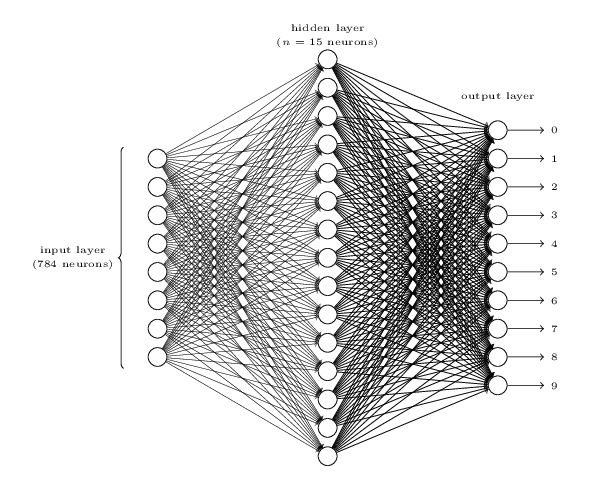
图1 :多层感知机(神经网络)
多层感知机可以摆脱早期离散传输函数的束缚,使用sigmoid或tanh等连续函数模拟神经元对激励的响应,在训练算法上则使用Werbos发明的反向传播BP算法。对,这就是我们现在所说的神经网络(NN)!多层感知机解决了之前无法模拟异或逻辑的缺陷,同时更多的层数也让网络更能够刻画现实世界中的复杂情形。多层感知机给我们带来的启示是,神经网络的层数直接决定了它对现实的刻画能力——利用每层更少的神经元拟合更加复杂的函数。
即便大牛们早就预料到神经网络需要变得更深,但是有一个梦魇总是萦绕左右。随着神经网络层数的加深,优化函数越来越容易陷入局部最优解,并且这个“陷阱”越来越偏离真正的全局最优。利用有限数据训练的深层网络,性能还不如较浅层网络。同时,另一个不可忽略的问题是随着网络层数增加,“梯度消失”现象更加严重。具体来说,我们常常使用 sigmoid作为神经元的输入输出函数。对于幅度为1的信号,在BP反向传播梯度时,每传递一层,梯度衰减为原来的0.25。层数一多,梯度指数衰减后低层基本上接受不到有效的训练信号。
2.3 (DNN)神经网络“具有深度”
2006年,Hinton利用预训练方法缓解了局部最优解问题,将隐含层推动到了7层(参考论文:Hinton G E, Salakhutdinov R R. Reducing the Dimensionality of Data with Neural Networks[J]. Science, 2006, 313(5786):504-507.),神经网络真正意义上有了“深度”,由此揭开了深度学习的热潮。这里的“深度”并没有固定的定义——在语音识别中4层网络就能够被认为是“较深的”,而在图像识别中20层以上的网络屡见不鲜。为了克服梯度消失,ReLU、maxout等传输函数代替了 sigmoid,形成了如今 DNN的基本形式。单从结构上来说,全连接的DNN和上图的多层感知机是没有任何区别的。值得一提的是,今年出现的高速公路网络(highway network)和深度残差学习(deep residual learning)进一步避免了梯度弥散问题,网络层数达到了前所未有的一百多层(深度残差学习:152层,具体去看何恺明大神的paper)!
2.4 CNN(卷积神经网络)的出现
如图1所示,我们看到全连接DNN的结构里下层神经元和所有上层神经元都能够形成连接,带来的潜在问题是参数数量的膨胀。假设输入的是一幅像素为1K*1K的图像,隐含层有1M个节点,光这一层就有10^12个权重需要训练,这不仅容易过拟合,而且极容易陷入局部最优。另外,图像中有固有的局部模式(比如轮廓、边界,人的眼睛、鼻子、嘴等)可以利用,显然应该将图像处理中的概念和神经网络技术相结合。此时我们可以祭出题主所说的卷积神经网络CNN。对于CNN来说,并不是所有上下层神经元都能直接相连,而是通过“卷积核”作为中介。同一个卷积核在所有图像内是共享的,图像通过卷积操作后仍然保留原先的位置关系。卷积层之间的卷积传输的示意图如下:
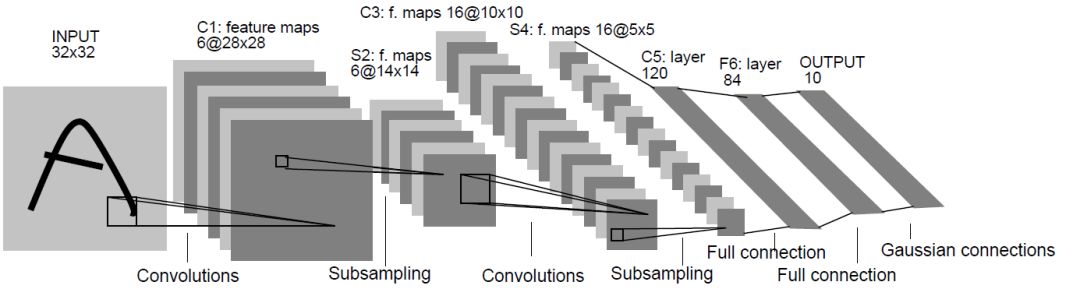
图2:LeNet-5
通过一个例子简单说明卷积神经网络的结构。假设我们需要识别一幅彩色图像,这幅图像具有四个通道 ARGB(透明度和红绿蓝,对应了四幅相同大小的图像),假设卷积核大小为 3∗3共使用100个卷积核w1到w100(从直觉来看,每个卷积核应该学习到不同的结构特征)。用w1在ARGB图像上进行卷积操作,可以得到隐含层的第一幅图像;这幅隐含层图像左上角第一个像素是四幅输入图像左上角 3∗3区域内像素的加权求和,以此类推。同理,算上其他卷积核,隐含层对应100幅“图像”。每幅图像对是对原始图像中不同特征的响应。按照这样的结构继续传递下去。CNN中还有 max-pooling等操作进一步提高鲁棒性。
本文来自 微信公众号 datadw 【大数据挖掘DT数据分析
我们注意到,对于图像,如果没有卷积操作,学习的参数量是灾难级的。CNN之所以用于图像识别,正是由于CNN模型限制了参数的个数并挖掘了局部结构的这个特点。顺着同样的思路,利用语音语谱结构中的局部信息,CNN照样能应用在语音识别中。在普通的全连接网络或CNN中,每层神经元的信号只能向上一层传播,样本的处理在各个时刻独立,因此又被成为前向神经网络(Feed-forward Neural Networks)。
2.5 RNN(循环神经网络)的出现
全连接的DNN还存在着另一个问题——无法对时间序列上的变化进行建模。然而,样本出现的时间顺序对于自然语言处理、语音识别、手写体识别等应用非常重要。对了适应这种需求,就出现了另一种神经网络结构——循环神经网络RNN。而在RNN中,神经元的输出可以在下一个时间戳直接作用到自身,即第i层神经元在m时刻的输入,除了(i−1)层神经元在该时刻的输出外,还包括其自身在(m−1)时刻的输出。
RNN可以看成一个在时间上传递的神经网络,它的深度是时间的长度!正如我们上面所说,“梯度消失”现象又要出现了,只不过这次发生在时间轴上。对于t时刻来说,它产生的梯度在时间轴上向历史传播几层之后就消失了,根本就无法影响太遥远的过去。因此,之前说“所有历史”共同作用只是理想的情况,在实际中,这种影响也就只能维持若干个时间戳。为了解决时间上的梯度消失,机器学习领域发展出了长短时记忆单元 LSTM,通过门的开关实现时间上记忆功能,并防止梯度消失
3 结束语
事实上,不论是那种网络,他们在实际应用中常常都混合着使用,比如CNN和RNN在上层输出之前往往会接上全连接层,很难说某个网络到底属于哪个类别。不难想象随着深度学习热度的延续,更灵活的组合方式、更多的网络结构将被发展出来。尽管看起来千变万化,但研究者们的出发点肯定都是为了解决特定的问题。对于想进行这方面的研究的朋友,不妨仔细分析一下这些结构各自的特点以及它们达成目标的手段。入门的话可以参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号