莫烦PyTorch学习笔记(五)——分类
import torch from torch.autograd import Variable import torch.nn.functional as F import matplotlib.pyplot as plt # make fake data n_data = torch.ones(100, 2) x0 = torch.normal(2*n_data, 1) #每个元素(x,y)是从 均值=2*n_data中对应位置的取值,标准差为1的正态分布中随机生成的 y0 = torch.zeros(100) # 给每个元素一个0标签 x1 = torch.normal(-2*n_data, 1) # 每个元素(x,y)是从 均值=-2*n_data中对应位置的取值,标准差为1的正态分布中随机生成的 y1 = torch.ones(100) # 给每个元素一个1标签 x = torch.cat((x0, x1), 0).type(torch.FloatTensor) # shape (200, 2) FloatTensor = 32-bit floating y = torch.cat((y0, y1), ).type(torch.LongTensor) # shape (200,) LongTensor = 64-bit integer # torch can only train on Variable, so convert them to Variable x, y = Variable(x), Variable(y) # draw the data plt.scatter(x.data.numpy()[:, 0], x.data.numpy()[:, 1], c=y.data.numpy())#c是一个颜色序列 #plt.show() #神经网络模块 class Net(torch.nn.Module):#继承神经网络模块 def __init__(self,n_features,n_hidden,n_output):#初始化神经网络的超参数 super(Net,self).__init__()#调用父类神经网络模块的初始化方法,上面三行固定步骤,不用深究 self.hidden = torch.nn.Linear(n_features,n_hidden)#指定隐藏层有多少输入,多少输出 self.predict = torch.nn.Linear(n_hidden, n_output)#指定预测层有多少输入,多少输出 def forward(self,x):#搭建神经网络 x = F.relu(self.hidden(x))#积极函数激活加工经过隐藏层的x x = self.predict(x)#隐藏层的数据经过预测层得到预测结果 return x net = Net(2,10,2)#声明一个类对象 print(net) plt.ion()#在Plt.ion和plt.ioff之间的代码,交互绘图 plt.show() #神经网络优化器,主要是为了优化我们的神经网络,使他在我们的训练过程中快起来,节省社交网络训练的时间。 optimizer = torch.optim.SGD(net.parameters(),lr = 0.01)#其实就是神经网络的反向传播,第一个参数是更新权重等参数,第二个对应的是学习率 loss_func = torch.nn.CrossEntropyLoss()#标签误差代价函数 for t in range(50): out = net(x) loss = loss_func(out,y)#计算损失 optimizer.zero_grad()#梯度置零 loss.backward()#反向传播 optimizer.step()#计算结点梯度并优化, if t % 2 == 0: plt.cla()# Clear axis即清除当前图形中的之前的轨迹 prediction = torch.max(F.softmax(out), 1)[1]#转换为概率,后面的一是最大值索引,如果为0则返回最大值 pred_y = prediction.data.numpy().squeeze() target_y = y.data.numpy() plt.scatter(x.data.numpy()[:, 0], x.data.numpy()[:, 1], c=pred_y, s=100, lw=0, cmap='RdYlGn') accuracy = sum(pred_y == target_y) / 200.#求准确率 plt.text(1.5, -4, 'Accuracy=%.2f' % accuracy, fontdict={'size': 20, 'color': 'red'}) plt.pause(0.1) plt.ioff() plt.show()
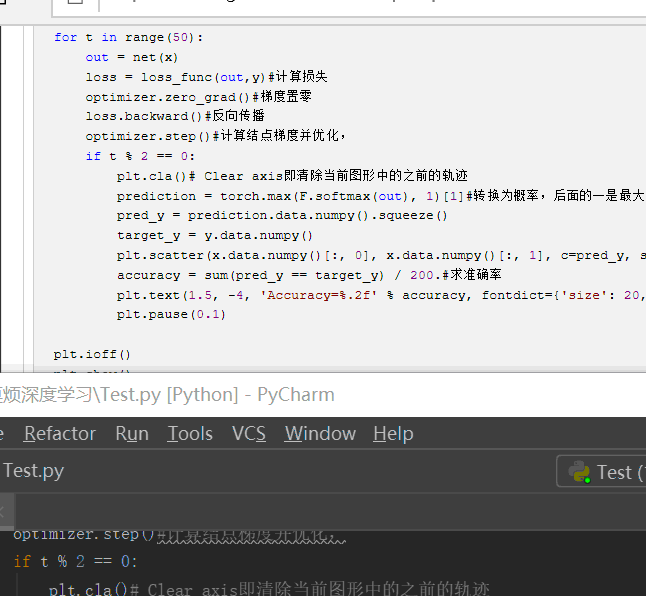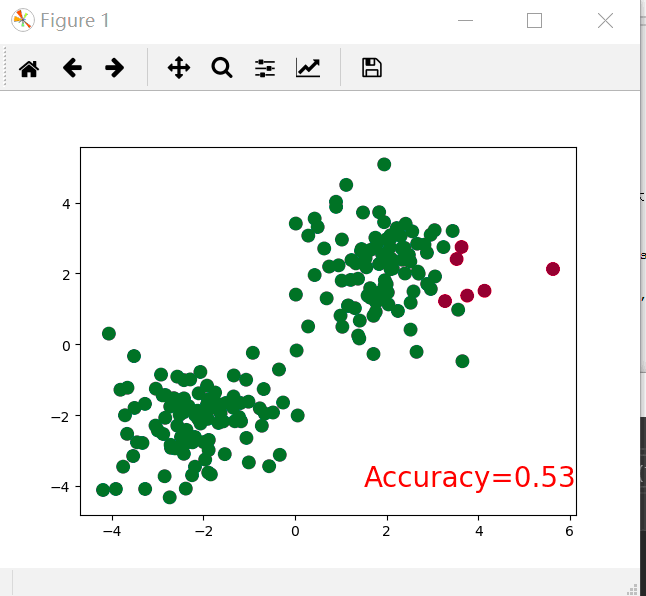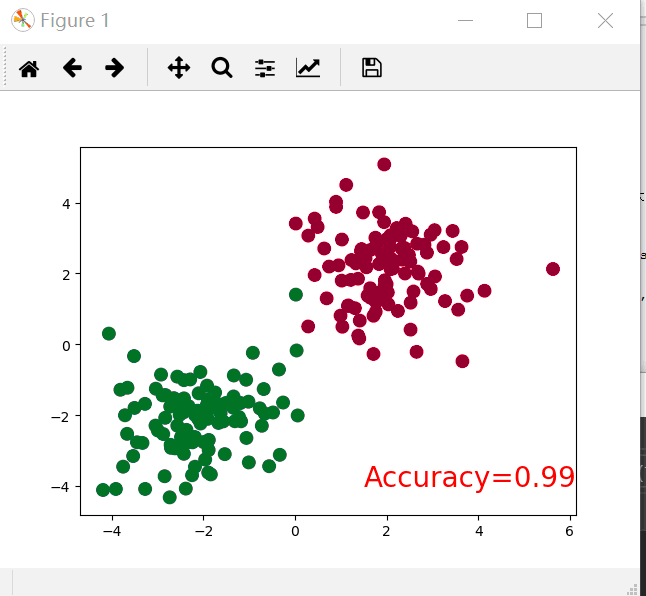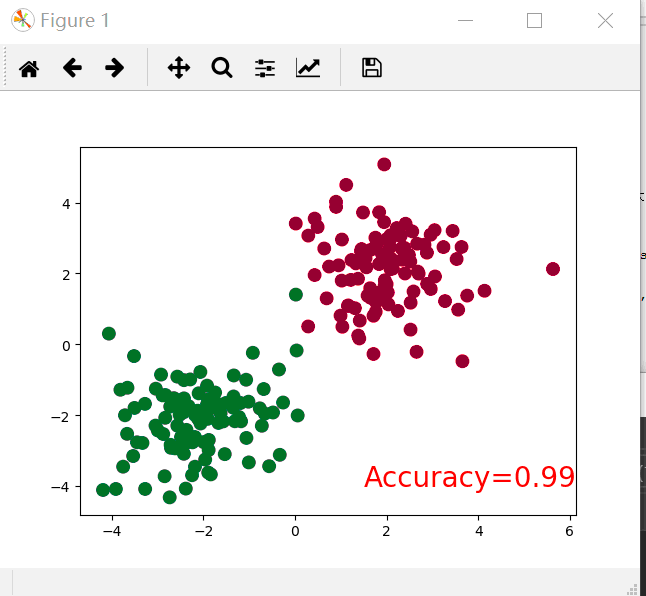
下面的是一个比较快搭建神经网络的代码,在上面的代码进行修改,代码如下
import torch from torch.autograd import Variable import torch.nn.functional as F import matplotlib.pyplot as plt # make fake data n_data = torch.ones(100, 2) x0 = torch.normal(2*n_data, 1) #每个元素(x,y)是从 均值=2*n_data中对应位置的取值,标准差为1的正态分布中随机生成的 y0 = torch.zeros(100) # 给每个元素一个0标签 x1 = torch.normal(-2*n_data, 1) # 每个元素(x,y)是从 均值=-2*n_data中对应位置的取值,标准差为1的正态分布中随机生成的 y1 = torch.ones(100) # 给每个元素一个1标签 x = torch.cat((x0, x1), 0).type(torch.FloatTensor) # shape (200, 2) FloatTensor = 32-bit floating y = torch.cat((y0, y1), ).type(torch.LongTensor) # shape (200,) LongTensor = 64-bit integer # torch can only train on Variable, so convert them to Variable x, y = Variable(x), Variable(y) # draw the data plt.scatter(x.data.numpy()[:, 0], x.data.numpy()[:, 1], c=y.data.numpy())#c是一个颜色序列 #plt.show() #神经网络模块 net2 = torch.nn.Sequential( torch.nn.Linear(2,10), torch.nn.ReLU(), torch.nn.Linear(10,2) ) plt.ion()#在Plt.ion和plt.ioff之间的代码,交互绘图 plt.show() #神经网络优化器,主要是为了优化我们的神经网络,使他在我们的训练过程中快起来,节省社交网络训练的时间。 optimizer = torch.optim.SGD(net.parameters(),lr = 0.01)#其实就是神经网络的反向传播,第一个参数是更新权重等参数,第二个对应的是学习率 loss_func = torch.nn.CrossEntropyLoss()#标签误差代价函数 for t in range(50): out = net(x) loss = loss_func(out,y)#计算损失 optimizer.zero_grad()#梯度置零 loss.backward()#反向传播 optimizer.step()#计算结点梯度并优化, if t % 2 == 0: plt.cla()# Clear axis即清除当前图形中的之前的轨迹 prediction = torch.max(F.softmax(out), 1)[1]#转换为概率,后面的一是最大值索引,如果为0则返回最大值 pred_y = prediction.data.numpy().squeeze() target_y = y.data.numpy() plt.scatter(x.data.numpy()[:, 0], x.data.numpy()[:, 1], c=pred_y, s=100, lw=0, cmap='RdYlGn') accuracy = sum(pred_y == target_y) / 200.#求准确率 plt.text(1.5, -4, 'Accuracy=%.2f' % accuracy, fontdict={'size': 20, 'color': 'red'}) plt.pause(0.1) plt.ioff() plt.show()
作者:你的雷哥
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须在文章页面给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号