吴恩达《机器学习》课程总结(18)_照片OCR
18.1问题描述和流程图
(1)图像文字识别是从给定的一张图片中识别文字。
(2)流程包括:
1.文字侦测
2.字符切分(现在不需要切分了)
3.字符分类

18.2滑动窗口
在行人检测中,滑动窗口是首先训练一个固定尺寸输入的判断是否有行人的网络,然后在一张图片中裁该尺寸的图片,送入到网络中;然后不断移动裁剪区,重复以上过程,知道裁剪到最后,这时按比例放大裁剪区,然后将裁剪到的图片缩放到网络的输入,如此循环。
首先滑动窗口同样用于文字识别,做字符与非字符区分,然后把字符区域适当扩展,然后合并重叠区域,按照高宽比进行过滤(认为长度大于高度),如下图所示:

然后进行文字的分割,通用训练一个模型,数据集如下:

分割出单个字符之后,利用神经网络、支持向量机或者逻辑回归训练一个分类器即可。
18.3获取大量数据和人工数据
(1)从网上下载字体,然后随机添加跟着背景创造实例;
(2)利用已有数据进行旋转、扭曲、模糊处理等产生新数据;
有关获取更多数据的方法:
(1)人工数据合成;
(2)手动收集、标记数据;
(3)众包;
18.4上限分析:哪部分管道该接下去做
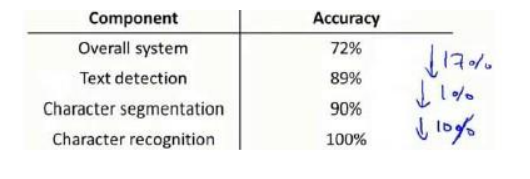
如下下面的流程中,本来正确率为72%,如果提供完全正确的文字检测作为文字分割的输入,发现系统正确率提升到了89%,说明要下功夫在文字检测上了。

下表是每一步如果完全正确,会带来多大的提升,如果提升越大,说明越要花功夫在这一步上。下表首先要花功夫在文字检测上,然后是文字识别,而文字分割已经做得很好了。
作者:你的雷哥
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须在文章页面给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号